标签:out 最小 img 存储位置 数据流 操作 取数据 实例 博客
博客内容来自我啃的Hadoop权威指南,记录一下帮助自己理一下思路
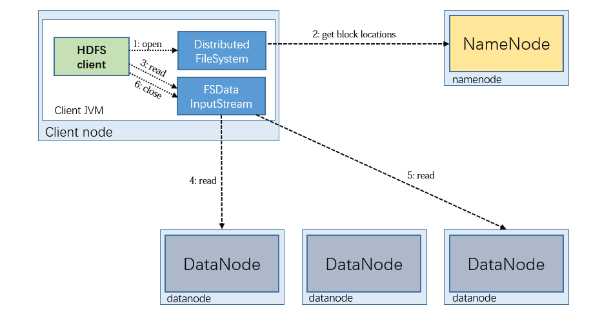
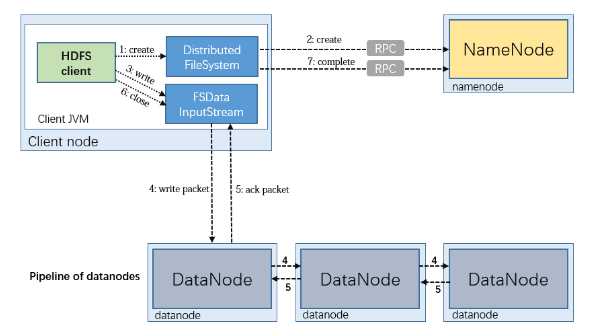
HDFS中的数据流
原文地址:https://www.cnblogs.com/frankxx/p/9280764.html