标签:heap yar nod mon 交互 park tor 多个 分享图片
● Based on the recommendations mentioned above, Let‘s assign 5 core per executors => --executor-cores = 5 (for good HDFS throughput)
● Leave 1 core per node for Hadoop/Yarn daemons => Num cores available per node = 16-1 = 15
● So, Total available of cores in cluster = 15 x 10 = 150
● Number of available executors = (total cores/num-cores-per-executor) = 150/5 = 30
● Leaving 1 executor for ApplicationManager => --num-executors = 29
● Number of executors per node = 30/10 = 3
● Memory per executor = 64GB/3 = 21GB
● Counting off heap overhead = 7% of 21GB = 3GB. So, actual --executor-memory = 21 - 3 = 18GB
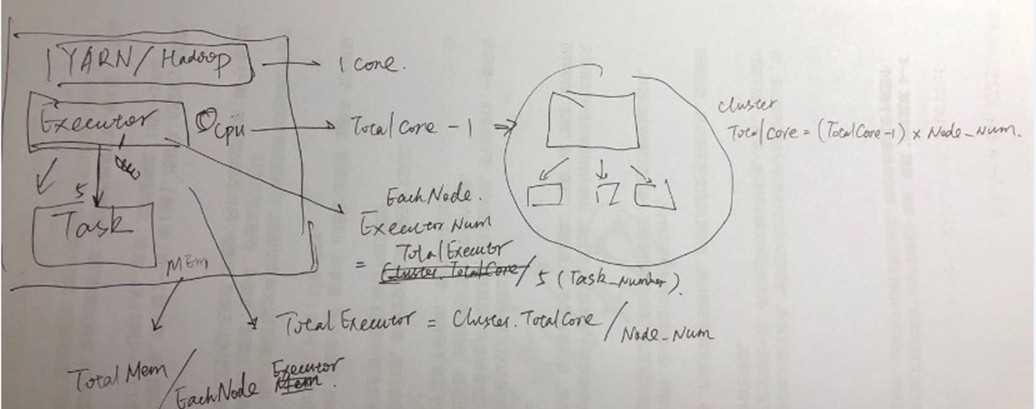
基本思路就是要明确经验值,一个executor跑5个task,因为spark需要和hdfs client交互实现对于hdfs的读写;所以多个客户端可以实现并行,效果比较好;
然后就是首先计算core的数量,
接着计算executor数量,包括总数量以及单节点数量;首先求出总数量,然后是单个节点的数量;注意这里需要把AM的executor数量考虑进去(一个)
最后是计算内存;内存都是计算单机内存;但是内存不可能都分配给JVM;
标签:heap yar nod mon 交互 park tor 多个 分享图片
原文地址:https://www.cnblogs.com/xiashiwendao/p/9286736.html