标签:二分 重要 混淆 ima body 技术分享 error 1.0 margin
对于分类模型的评价指标主要有错误率 、准确率、查准率、查全率、混淆矩阵、F1值、AUC和ROC。
错误率(Error rate):通常把分类错误的样本数占总样本总数的比例称为“错误率”。
准确率(Accuracy):是指分类正确的样本数占样本总数的比例,即准确率=1-错误率。
查准率(Precision):又称精确率,预测为正例的样本中,真正为正例的比率。
查全率(Recall):又称召回率,预测为正例的真实正例(TP)占所有真实正例的比例。
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为以下四种情形:
真正例(true position):将一个正例正确判断为一个正例
假正例(false position):将一个反例错误判断为一个正例
真反例(true negative):将一个反例正确判断为一个反例
假反例(false negative):将一个正例错误判断为一个反例
令TP、FP、TN、FN分别表示其对应的样例数,则显然有TP+FP+TN+FN=样例总数,分类结果的“混淆矩阵”如表1所示。
表1 分类结果混淆矩阵
|
真实情况 |
预测结果 |
|
|
正例 |
反例 |
|
|
正例 |
TP(真正例) |
FN(假反例) |
|
反例 |
FP(假正例) |
TN(真反例) |
则查准率P和查全率R分别定义为
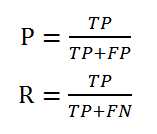
查准率和查全率是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
F1值是基于查准率和查全率的调和平均定义的:
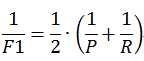
则
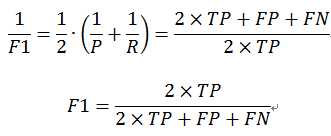
度量的一般形式——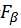 ,是加权调和平均,能表达出对查准率和查全率的不同偏好,它定义为
,是加权调和平均,能表达出对查准率和查全率的不同偏好,它定义为
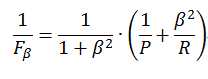
其中,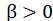 度量了查全率对查准率的相对重要性;
度量了查全率对查准率的相对重要性;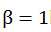 时退化为标准的F1,
时退化为标准的F1,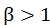 时查全率有更大影响;
时查全率有更大影响;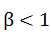 时查准率有更大影响。
时查准率有更大影响。
ROC全称是“受试者工作特征”(Receiver Operating Characteristic)曲线,ROC曲线的横轴为“假正例率”(False Positive Rate,简称FPR),纵轴为“真正例率”(True Positive Rate,简称TPR),基于表2.1中的符号,定义为
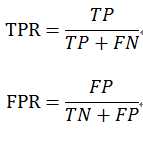
AUC(Area Under ROC Curve),AUC可通过对ROC曲线下方的面积求和而得。这个面积通常是大于等于0.5,小于等于1.0的。AUC的值越大越好。AUC用于衡量“二分类问题”机器学习算法性能(泛化能力)。下图为ROC曲线和AUC之间的关系。
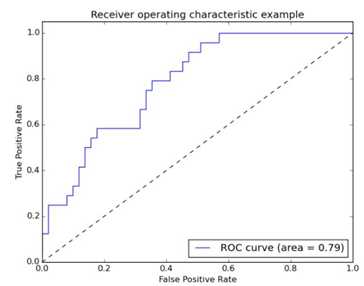
接下来我们考虑ROC曲线图中的四个点和一条线。
第一个点,(0,1),即左上角的点,在这个点意味着FPR=0,TPR=1,即负类样本中被判断为正类的比例为0,说明负类样本都被判断为负类,判断正确,正类样本中被判断为正类的比例为1,说明正类样本都被判断正确,所以这是一个完美的分类器,它将所有的样本都正确分类。
第二个点,(1,0),即右下角的点,在这个点意味着FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确分类。把该判断为正类的判断为负类,把该判断为负类的判断为正类
第三个点,(0,0),即左下角的点,在这个点意味着FPR=TPR=0,可以发现该分类器预测所有的样本都为负样本(negative),这种情况说明阈值选得过高。
第四个点(1,1),即右下角的点,分类器实际上预测所有的样本都为正样本,这种情况说明阈值选得过低。
用以上两个指标来判断模型是否好坏。但是,有时候模型没有单纯的谁比谁好,选择模型还是要结合具体的使用场景。
比如,地震的预测,我们肯定是希望recall分厂高咯,也就是说我们希望把每次地震都预测出来,这个时候可以牺牲掉查准率,宁愿发出成百上千次警告,也要把10次地震都给预测正确,也不要预测100次对了8次而漏掉两次。
再比如,嫌疑人定罪,我们基于不要错怪一个好人的原则,因此我们希望对于嫌疑人定罪是非常准确的,即使有些时候放过一些罪犯(recall低),但也是值得的。
标签:二分 重要 混淆 ima body 技术分享 error 1.0 margin
原文地址:https://www.cnblogs.com/Amy9/p/8870795.html