标签:sele 导出 升级 mina ima 分享 需要 获得 数据库
需求:统计某网站的pv(网页浏览量),uv(用户量)的数据量,并存储于数据库中,以便于用户查询。
思路分析:
具体实现:
1.1在hive中建立相对应的数据库,再在数据库中创建与logs数据相对应的管理表,并在其中补充与数据对应的字段。(hive表在hdfs中对应的是一个目录)
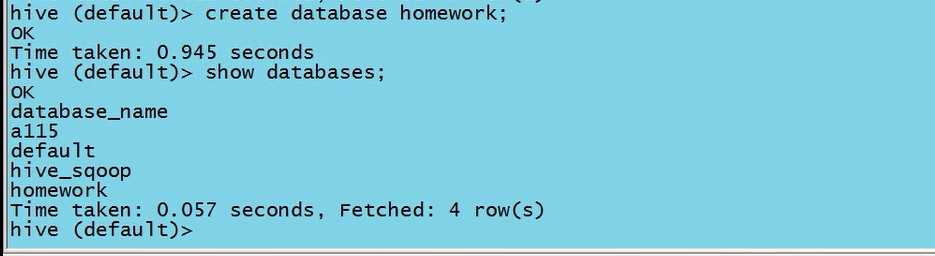
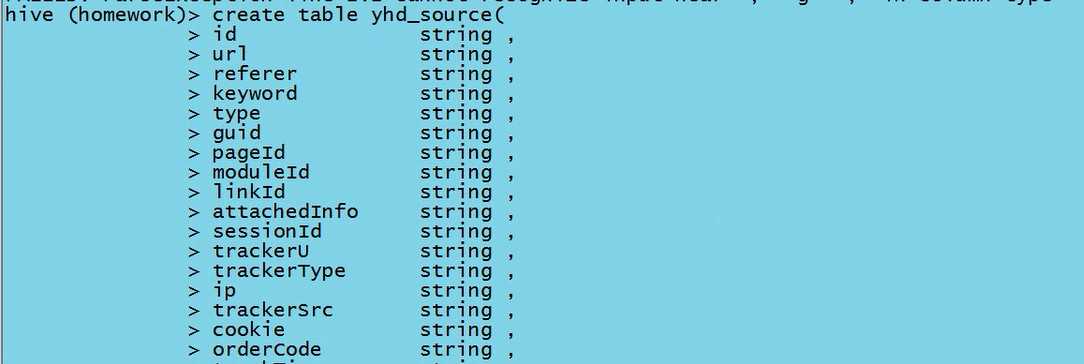
1.2将logs数据加载到表中

2.1建一张清洗表,将时间字段清洗,提取部分的时间字段出来
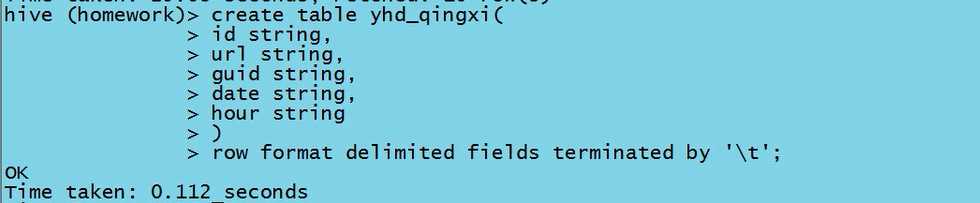
2.2字段截取,插入数据,天&小时

3.分区
因为清洗表的数据中囊括了所有时间点的数据,在查询时会将所有数据加载之后再一一查询各个时间点的数据,这会降低查询效率。故以日志数据中的时间作为条件进行分区以提高查询效率。
3.1 建立分区表

3.2 加载数据,来源于source源表


4.1 创建一张新表将pv和uv的数据统计出来插入进去


5.1 进入MySQL中创建一张与需求数据相对应的表
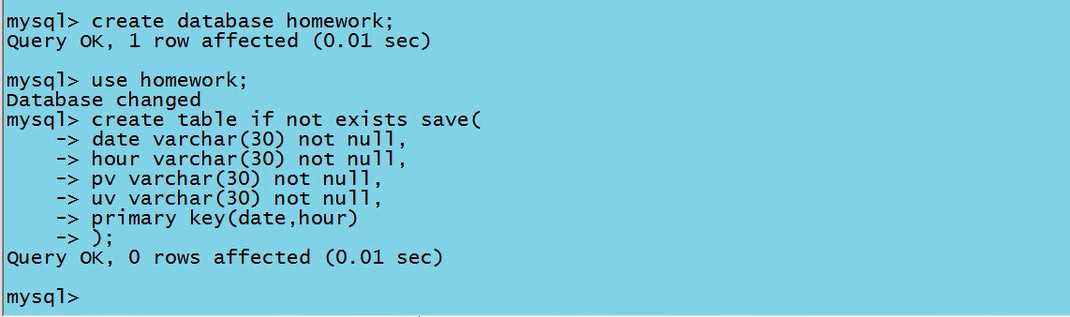
5.2 使用sqoop将数据导入至MySQL中 (hive默认的分隔符是‘\001‘,hdfs默认的分隔符是‘\t‘)

5.3 MySQL查询测试
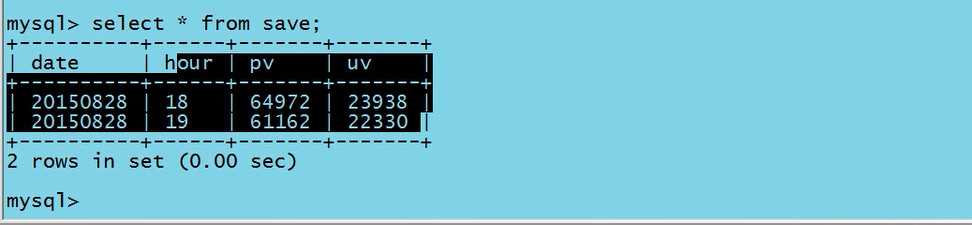
操作完毕!
进阶:静态分区升级为动态分区
1.首先在hive-site.xml中指定配置
<property>
<name>hive.exec.dynamic.partition</name>
<value>true</value>
<description>Whether or not to allow dynamic partitions in DML/DDL.</description>
</property>
----> 默认值是true,代表允许使用动态分区实现
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>strict</value>
<description>In strict mode, the user must specify at least one static partition in case the user accidentally overwrites all partitions.</description>
</property>
----> set hive.exec.dynamic.partition.mode=nonstrict; 使用非严格模式(此举只是暂时性地修改)
2.建表
create table yhd_part2(
id string,
url string,
guid string
)
partitioned by (date string,hour string)
row format delimited fields terminated by ‘\t‘;
insert into table yhd_part2 partition (date,hour) select * from yhd_qingxi;

3.执行动态分区:
Insert into table yhd_part2 partition (date,hour) select * from yhd_qingxi;

4.效果展示
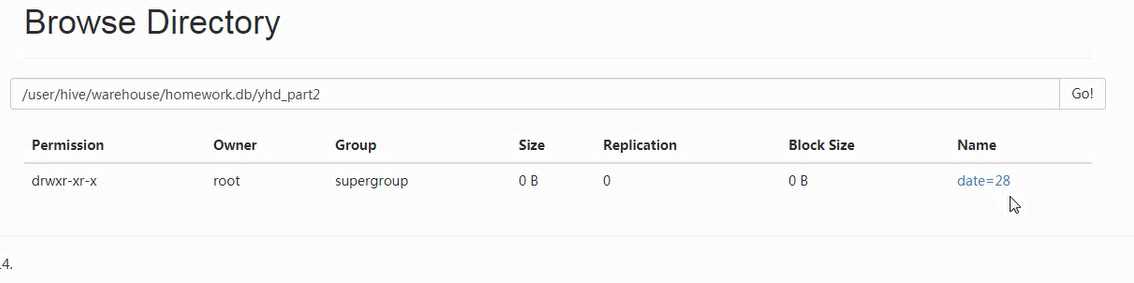
标签:sele 导出 升级 mina ima 分享 需要 获得 数据库
原文地址:https://www.cnblogs.com/wyl-129/p/9286698.html