标签:passing word2vec rop 观察 方差 答案 embedding most Dimension
tf.nn.nce_loss是word2vec的skip-gram模型的负例采样方式的函数,下面分析其源代码。
loss = tf.reduce_mean(
tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases,
labels=train_labels,
inputs=embed,
num_sampled=num_sampled,
num_classes=vocabulary_size))
其中,
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
train_inputs中的就是中心词,train_label中的就是语料库中该中心词在滑动窗口内的上下文词。
所以,train_inputs中会有连续n-1(n为滑动窗口大小)个元素是相同的。即同一中心词。
embddings是词嵌入,就是要学习的词向量的存储矩阵。共有词汇表大小的行数,每一行对应一个词的向量。
# Construct the variables for the NCE loss
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
nce_weights就是用来存储如下负例采样公式中的![]()
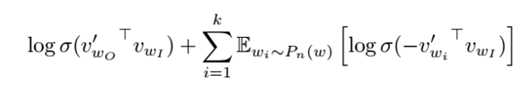 、
、
sigmoid函数有一个对称特性:

故而上面的公式中,就没有出现1-XX的形式。用1-XX的形式,可能会更好理解。
具体解释如下:
def nce_loss(weights,
biases,
labels,
inputs,
num_sampled,
num_classes,
num_true=1,
sampled_values=None,
remove_accidental_hits=False,
partition_strategy="mod",
name="nce_loss"):
logits, labels = _compute_sampled_logits(
weights=weights,
biases=biases,
labels=labels,
inputs=inputs,
num_sampled=num_sampled,
num_classes=num_classes,
num_true=num_true,
sampled_values=sampled_values,
subtract_log_q=True,
remove_accidental_hits=remove_accidental_hits,
partition_strategy=partition_strategy,
name=name)
sampled_losses = sigmoid_cross_entropy_with_logits(
labels=labels, logits=logits, name="sampled_losses")
# sampled_losses is batch_size x {true_loss, sampled_losses...}
# We sum out true and sampled losses.
return _sum_rows(sampled_losses)
可以看出核心就在于传入sigmoid_cross_entropy_with_logits的参数。对于任何一个输出节点只有一个的二分类神经网络,用sigmoid_cross_entropy_with_logits是最好理解的。logits的维度是batch_size,1。labels的维度就是batch_size,元素取值为0或者1,
来看一下sigmoid_cross_entropy_with_logits函数
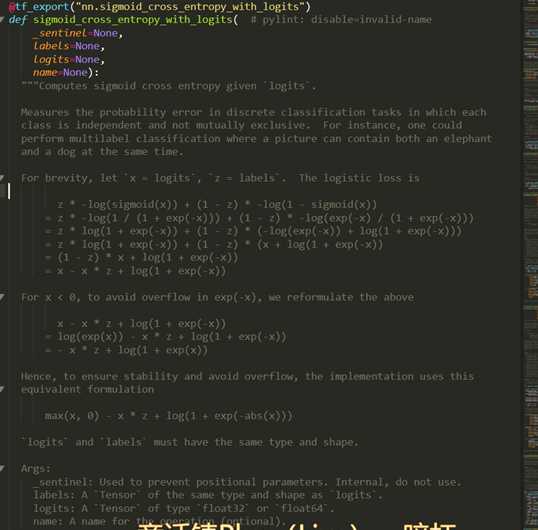
sigmoid_cross_entropy_with_logits的返回值是:
Returns:
A `Tensor` of the same shape as `logits` with the componentwise
logistic losses.
也就是说:logits的维度是batch_size,1,其返回的维度也是batch_size,1。这个位置的元素就是用这个公式计算的loss:

但是在负例采样中,传入的logits的维度不是batch_size,1,而是[batch_size, num_true + num_sampled]`。主要观察一下_compute_sampled_logits函数的输出。其输出如下:
Returns:
out_logits: `Tensor` object with shape
`[batch_size, num_true + num_sampled]`, for passing to either
`nn.sigmoid_cross_entropy_with_logits` (NCE) or
`nn.softmax_cross_entropy_with_logits` (sampled softmax).
out_labels: A Tensor object with the same shape as `out_logits`.
"""
其传入参数的解释是:
labels: A `Tensor` of type `int64` and shape `[batch_size,
num_true]`. The target classes. Note that this format differs from
the `labels` argument of `nn.softmax_cross_entropy_with_logits`.
inputs: A `Tensor` of shape `[batch_size, dim]`. The forward
activations of the input network.
weights: A `Tensor` of shape `[num_classes, dim]`, or a list of `Tensor`
objects whose concatenation along dimension 0 has shape
`[num_classes, dim]`. The (possibly-partitioned) class embeddings.
可以看出_compute_sampled_logits完成的是一个什么过程呢。就是对于每一个样本,计算出一个维度为[batch_size, num_true + num_sampled]的向量,向量的每个元素都同之前logits的每个元素的意义一样,是输出值。同时,返回一个维度为[batch_size, num_true + num_sampled]的向量labels。这个labels中只有一个元素为1。于是再看一下如下公式:
其实,此时的out_logits中对应(label位置为0)的元素就是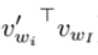 ,对应label位置为1)的元素就是
,对应label位置为1)的元素就是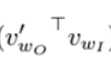 。
。
然后再传给sigmoid_cross_entropy_with_logits,同样是对于每个元素位置的计算使用下面的公式:

所以,nce_loss中调用sigmoid_cross_entropy_with_logits后返回的是:[batch_size, num_true + num_sampled]的向量,其中每个元素都是一个用上述公式计算出loss。
nce_loss的最后一步是_sum_rows:
def _sum_rows(x): """Returns a vector summing up each row of the matrix x.""" # _sum_rows(x) is equivalent to math_ops.reduce_sum(x, 1) when x is # a matrix. The gradient of _sum_rows(x) is more efficient than # reduce_sum(x, 1)‘s gradient in today‘s implementation. Therefore, # we use _sum_rows(x) in the nce_loss() computation since the loss # is mostly used for training. cols = array_ops.shape(x)[1] ones_shape = array_ops.stack([cols, 1]) ones = array_ops.ones(ones_shape, x.dtype) return array_ops.reshape(math_ops.matmul(x, ones), [-1])
最后,再对nce_loss的返回结果用reduce_mean即可计算一个batch的平均损失。
关于_compute_sampled_logits中如何采样,如何计算的,这里就不再阐述,同文字理论是一样的。
4 关于word2vec的skip-gram模型使用负例采样nce_loss损失函数的源码剖析
标签:passing word2vec rop 观察 方差 答案 embedding most Dimension
原文地址:https://www.cnblogs.com/xiaojieshisilang/p/9284634.html