标签:spec 产生 city 调整 曲线 比例 评估 综合 描述
混淆矩阵是一种用于性能评估的方便工具,它是一个方阵,里面的列和行存放的是样本的实际类vs预测类的数量。
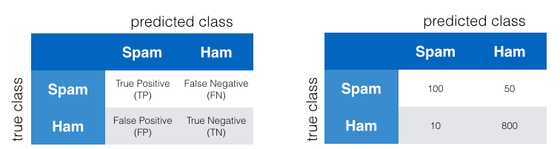
P =阳性,N =阴性:指的是预测结果。
T=真,F=假:表示 实际结果与预测结果是否一致,一致为真,不一致为假。
TP=真阳性:预测结果为P,且实际与预测一致。
FP=假阳性:预测结果为P,但与实际不一致。
TN=真阴性:预测结果为N,且与实际一致。
FN=假阴性:预测结果为N,但与实际不一致。
分类模型的经验误差可以通过计算1-准确率得到。
然而,如何选择一个适当的预测误差度量是高度依赖于具体问题的。在“垃圾邮件”分类的情况中,我们更加关注的是低误报率。当然,垃圾邮件被分成了火腿肯定是烦人的,但不是那么糟糕。要是一封邮件被误分为垃圾邮件,而导致重要信息丢失,那才是更糟糕的呢。
在如“垃圾邮件”分类的二元分类问题中,有一种方便的方式来调整分类器,称为接受者操作特性(ROC或ROC曲线)。该曲线对应精密性Precision,对应着预测值为阳性的数据中正确的比例。
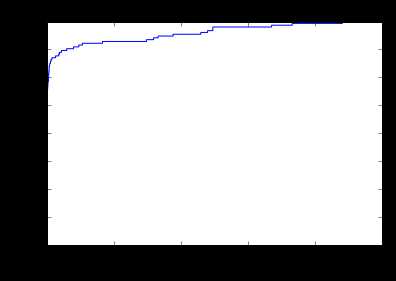
AUC的含义:ROC曲线下的面积(越大越好,1为理想状态)
ROC(Receiver Operating Characteristic)
准确率Accuracy
正确分类的样本占总样本的比例,对总体准确率的评估。
公式:(TP+TN)/(P+N)。即,对阳性和阴性,总体(分母P+N)预测对了多少(分子TP+TN)。
注:准确率是我们最常见的评价指标,而且很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。
准确率确实是一个很好很直观的评价指标,但是有时候准确率高并不能代表一个算法就好。比如某个地区某天地震的预测,假设我们有一堆的特征作为地震分类的属性,类别只有两个:0:不发生地震、1:发生地震。一个不加思考的分类器,对每一个测试用例都将类别划分为0,那那么它就可能达到99%的准确率,但真的地震来临时,这个分类器毫无察觉,这个分类带来的损失是巨大的。为什么99%的准确率的分类器却不是我们想要的,因为这里数据分布不均衡,类别1的数据太少,完全错分类别1依然可以达到很高的准确率却忽视了我们关注的东西。再举个例子说明下。在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc也有 99% 以上,没有意义。因此,单纯靠准确率来评价一个算法模型是远远不够科学全面的。
错误率(Error rate)
错误率则与准确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(TP+TN+FP+FN),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate。
灵敏度Sensitivity(查全率/召回率Recall)
对“真阳性率”预测的评估,也就是对“阳性/真”预测准确的概率(比如,当试图预测某种疾病的时候,如果一个病人长了这种病,那么正确的预测出这个人长了这种病,就是“阳性/真”)。
查全率关心的是”预测出正例的保证性”即从正例中挑选出正例的问题。
灵敏度表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。召回率是覆盖面的度量,度量有多个正例被分为正例,与灵敏度相等。
公式:TP/(TP+FN)。即,实际为阳性P(分母TP+FN),其中预测正确的比例(分子TP)。
精密性(精确率/精度/查准率)Precision
对“真阳性率”预测的评估。
查准率关心的是”预测出正例的正确率”即从正反例子中挑选出正例的问题。
表示被分为正例的示例中实际为正例的比例。
公式:TP/(TP+FP)。即,预测为阳性的数据(分母TP+FP)中,实际对了多少(分子TP)。
特异性Specificity
描述了二元分类问题中的“真阴性率”:这指的是对“真/阴性”情况作出正确预测的概率(例如,在试图预测疾病时,对一个健康者,没有预测到疾病,就是这种情况)。
表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力。
公式:TN/(TN+FP)。即,实际为阴性N(分母TN+FP),其中预测正确的比例(分子TN)。
综合评价指标(F-Measure)
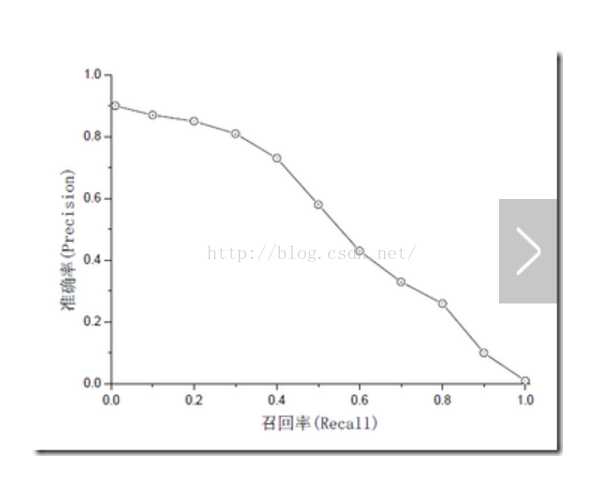
灵敏度Sensitivity(查全率/召回率Recall)与精密性(精确率、精度)Precision这两个指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。两者一般存在矛盾关系,不能都达到很高的值,所以定义F-score评价综合标准。如下图,查准率-查全率曲线(P-R图):
F-Measure是Precision(P)和Recall(R)加权调和平均:
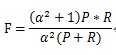
当参数α=1时,就是最常见的F1,也即
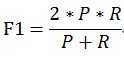
可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
其他评价指标
计算速度:分类器训练和预测需要的时间;
鲁棒性:处理缺失值和异常值的能力;
可扩展性:处理大数据集的能力;
可解释性:分类器的预测标准的可理解性,像决策树产生的规则就是很容易理解的,而神经网络的一堆参数就不好理解,我们只好把它看成一个黑盒子。
标签:spec 产生 city 调整 曲线 比例 评估 综合 描述
原文地址:https://www.cnblogs.com/xianhan/p/9277194.html