标签:特点 订阅 exchange 分表 划算 用户名 consumer 分布 生产者消费者模型
消息队列已经逐渐成为企业IT系统内部通信的核心手段。它具有低耦合、可靠投递、广播、流量控制、最终一致性等一系列功能,成为异步RPC的主要手段之一。
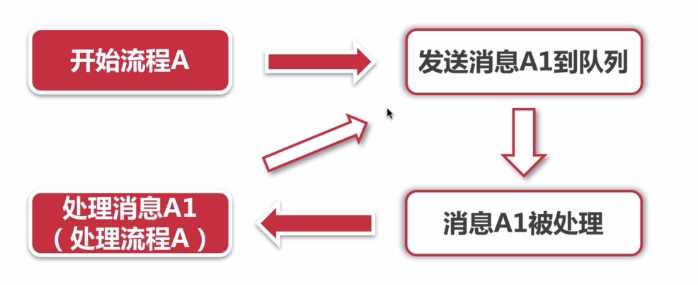
消息被处理的过程相当于流程A被处理。我们这里以一个实际的模型来讨论下,比如用户下单成功时给用户发短信,如果没有这个消息队列,我们会选择同步调用发短信的接口,
并等待短息发送成功,这时候假设短信接口实现出现问题了,或者短信调用端超时了,又或者短信发送达到上限了,我们是选择重试几次还是放弃,还是选择把这个放到数据库
过一段时间再看看呢,不管怎样,实现都很复杂。
我们可以将发短信这个请求放在消息队列里,消息队列按照一定的顺序挨个处理队列里的消息,当处理到发送短信的任务时,通知短信服务发送消息,如果出现之前出现的问题,那么把这个消息重新放到消息队列中。
消息队列的好处:
1.成功完成了一个异步解耦的过程。短信发送时只要保证放到消息队列中就可以了,接着做后面的事情就行。一个事务只关心本质的流程,需要依赖其他事情但是不那么重要的时候,有通知即可,无需等待结果。每个成员不必受其他成员影响,可以更独立自主,只通过一个简单的容器来联系。
对于我们的订单系统,订单最终支付成功之后可能需要给用户发送短信积分什么的,但其实这已经不是我们系统的核心流程了。如果外部系统速度偏慢(比如短信网关速度不好),那么主流程的时间会加长很多,用户肯定不希望点击支付过好几分钟才看到结果。那么我们只需要通知短信系统“我们支付成功了”,不一定非要等待它处理完成。
2.保证了最终一致性,通过在队列中存放任务保证它最终一定会执行。
最终一致性指的是两个系统的状态保持一致,要么都成功,要么都失败。当然有个时间限制,理论上越快越好,但实际上在各种异常的情况下,可能会有一定延迟达到最终一致状态,但最后两个系统的状态是一样的。
业界有一些为“最终一致性”而生的消息队列,如Notify(阿里)、QMQ(去哪儿)等,其设计初衷,就是为了交易系统中的高可靠通知。
以一个银行的转账过程来理解最终一致性,转账的需求很简单,如果A系统扣钱成功,则B系统加钱一定成功。反之则一起回滚,像什么都没发生一样。
然而,这个过程中存在很多可能的意外:
可见,想把这件看似简单的事真正做成,真的不那么容易。所有跨VM的一致性问题,从技术的角度讲通用的解决方案是:
消息队列的基本功能之一是进行广播。如果没有消息队列,每当一个新的业务方接入,我们都要联调一次新接口。有了消息队列,我们只需要关心消息是否送达了队列,至于谁希望订阅,是下游的事情,无疑极大地减少了开发和联调的工作量。
3.提速。假设我们还需要发送邮件,有了消息队列就不需要同步等待,我们可以直接并行处理,而下单核心任务可以更快完成。增强业务系统的异步处理能力。甚至几乎不可能出现并发现象。
4.削峰和流控。不对于不需要实时处理的请求来说,当并发量特别大的时候,可以先在消息队列中作缓存,然后陆续发送给对应的服务去处理
试想上下游对于事情的处理能力是不同的。比如,Web前端每秒承受上千万的请求,并不是什么神奇的事情,只需要加多一点机器,再搭建一些LVS负载均衡设备和Nginx等即可。但数据库的处理能力却十分有限,即使使用SSD加分库分表,单机的处理能力仍然在万级。由于成本的考虑,我们不能奢求数据库的机器数量追上前端。
这种问题同样存在于系统和系统之间,如短信系统可能由于短板效应,速度卡在网关上(每秒几百次请求),跟前端的并发量不是一个数量级。但用户晚上个半分钟左右收到短信,一般是不会有太大问题的。如果没有消息队列,两个系统之间通过协商、滑动窗口等复杂的方案也不是说不能实现。但系统复杂性指数级增长,势必在上游或者下游做存储,并且要处理定时、拥塞等一系列问题。而且每当有处理能力有差距的时候,都需要单独开发一套逻辑来维护这套逻辑。所以,利用中间系统转储两个系统的通信内容,并在下游系统有能力处理这些消息的时候,再处理这些消息,是一套相对较通用的方式。
总而言之,消息队列不是万能的。对于需要强事务保证而且延迟敏感的,RPC是优于消息队列的。
对于一些无关痛痒,或者对于别人非常重要但是对于自己不是那么关心的事情,可以利用消息队列去做。
支持最终一致性的消息队列,能够用来处理延迟不那么敏感的“分布式事务”场景,而且相对于笨重的分布式事务,可能是更优的处理方式。
当上下游系统处理能力存在差距的时候,利用消息队列做一个通用的“漏斗”。在下游有能力处理的时候,再进行分发。
如果下游有很多系统关心你的系统发出的通知的时候,果断地使用消息队列吧。
消息队列的使用场景:
主要特点是异步处理,主要目的是减少请求响应时间和解耦。所以主要的使用场景就是将比较耗时而且不需要即时(同步)返回结果的操作作为消息放入消息队列。
但是对于用户来说,注册功能实际只需要第一步,只要服务端将他的账户信息存到数据库中他便可以登录上去做他想做的事情了。至于其他的事情,非要在这一次请求中全部完成么?值得用户浪费时间等你处理这些对他来说无关紧要的事情么?所以实际当第一步做完后,服务端就可以把其他的操作放入对应的消息队列中然后马上返回用户结果,由消息队列异步的进行这些操作。
或者还有一种情况,同时有大量用户注册你的软件,再高并发情况下注册请求开始出现一些问题,例如邮件接口承受不住,或是分析信息时的大量计算使cpu满载,这将会出现虽然用户数据记录很快的添加到数据库中了,但是却卡在发邮件或分析信息时的情况,导致请求的响应时间大幅增长,甚至出现超时,这就有点不划算了。面对这种情况一般也是将这些操作放入消息队列(生产者消费者模型),消息队列慢慢的进行处理,同时可以很快的完成注册请求,不会影响用户使用其他功能。

为什么需要消息队列?
生产和消费的速度或者稳定性不一致。
当今市面上有很多主流的消息中间件,如老牌的ActiveMQ、RabbitMQ,炙手可热的Kafka,阿里巴巴自主开发的Notify、MetaQ、RocketMQ等。
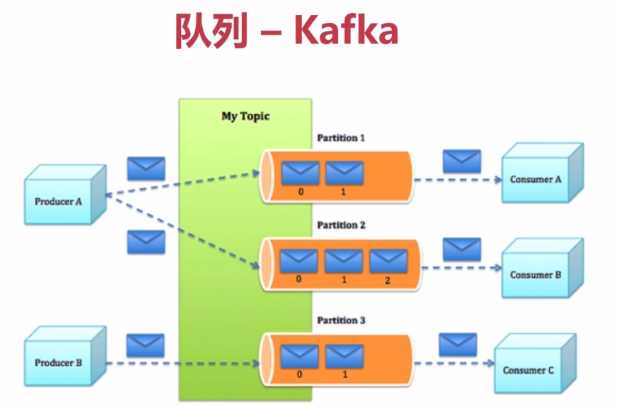
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
Kafka 有如下特性:
标签:特点 订阅 exchange 分表 划算 用户名 consumer 分布 生产者消费者模型
原文地址:https://www.cnblogs.com/xiangkejin/p/9278356.html