标签:去除空格 .com 文本 效率 src strong replace work 中间
前段时间参加了Kaggle上的Mercari Price Suggestion Challenge比赛,收获良多,过些时候准备进行一些全面的总结,本篇文章先谈一个比赛中用到的小技巧。
这个比赛数据中有一个特征叫做 "item_description",大致是一些商品描述,比如什么时候买的、新旧程度如何、什么牌子的等等。因为大部分都是Mercari这个网站(这个类似于国内的二手商品交易网站)上的用户自己填的商品描述,所以是极尽杂乱之能事,会出现很多夸张的符号,比如这样:
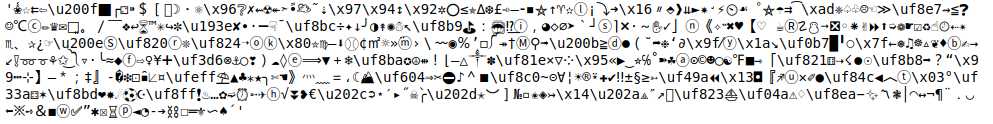
另外的一大问题是用语规范不统一,比如 $1.100 和 $1.1 其实是一个意思,然而在对文本进行特征提取时就会被当成两个特征,这会使特征变得过于稀疏,对模型的效果也会产生影响。所幸Pandas中提供了str.replace()这个方法,可以高效处理此类问题。
str.replace()的作用基本与re.sub()等同,区别在于re.sub()一次只能处理一个字符串,而str.replace()可以一次处理一整个Series,因而效率要高很多。str.replace()的正式形式为 Series.str.replace(pat, repl) ,其中pat为想要寻找的模式,一般为正则表达式,repl为要替换进去的字符串或函数。
下面是几个简单的例子,X代表一个Series,repl皆为字符串:
X.str.replace(r"iphone\s+7", "iphone7") #为了将iphone7视为一个词,把iphone 7转换为iphone7,去除空格。
X.str.replace(r"16gbiphone", "16gb iphone") #将16gbiphone转换无16gb iphone,增加空格。
X.str.replace(r"fl\s?\.?\s?oz", "floz") #将fl.oz或fl . oz转换为floz如果是一些比较复杂的情况,则需要将repl自定义为函数:
1) 将1.101000变为1.101,即将后面的"0"去掉。
remove0 = lambda m:m.group(0).rstrip("0")
X.str.replace(r"\d\.\d*[1-9]+0+", remove0)上例中将repl定义为一个匿名函数,m.group(0)为匹配到的所有字符串,注意其不会匹配到1.000的情况,因为pat中存在[1-9]。
2) 将1.000kg变为1kg,这里因为要去除的.和0两个字符位于中间,所以无法用上面的rstrip()。
table1 = str.maketrans("","","0.")
remove1 = lambda m:m.group(0).translate(table1)
X.str.replace(r"\.0+[a-z]+", remove1)上例中使用str.maketrans()方法指定想要删除的字符,再用translate()删除。这是python 3的写法,python 2中可直接使用translate():
# python 2
remove1 = lambda m:m.group(0).translate(None,"0.")
X.str.replace(r"\.0+[a-z]+", remove1)3) 将0.0300kg转换为0.03kg。这里由于0.03本身存在0,所以不能用str.maketrans()了,因为会将所有0都删除。所以这里用两个正则表达式分别找到0.03和kg,再拼接起来:
def remove2(data):
al1 = re.findall(r"\d+\.\d*[1-9]+0+",data.group(0))
al2 = re.findall(r"[a-z]+",data.group(0))
return al1[0].rstrip("0") + al2[0]
X.str.replace(r"\d+\.\d*[1-9]+0+[a-z]+", remove2)4) 将1.100%转换为1 100%, 这么做的目的是1.100%可能会被转换为一个词,而实际想要提取的肯定只有100%:
def remove3(data):
al1 = re.findall(r"\d+(?=\.)", data.group(0)) # 这里使用了零宽断言(?=),是为了去除”.“
al2 = re.findall(r"100%", data.group(0))
return al1[0]+" "+al2[0]
X.str.replace(r"\d+\.100%", remove3) 5) 商品中有很多衣服鞋子之类的,一般都标有尺码,比如3",15”等。这里要把后面的尺码符号‘ ” ’提取出来并用“colon”表示,让模型识别出前面的数字3和15是代表尺码大小。
def findcolon(data):
al1 = re.findall(r‘\d{1,2}\.\d{1,3}|\d{1,2}|1\d{2}‘, data.group(0))
return al1[0]+" colon "
X.str.replace(r‘(?:\d{1,2}\.\d{1,3}|\d{1,2}|1\d{2})(?:\s?\")‘, findcolon) # 匹配2.3“, 55", 132"等,转换为2.3 colon由此,本文结合比赛中的例子介绍了几种清洗文本的方法,另外Pandas中还提供了其他很多有用的处理文本的方法,详见文档 Working with Text Data 。
/
使用Pandas: str.replace() 进行文本清洗
标签:去除空格 .com 文本 效率 src strong replace work 中间
原文地址:https://www.cnblogs.com/massquantity/p/9280905.html