标签:输入 vector nta 直接 embed 就是 bag sum inline
将word映射到一个新的空间中,并以多维的连续实数空间向量进行表示,叫做word representation,或者word embeding.
n-gram: n-gram是一种统计语言模型。根据前n-1个item预测第n个item,这些item可以是音素(语言识别应用),字符(输入法应用),词(分词应用)或碱基对。一般可以从大规模文本或者语料库中生成n-gram模型。
词袋:Bag of Words,假设对于一个文本,将其仅仅看作是一个词集合,而忽略其词序和语法。
在实际应用中,将这组词变成一串数字(索引的集合)
John likes to watch movies. Mary like too. --->[1,2,1,1,1,0,0,0,1,1]
John also like to watch football games. --->[1,1,1,1,0,1,1,1,0,0]
其中,第i个元素表示字典中第i个单词在句子中出现的次数。
上述构成了字典:{‘John‘:1,‘like‘:2,‘to‘:3,...,‘too‘:10}
Word2Vec
分为两种语言模型:CBOW和Skip-gram

CBOW根据上下文的词语预测当前词语出现概率的模型。
最大化对数似然函数\(L=\sum _{w\in c}logP(w|context(w))\)
输入层是上下文的词向量(词向量是CBOW的参数,其实际上是CBOW的副产物)
投影层是简单的向量加法
输出层是输出最可能的w。由于词料库中词汇量是固定的|c|个,可以将其看作是多分类问题。最后一层是Hierarchical softmax:
\[
p(w|context(w))=\prod_{j=2}^{l^w}p(d_j^w|x_w,\theta_{j-1}^w)
\]
从根节点到叶节点经过了\(l^{w}-1\)个节点,编码从下标2开始(根节点无编码),对应的参数向量下标从1开始。
skip-gram 已知当前词语,预测上下文
与CBOW不同之处在于:
模型:
\[
p(context(w)|w)= \prod_{w \in context(w)}p(u|w)
\]
这是一个词袋模型,所以每个u都是无序,相互独立的
doc2vec:
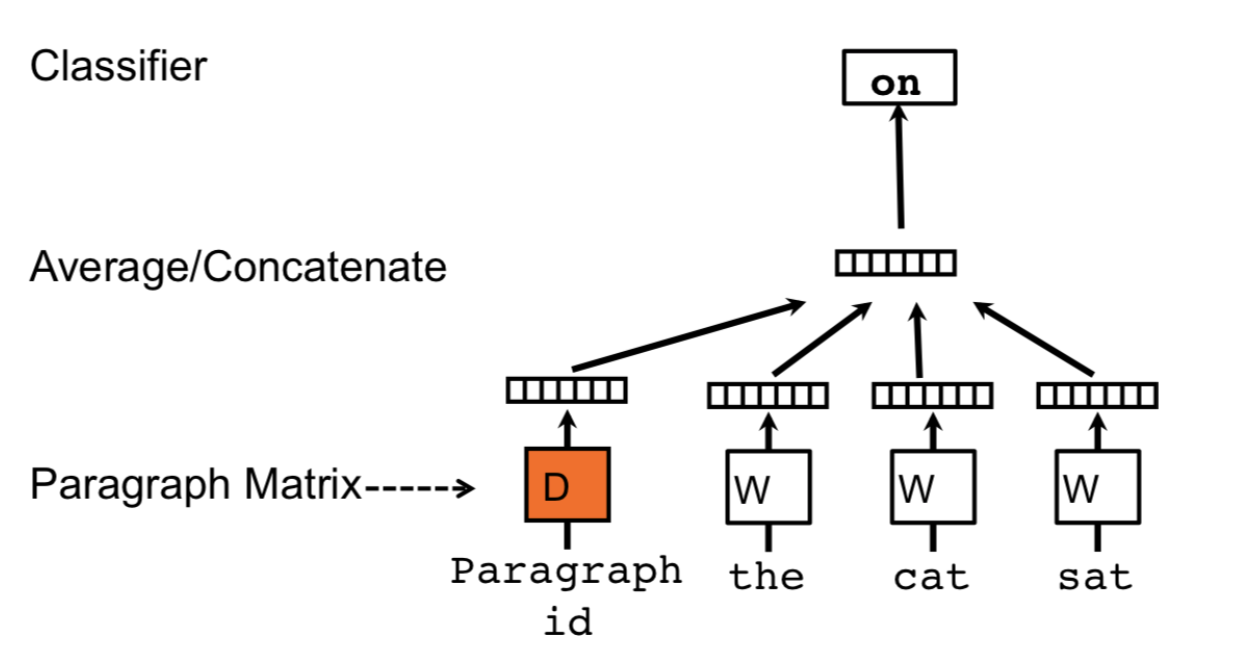
与word2vec唯一不同之处在于,串联起word vector在上下文中预测下一个单词。
上下文是固定长度且在段落中sliding window中采样,段落向量在一段中共享在同一段中产生的所有窗口,但是不同段间不共享。
标签:输入 vector nta 直接 embed 就是 bag sum inline
原文地址:https://www.cnblogs.com/mengnan/p/9307547.html