标签:bit hub == 基于 建议 初始 下载 beta neu
Tesseract 4 版本具备两种识别引擎:新的基于LSTM(神经网络)引擎与传统引擎。通过在初始化时设定不同的EngineMode启动。
OCR Engine modes:
0 Legacy engine only.
1 Neural nets LSTM engine only.
2 Legacy + LSTM engines.
3 Default, based on what is available.
当设置OcrEngineMode为2时,则表示启动双引擎进行识别,Tesseract首先会尝试LSTM引擎,如果识别失败,则会再使用传统引擎进行识别,此种模式追求高精确度,但会消耗较多的系统资源。
Tesseract在识别时,是需要训练数据文件,也就是tessdata。两种引擎对训练数据文件的要求不同,两种引擎训练数据也不通用。
在GitHub上tessdata_fast (https://github.com/tesseract-ocr/tessdata_fast)和tessdata_best (https://github.com/tesseract-ocr/tessdata_best)均是基于LSTM引擎的训练数据,不可以用于传统引擎。
而在 GitHub上的tessdata(https://github.com/tesseract-ocr/tessdata)库中,在2016年10月之后的文件,是包含两种引擎的训练数据文件。
笔者计划Tesseract识别数字及英文(eng.traineddata),希望使用双引擎提升精确度,但发现GitHub的tessdata库中eng.traineddata虽然包含了两种引擎的训练数据,但其中内置的LSTM引擎的训练数据不是最新的(相对于tessdata_best),因此产生了想法,自行构建一个训练数据文件,包含来自于tessdata库中传统引擎训练数据与tessdata_best库中LSTM引擎的训练数据。
Tesseract:v4.0.0-beta.1.20180608
(Windows版本:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v4.0.0-beta.1.20180608.exe,
默认安装路径 C:\Program Files (x86)\Tesseract-OCR)
操作系统:Windows 10 64bit
从tessdata_best中下载eng.traineddata文件,从tessdata中下载eng.traineddata文件。
两个文件重名,为表示区别,将从tessdata_best文件重命名为eng.best.traineddata。如下:
Tesseract提供了traineddata的打包与解压工具,名为combine_tessdata。我们将使用这个命令完成此步骤。
建议将eng.trainneddata与eng.best.trainneddata解压到两个独立文件夹。
(combine_tessdata 默认在C:\Program Files (x86)\Tesseract-OCR中,执行命令前请确认命令已经加入操作系统PATH路径)
首先完成eng.trainneddata文件解压。
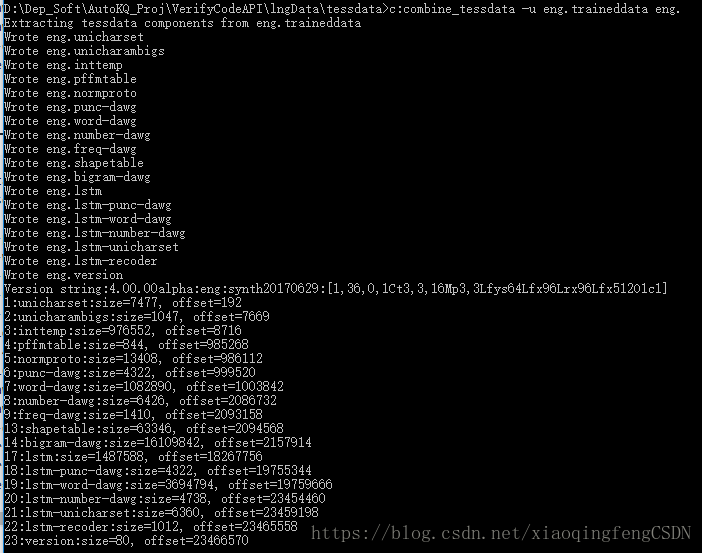
使用命令:combine_tessdata -u <要解压的trainneddata文件路径> <目标路径及解压文件名前缀>
如combine_tessdata -u ..\eng.traineddata 1\eng.
含义为:将当前路径上一级目录中的eng.trainneddata解压到当前目录中名称为1的子目录,且所有文件以eng.开头。
执行命令成功效果类似下图:
同样方法,完成eng.best.traineddata解压。
本文实践时,将eng.trainneddata解压至data文件夹,将eng.best.trainneddata解压至data.best文件夹
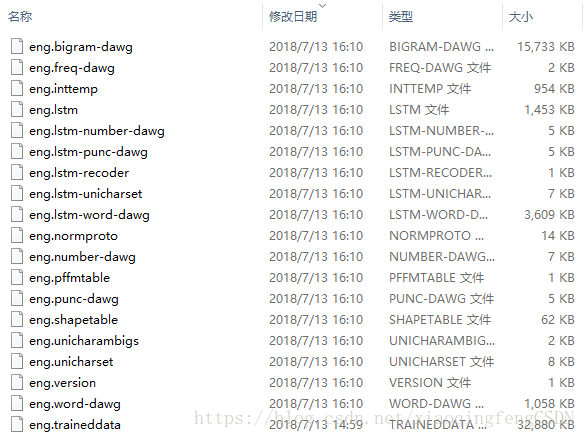
eng.trainneddata解压后data文件夹内容:
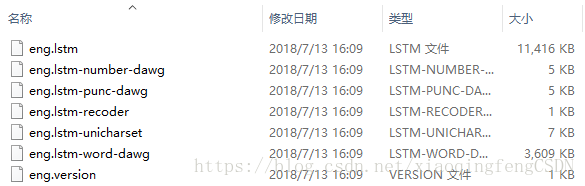
eng.best.trainneddata解压后data.best文件夹内容:
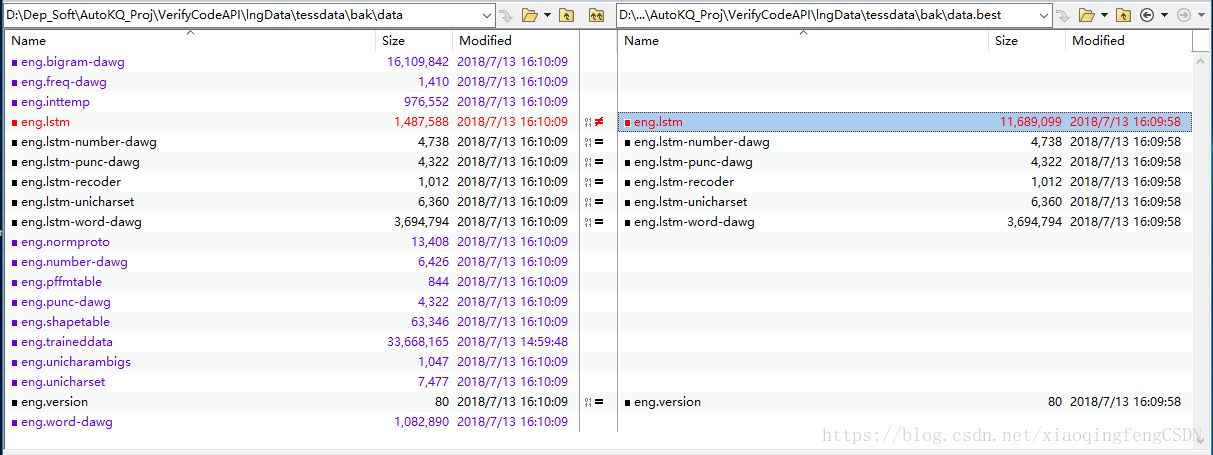
经过对比,可发现,eng.best.traineddata中lstm文件与eng.traineddata中不同。
将data.best(来自eng.best.traineddata)整体覆盖到data目录。
此时data目录中是一份结合了最新的LSTM及传统引擎训练文件的文件夹。
在data目录中,执行combine_tessdata进行封包。
执行命令:combine_tessdata .\eng.
命令格式:combine_tessdata <计划打包的tessdata文件目录以及欲打包的文件前缀>
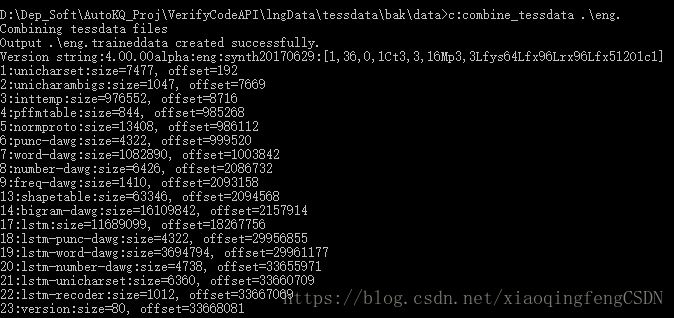
combine_tessdata .\eng. 命令则会将当前路径下以eng.开头的文件打包到eng.trainneddata,执行成功效果如下:
执行完毕后,就可以获得合并了两种引擎训练数据的文件,如下。
至此全部步骤完毕。
ITesseract instance = new Tesseract();
instance.setOcrEngineMode(TessOcrEngineMode.OEM_TESSERACT_LSTM_COMBINED);
instance.setDatapath(tessdataFolder.getAbsolutePath());
instance.setPageSegMode(TessPageSegMode.PSM_SINGLE_LINE);
instance.setLanguage("eng");
instance.setTessVariable("tessedit_char_whitelist","0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ");
其中setOcrEngineMode(TessOcrEngineMode.OEM_TESSERACT_LSTM_COMBINED)表示启动两种引擎。
Tesseract 4 自行构建支持双引擎的tessdata 文件
标签:bit hub == 基于 建议 初始 下载 beta neu
原文地址:https://www.cnblogs.com/zlAurora/p/9309498.html