标签:编辑器 需要 目录 获取ip 编辑 nod 部署 inux .gz
主要思想:先把需要配置的文件修改好,通用的软件安装好,再把虚拟机克隆出几份,细节再具体实现。
机如果你的虚拟机是才装好的,那么它就会是以下界面,点击“创建虚拟机”。
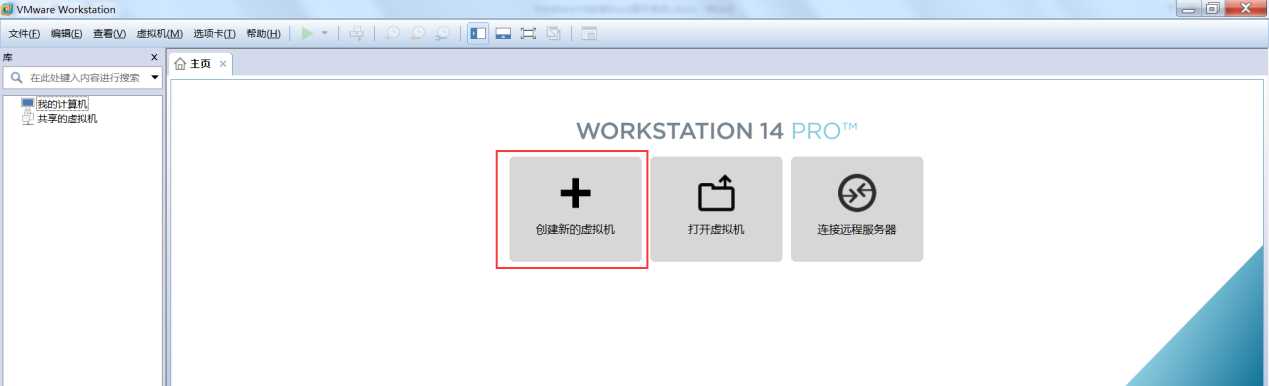
或者通过文件?新建虚拟机。
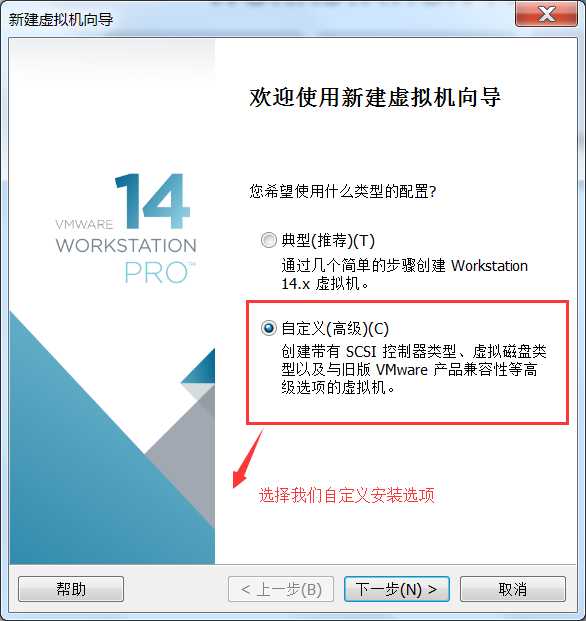
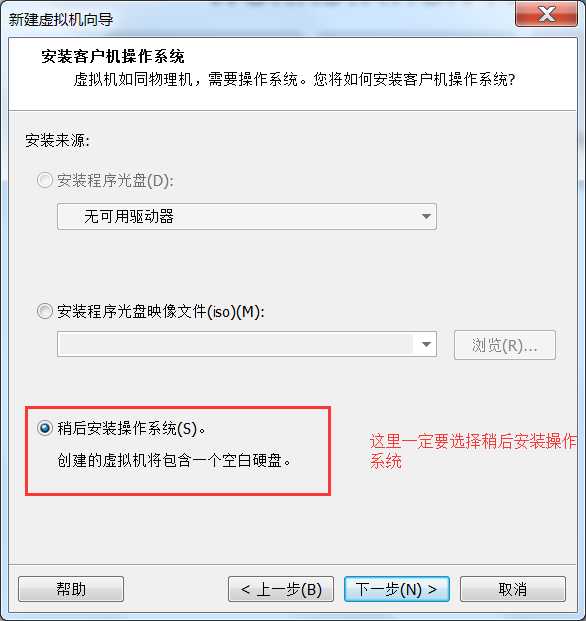
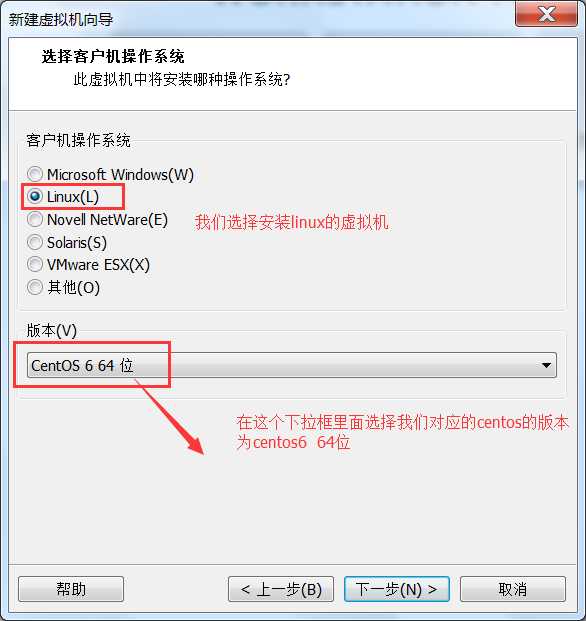
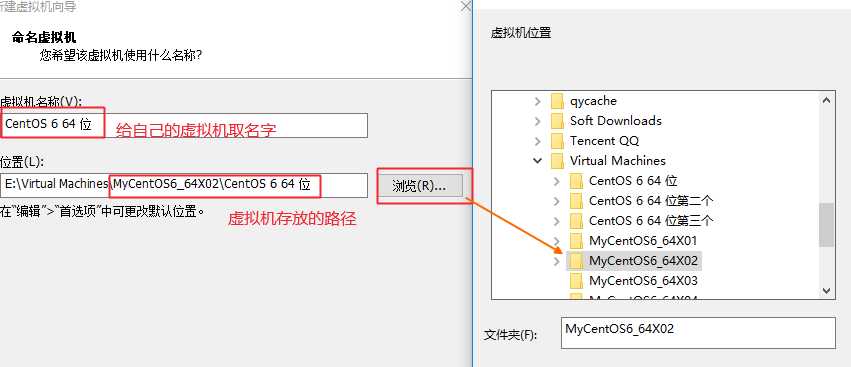
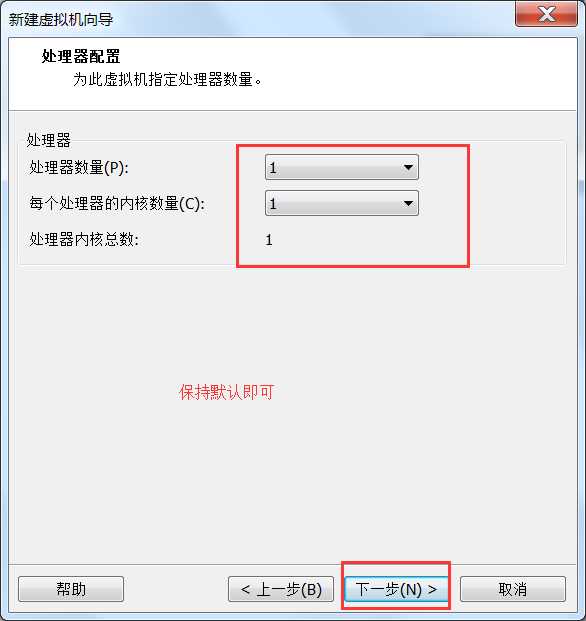
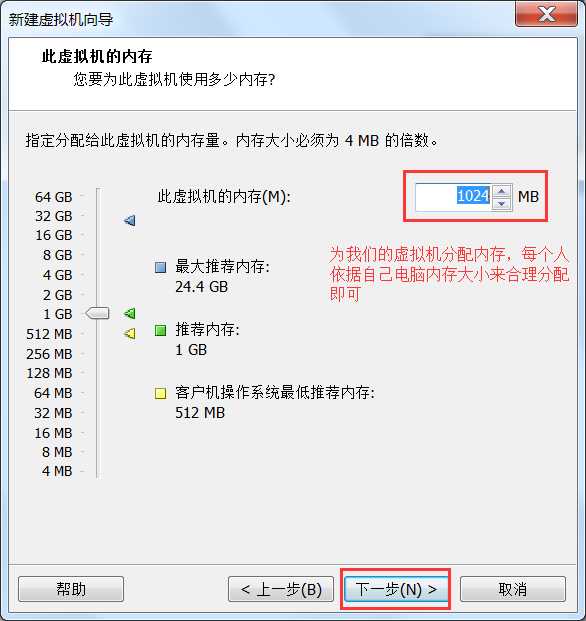
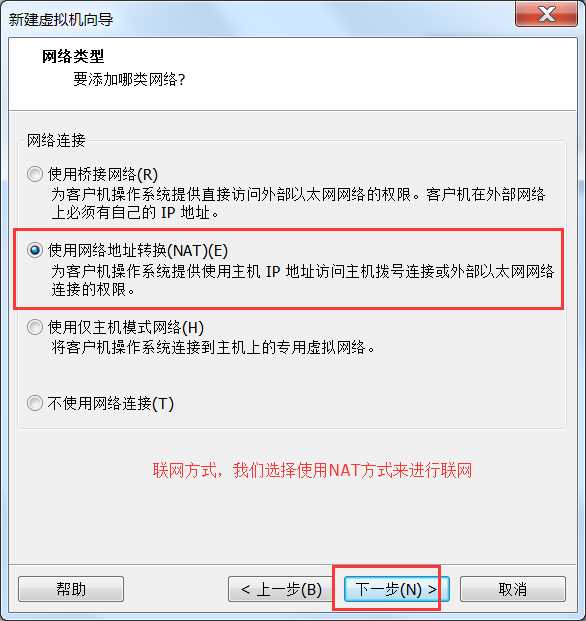
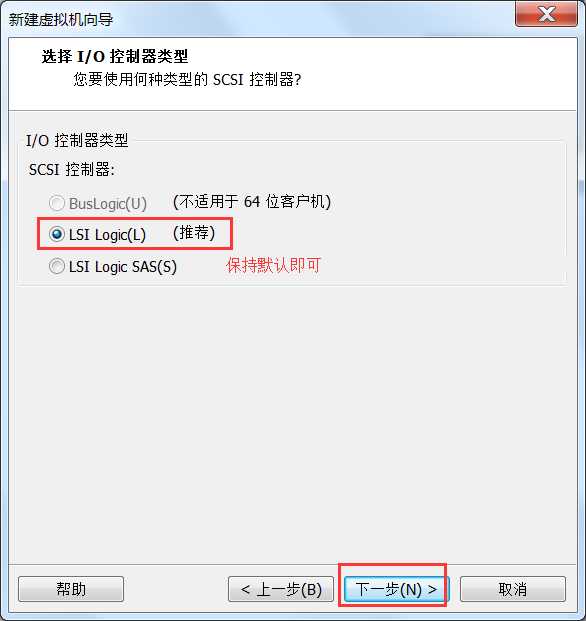
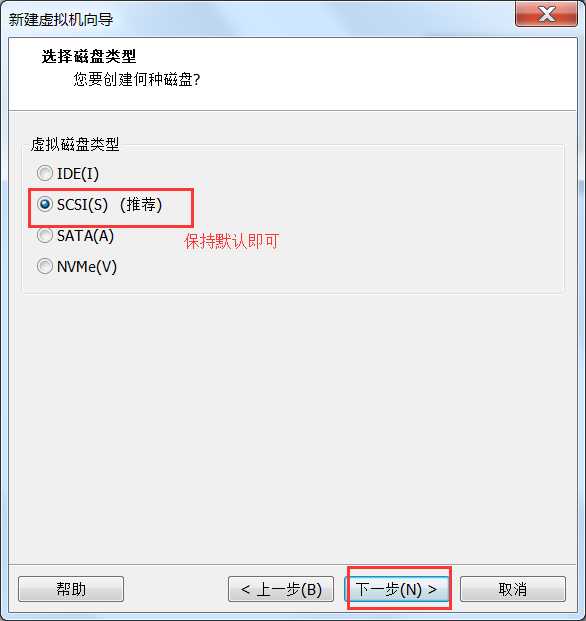
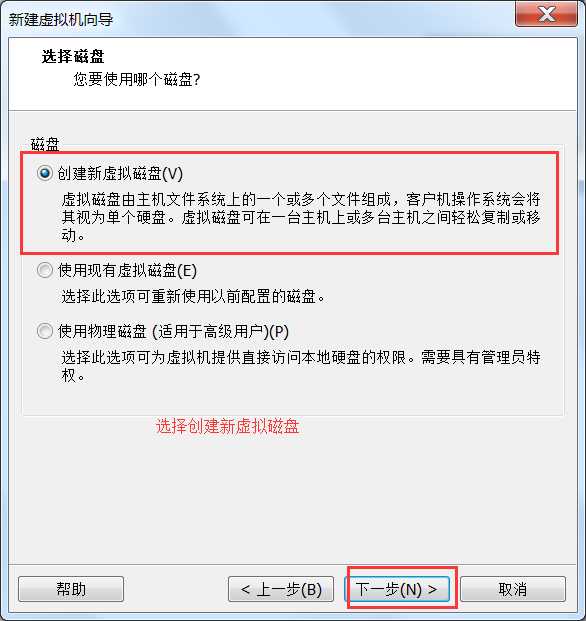
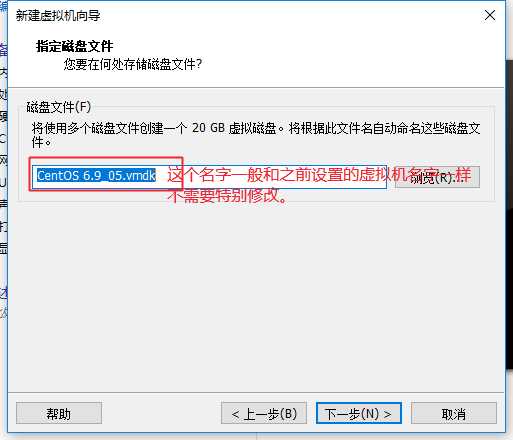
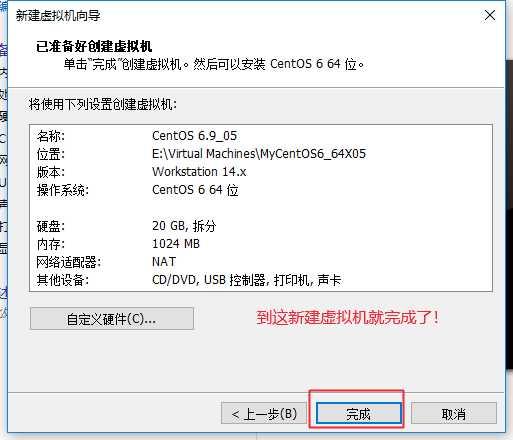
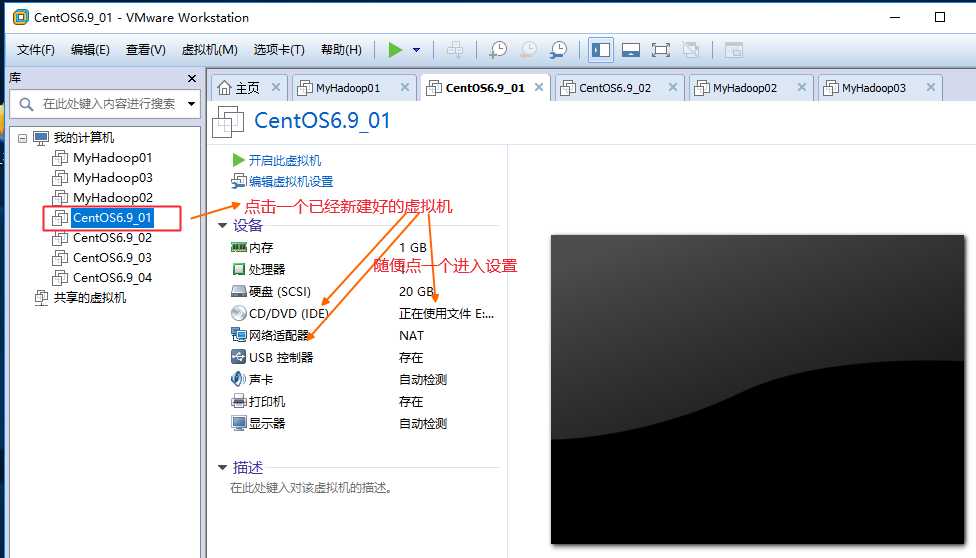
或者虚拟机右键à设置也可以
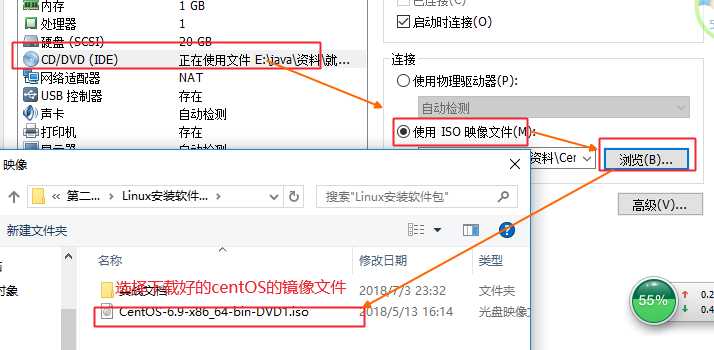
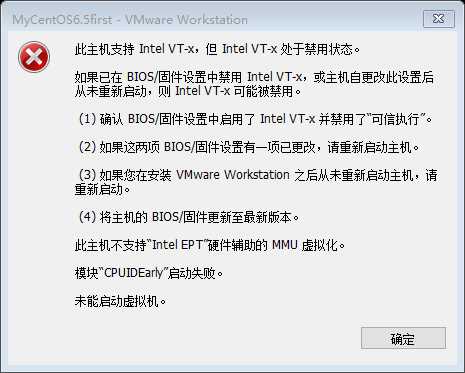
进入biso系统—>configuration—>将Intel virtual 。。。设置成enable。
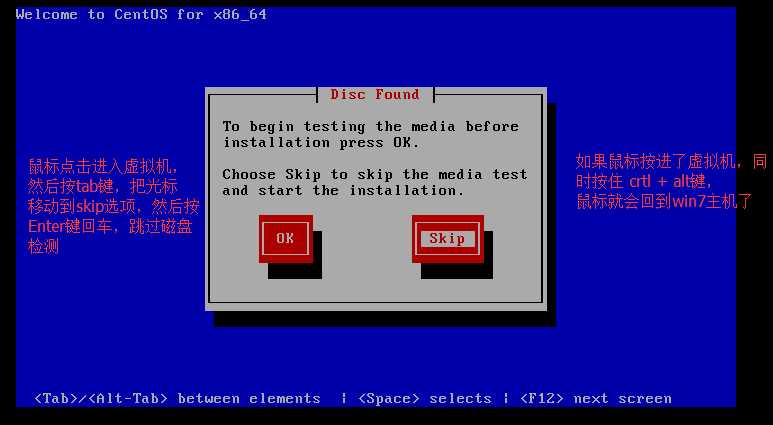

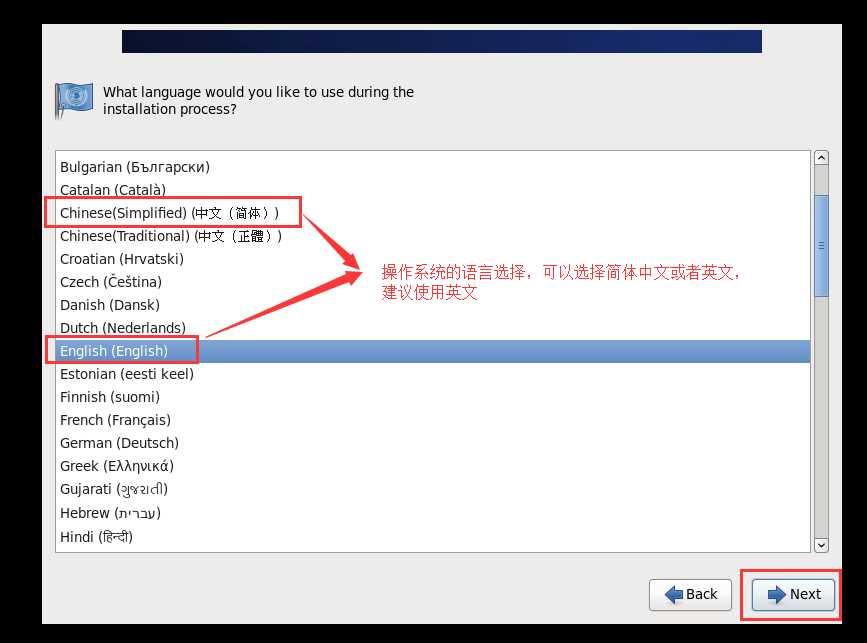
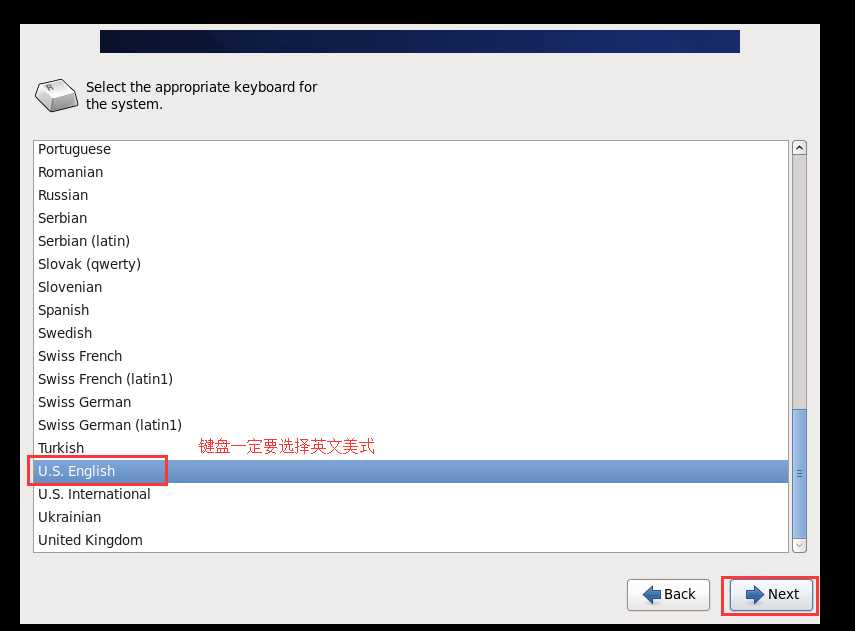
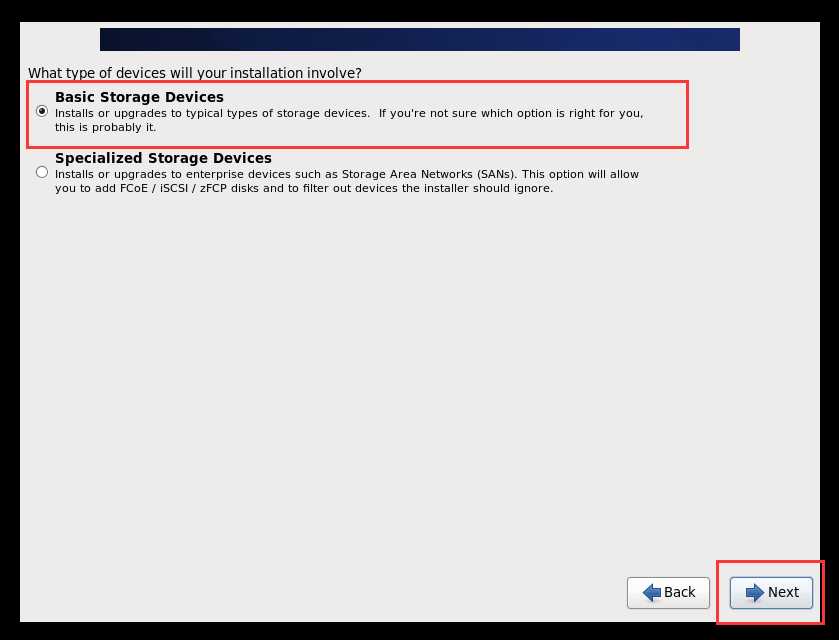
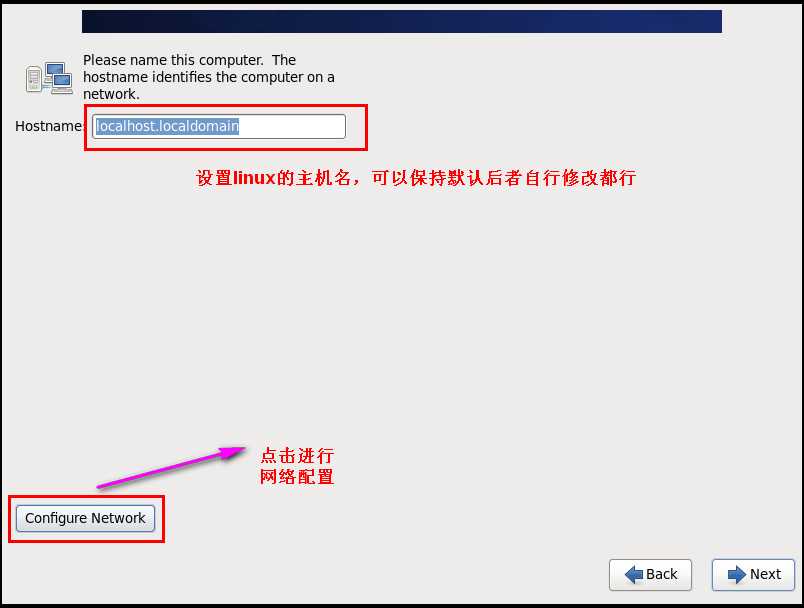
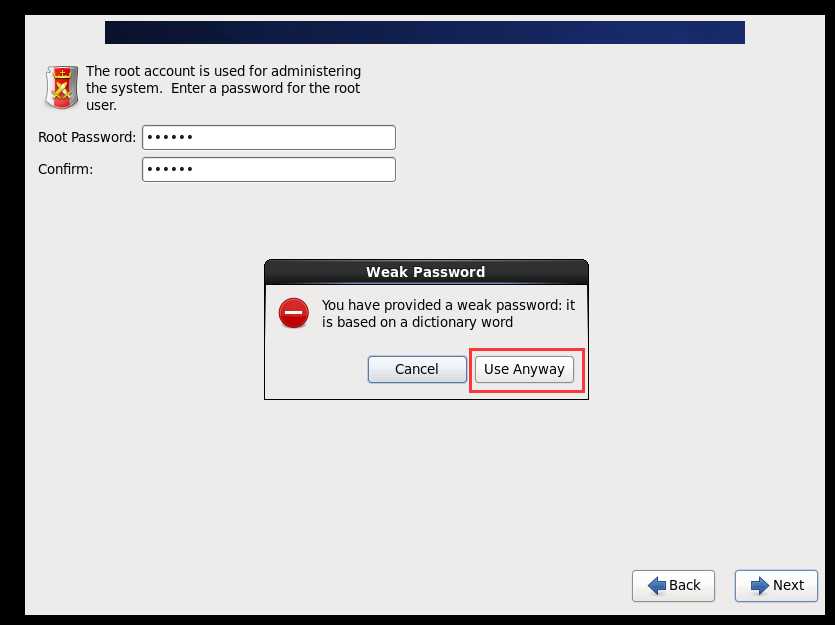
Figure 1修改主机名称为自己想要的名称,我的为hadoop01。
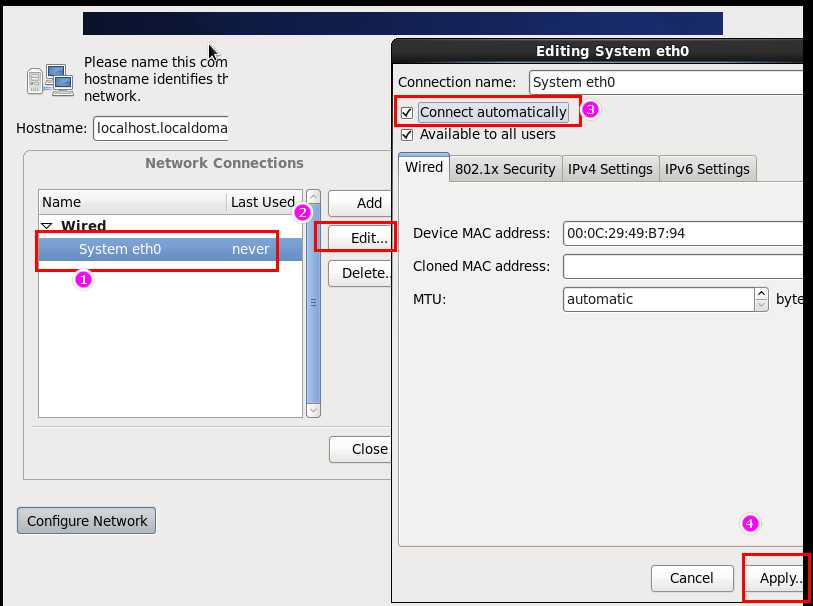
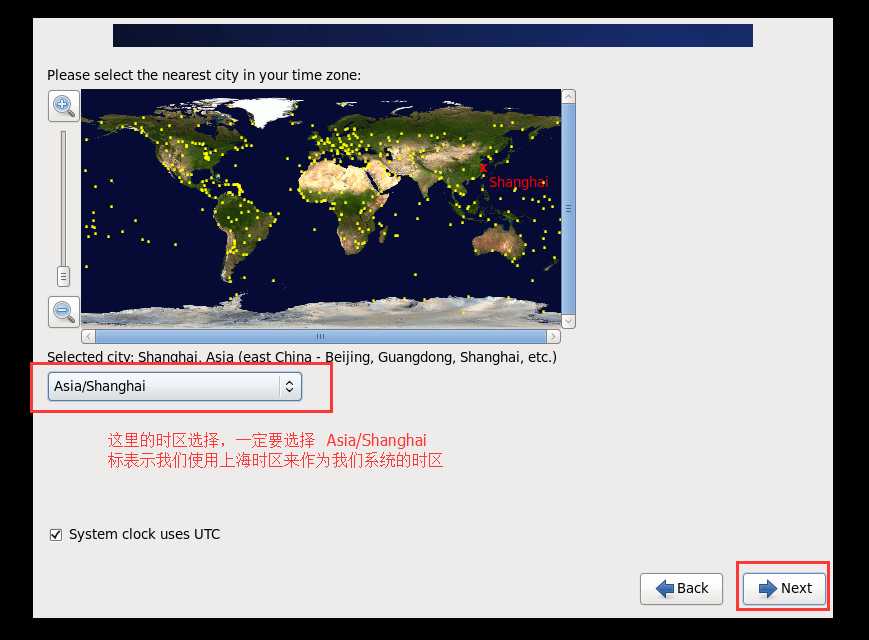
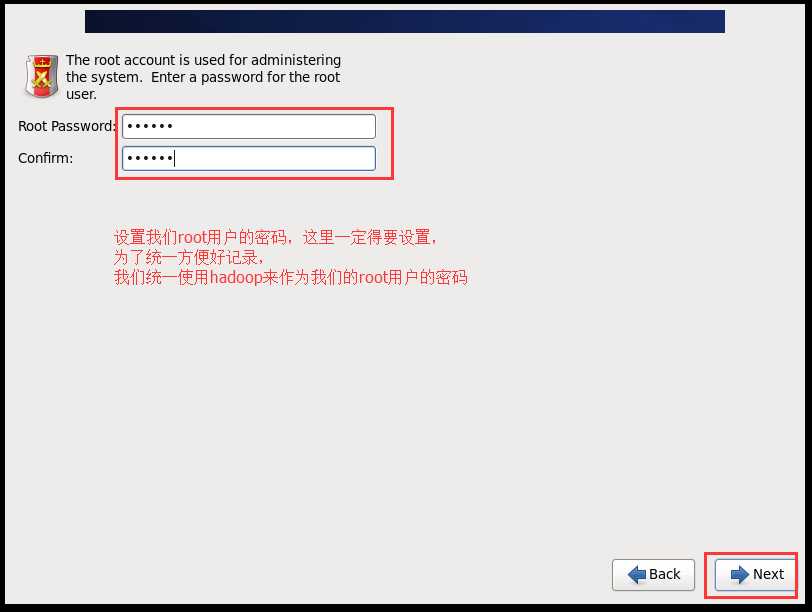
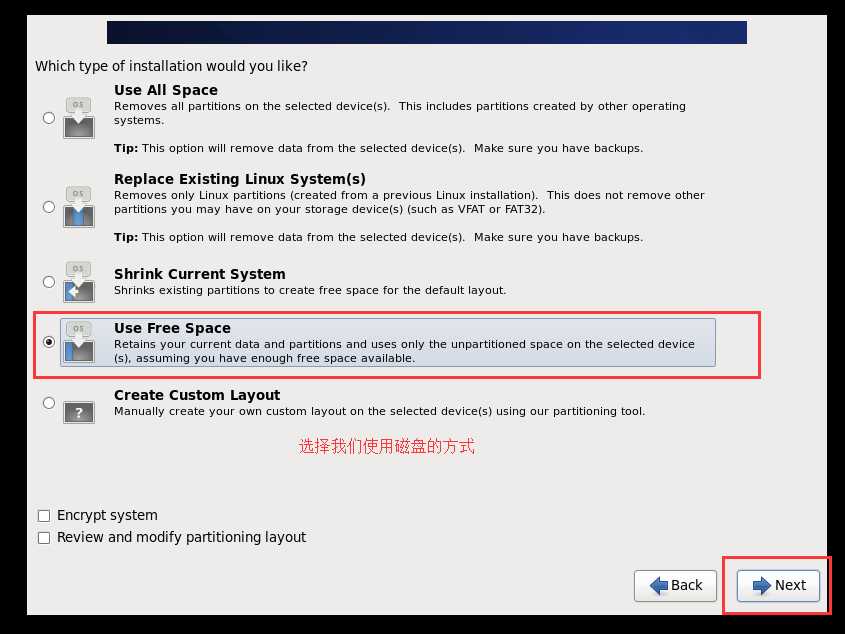
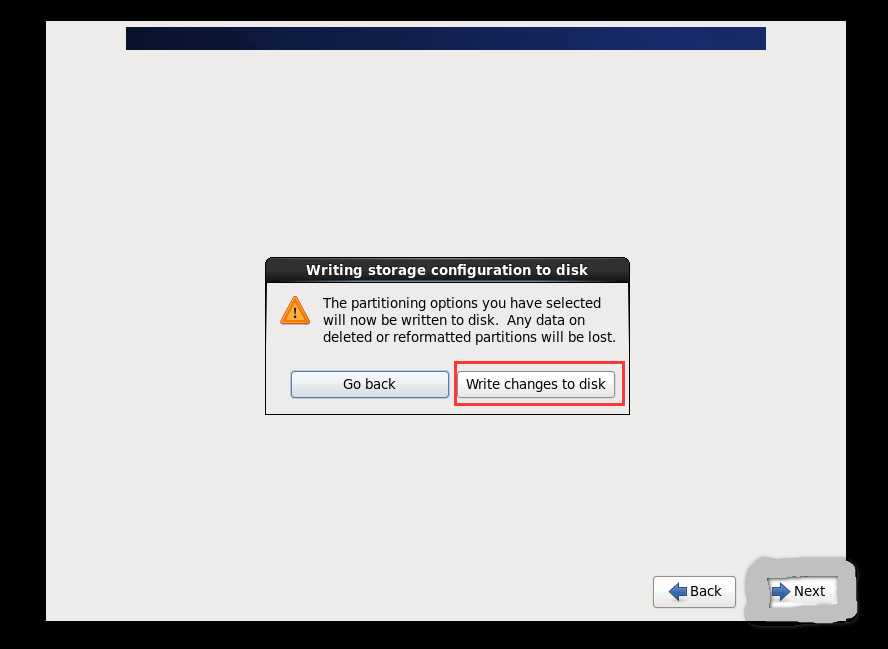
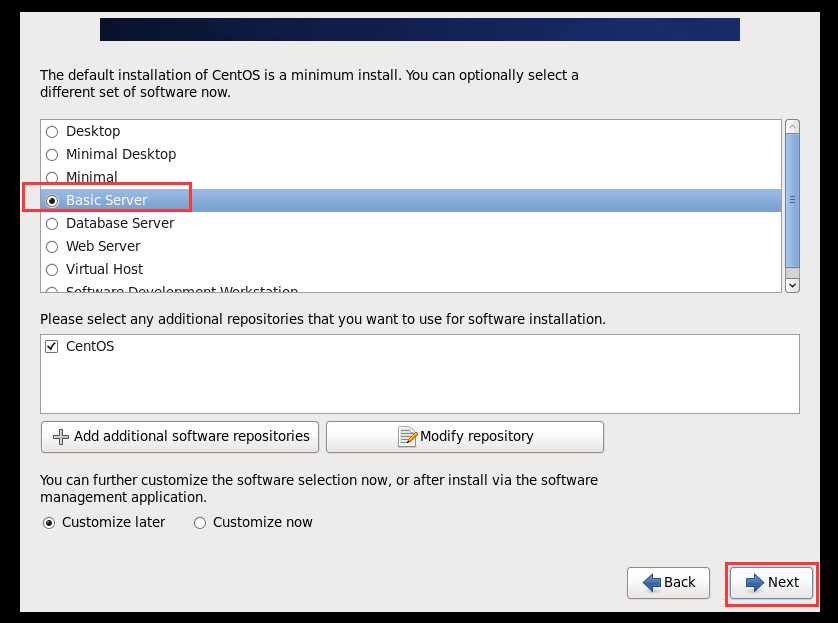
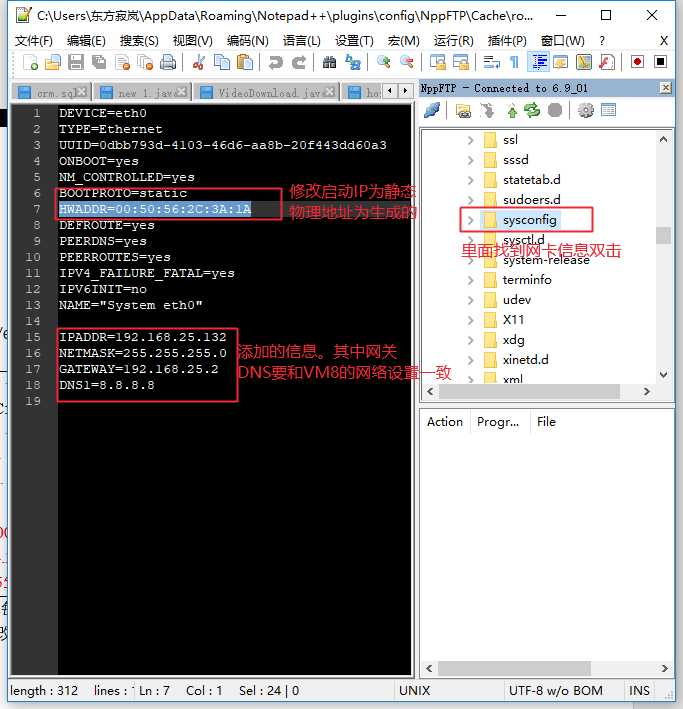
l 查看网卡配置 cat /etc/sysconfig/network-scripts/ifcfg-eth0
l 概要信息如下:
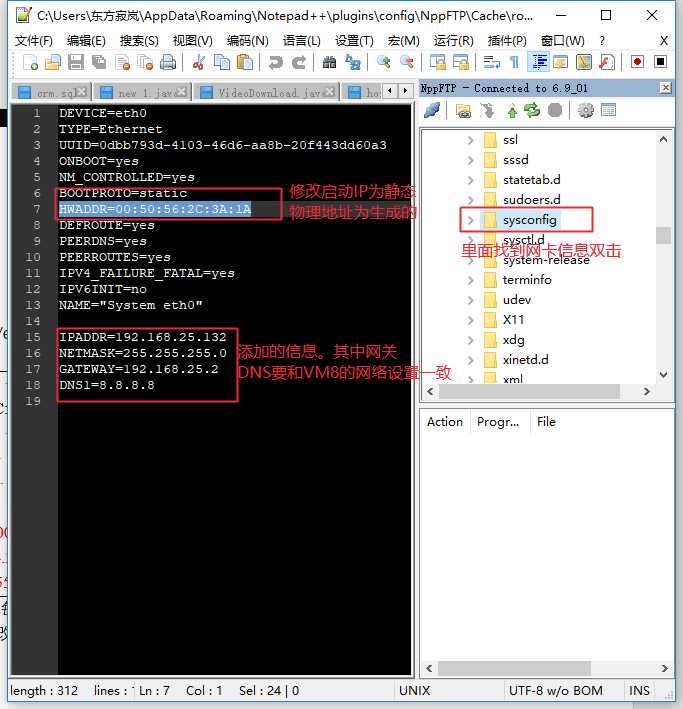
l 修改命令:VIM /etc/sysconfig/network-scripts/ifcfg-eth0
|
DEVICE=eth0 #网卡名称 HWADDR=00:50:56:2C:3A:1A #物理地址,这个与上面生成的要一致 TYPE=Ethernet #网卡类型 ONBOOT=yes #是否开机启动网卡 BOOTPROTO=static #静态获取IP,其他取值:dhcp (如果设置dhcp下面红色不需要) 添加以下内容: IPADDR=192.168.44.100 #ip地址 GATEWAY=192.168.44.2 #网关 NETMASK=255.255.255.0 #子网掩码 |
自动获取的IP地址会在每次开机时有可能都不一样,连接就很麻烦了。
通过编辑器插件链接修改
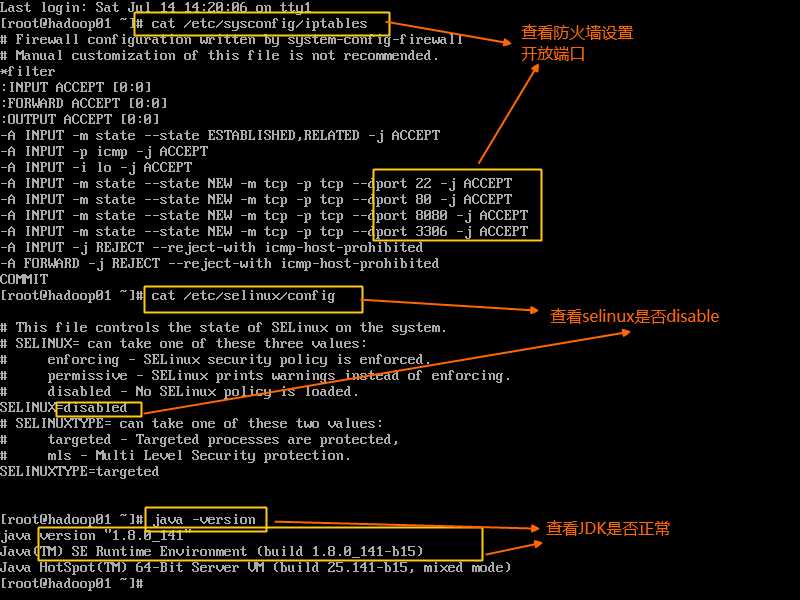
1、查看防火墙规则cat /etc/sysconfig/iptables
vim /etc/sysconfig/iptables
放开某个端口号不被防火墙拦截,适用于部署tomcat,nginx等之类的软件:
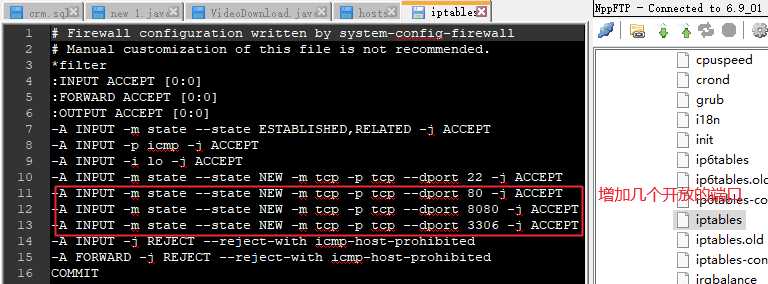
设置完成后,重启防火墙:service iptables restart 查看状态service iptables status
2、关闭防火墙
service iptables stop
3、禁止防火墙关机自启动
chkconfig iptables off
chkconfig iptables --list 查看自启动状态列表
注意:在实际工作当中,大数据集群一般都是放置在内网当中,通过跳板机进行连接,所以一般都是直接关闭防火墙即可,但是在实际工作中,web服务器关闭防火墙一定要谨慎,避免服务器感染病毒
直接通过网络方式进行联网配置
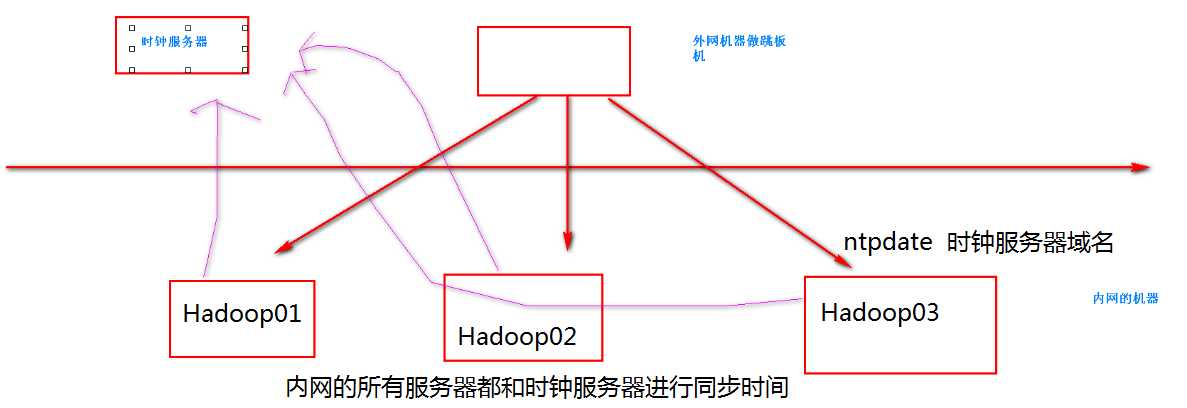
安装ntp服务

如果没有安装,可以进行在线安装
yum -y install ntpd
使用定时任务:定时进行时钟同步 date查看本地时间 date -s “日期”
ntpdate us.pool.ntp.org 这个命令就可以和时钟服务器进行通信。
crontab -e 编辑定时任务
*/1 * * * * /usr/sbin/ntpdate us.pool.ntp.org; 每分钟都进行时钟同步
执行ntpdate us.pool.ntp.org
更改第二台与第三台机器的主机名
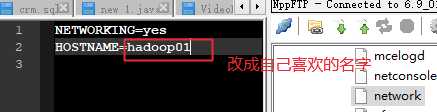
vim /etc/sysconfig/network
HOSTNAME=hadoop01
更改机器的主机名与ip地址的映射
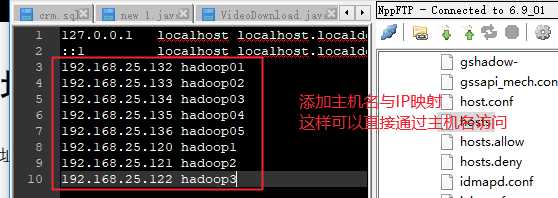
vim /etc/hosts
192.168.25.120 hadoop1
192.168.25.121 hadoop2
192.168.25.122 hadoop3
。。。。。
注意:上面需要根据你自己的ip和主机名,进行设置
192.168.25.120 hadoop1
192.168.25.121 hadoop2
192.168.25.122 hadoop3
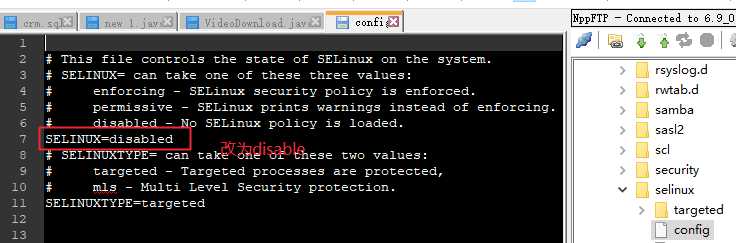
vim /etc/selinux/config
SELINUX=disabled
在这里可以克隆一份,作为纯净版保存,以防后面再次安装
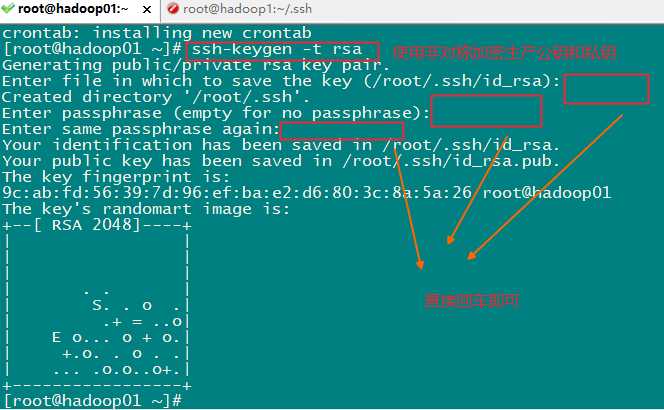
进入cd /root/.ssh/目录下,可以查看生成的文件
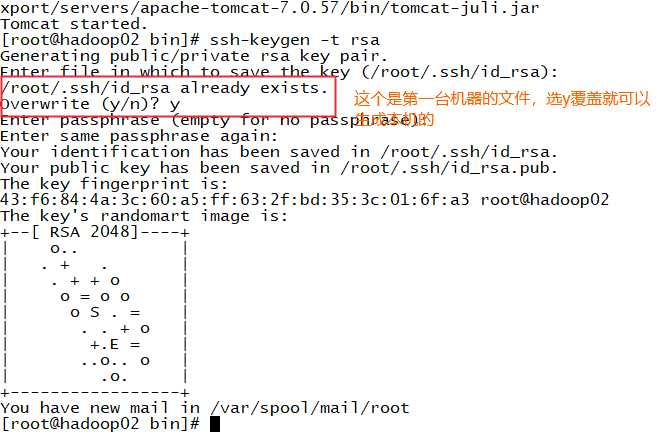
第一步: ssh-keygen -t rsa 在每一台机器(如果已经安装了多台设备)上面都要执行,产生公钥和私钥
第二步:在其他已安装的设备上执行:ssh-copy-id hadoop1(没有设置主机IP映射前使用IP链接) 将其他机器的公钥拷贝到hadoop1(同一台设备)上面去
第三步:将第一台的文件拷贝到其他机器上去
scp authorized_keys hadoop2:$PWD
scp authorized_keys hadoop3:$PWD
这样就可以在其他机器上使用命令:ssh hadoop01 来登录 hadoop01 了。
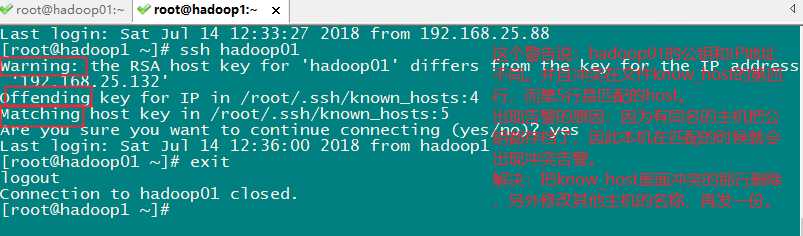
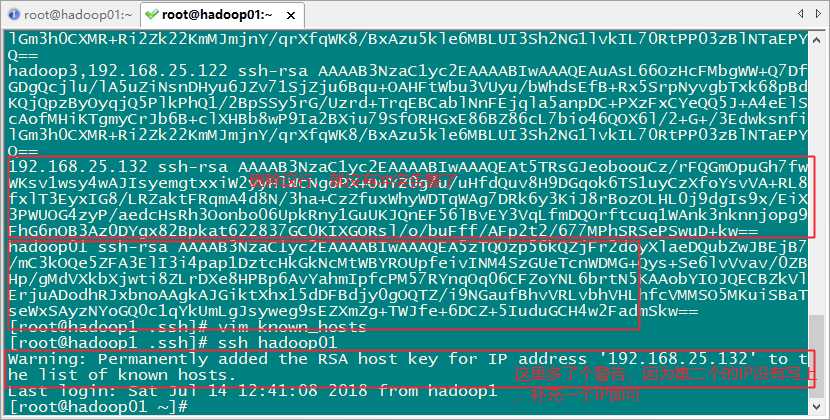

或者直接运行一条命令搞定“sed -i -e ’4d’ ~/.ssh/known_hosts”。
reboot 重启生效所有的设置
1,linux上面jdk的安装
2,linux上面tomcat的安装
3,linux上面mysql的安装(看情况选装)
第一步:规范两个目录
mkdir -p /export/servers # 存放我们所有安装的软件地址
mkdir -p /export/softwares # 存放我们所有的安装包

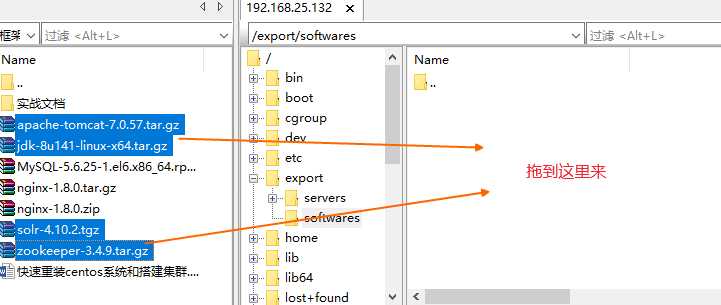
第二步:上传所有的软件包(使用ftp上传工具)
第三步:查看centos6.9是否自带了jdk
rpm -qa | grep jdk

第四步:卸载自带的openJdk
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64 java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64
第五步:解压我们的jdk

Cd /export/softwares/
tar -zxvf jdk-8u141-linux-x64.tar.gz -C /export/servers/
第六步:配置我们jdk的环境变量,使用编辑器

vim /etc/profile
export JAVA_HOME=/export/servers/jdk1.8.0_141
export PATH=:$JAVA_HOME/bin:$PATH
第七步:使我们的环境变量马上生效
source /etc/profile
第八步:验证jdk是否安装成功
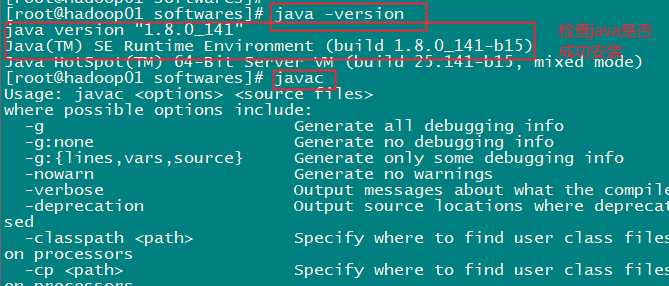
第一步:解压我们的tomcat压缩包

tar -zxvf apache-tomcat-7.0.57.tar.gz -C /export/servers/
第二步:启动我们的tomcat
cd /export/servers/apache-tomcat-7.0.57/bin
./startup.sh
关闭防火墙:service iptables off
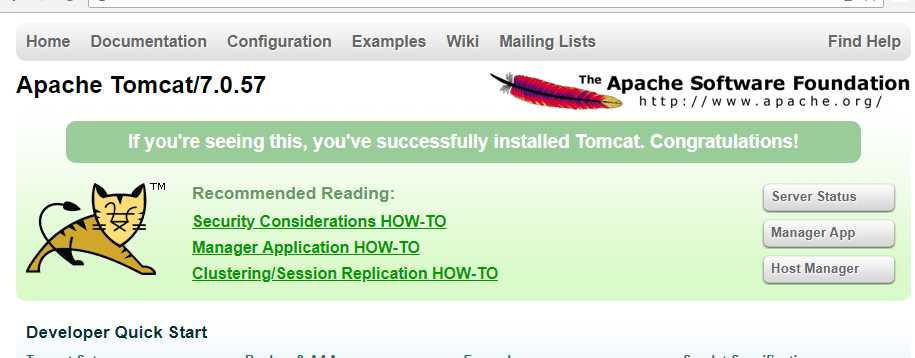
在浏览器中查看:http://192.168.25.132:8080/ 注意IP写本机地址,出现tomcat猫说明成功了。
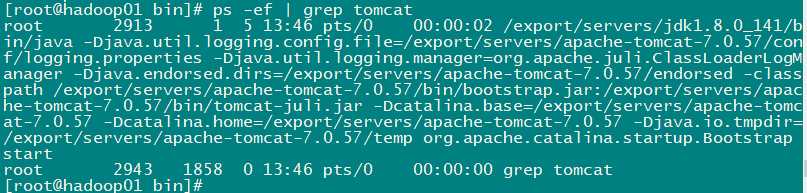
另外:查看tomcat进程是否存在
ps -ef | grep tomcat
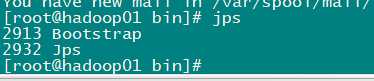
可以使用专门查看java进程的命令有bootstap即可:jps
关闭服务器:halt
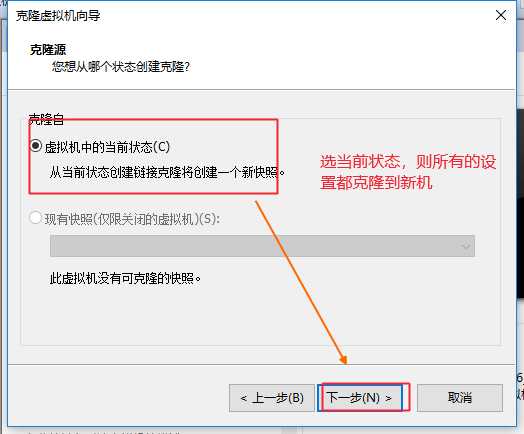
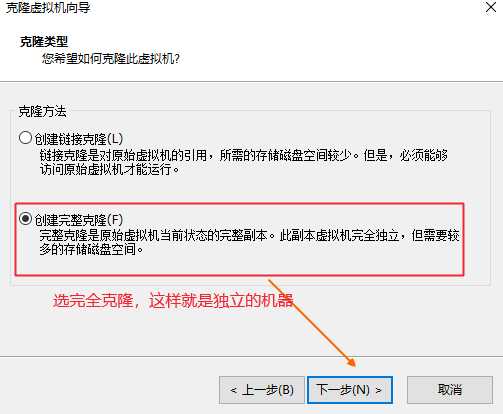
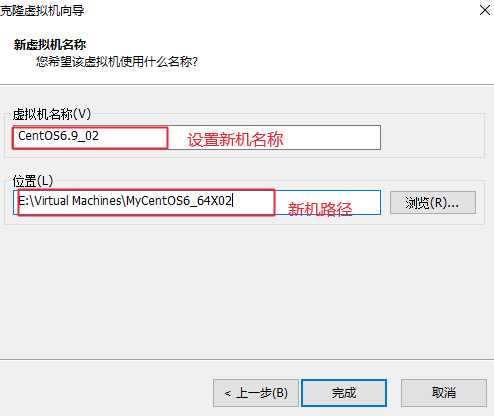
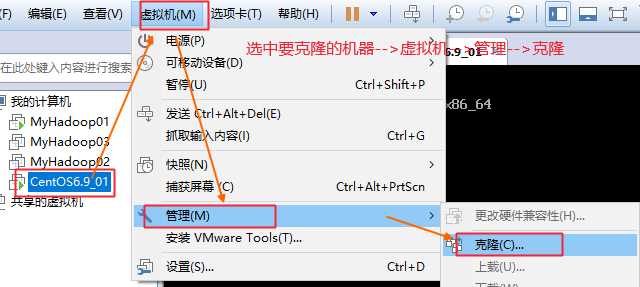
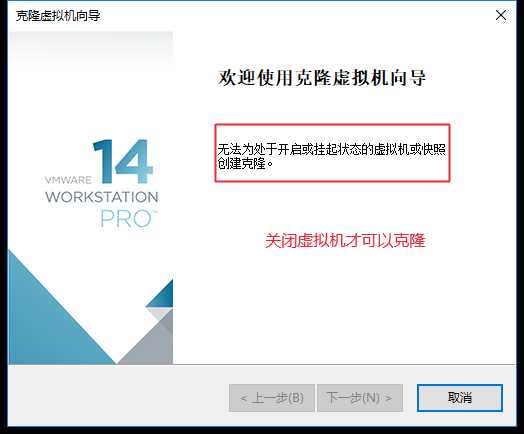
可以克隆多几份,另外做到ssh免密登录前可以先克隆一个留作备份,以防后面再次安装
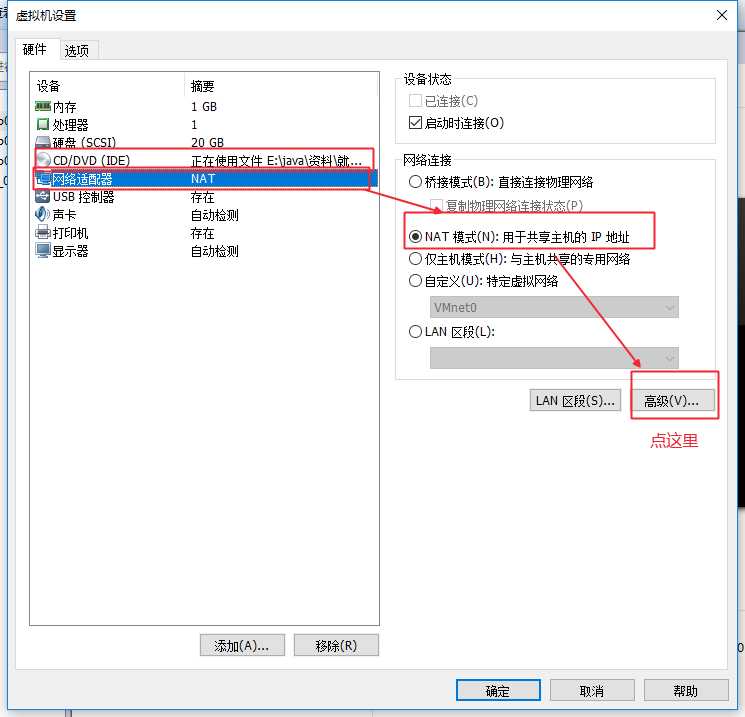
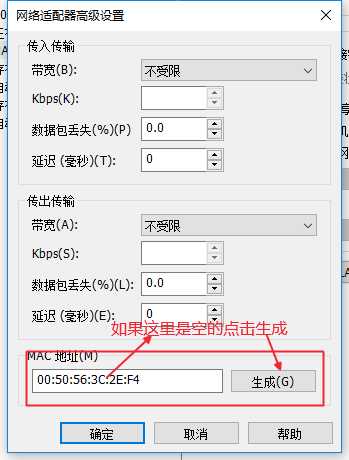
1、 网络配置:开启虚拟机前,先生成Mac地址。

vim /etc/sysconfig/network-scripts/ifcfg-eth0;vim /etc/udev/rules.d/70-persistent-net.rules删除eth0,改名eth1为eth0
重启网卡服务:service network restart
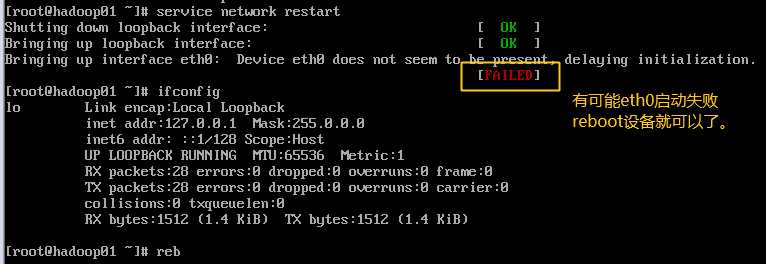
注意修改主机名后再reboot
2、 防火墙是否关闭:cat /etc/sysconfig/iptables
3、 Selinux是否关闭:cat /etc/selinux/config
4、 JDK环境:java -version
5、 启动tomcat:cd /export/servers/apache-tomcat-7.0.57/bin。Reboot后IP生效才可用
./startup.sh
6、 修改主机名称。vim /etc/sysconfig/network
7、 Ssh免密登录设置。
第一步: ssh-keygen -t rsa 在每一台机器(如果已经安装了多台设备)上面都要执行,产生公钥和私钥
第二步:在其他已安装的设备上执行:ssh-copy-id hadoop1(没有设置主机IP映射前使用IP链接) 将其他机器的公钥拷贝到hadoop1(同一台设备)上面去
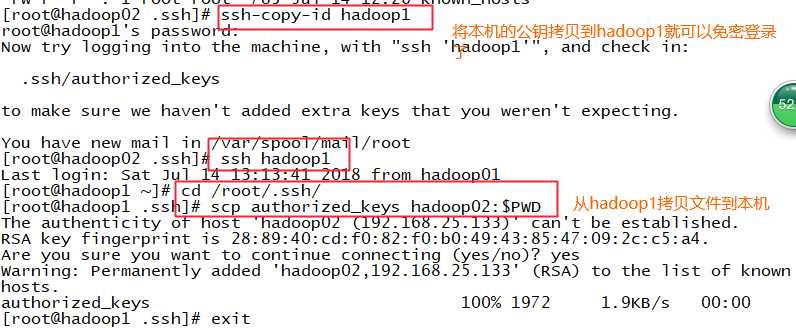
第三步:将第一台的文件拷贝到其他机器上去
scp authorized_keys hadoop2:$PWD
scp authorized_keys hadoop3:$PWD
注意其他机器的主机与IP映射页要同步设置。

出现这个问题是 know_host文件里面没有其他主机的内容,把其中能连上所有的设备的host的know_host文件也同步拷贝给其他链接不上的主机。
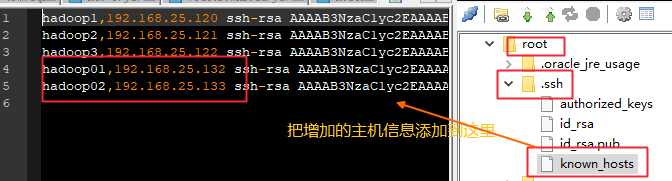
或者在其他设备执行命令:
scp know_hosts hadoop3:$PWD
如果现有的机器已经安装有了,则从第二步开始。
cd /export/softwares
tar -zxf zookeeper-3.4.9.tar.gz -C ../servers/
cd /export/servers/zookeeper-3.4.9/conf
cp zoo_sample.cfg zoo.cfg
mkdir -p /export/servers/zookeeper-3.4.9/zkdatas
vim zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/export/servers/zookeeper-3.4.9/zkdatas
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenanc
# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
autopurge.purgeInterval=1
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
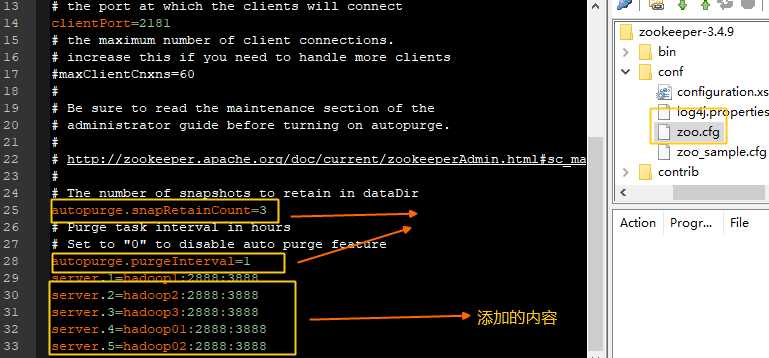
创建myid,并且赋值为1
echo 1 > /export/servers/zookeeper-3.4.9/zkdatas/myid
cd /export/servers/zookeeper-3.4.9/zkdatas/
使用命令more myid查看myid的值是否为1
在第一台机器执行以下命令
cd /export/servers
scp -r zookeeper-3.4.9/ hadoop02:/export/servers
scp -r zookeeper-3.4.9/ hadoop01:$PWD
第二台机器执行命令:把更改的值添加
echo 2 > /export/servers/zookeeper-3.4.9/zkdatas/myid
第三台机器 执行命令:
echo 3 > /export/servers/zookeeper-3.4.9/zkdatas/myid
。。。。。
多台机器都要执行以下命令来启动zk集群
cd /export/servers/zookeeper-3.4.9
bin/zkServer.sh start
每台机器执行以下命令,确认集群启动成功
bin/zkServer.sh status
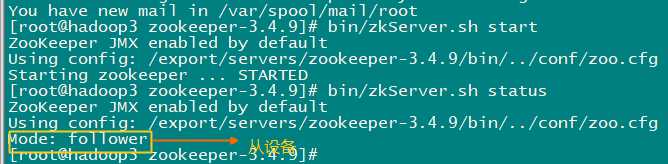
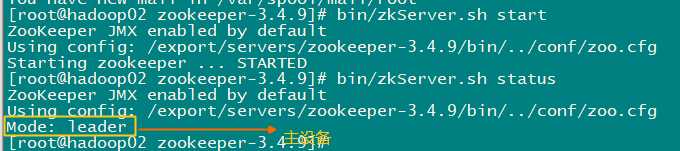
注意:zk严重依赖时钟同步,最好要确保每台机器的时钟误差在5S以内
solrCloud部署依赖zookeeper,需要先启动每一台zookeeper服务器。
修改每个solr的solr_home下的solr.xml文件。
vim /export/servers/solr_home/solr/solr.xml
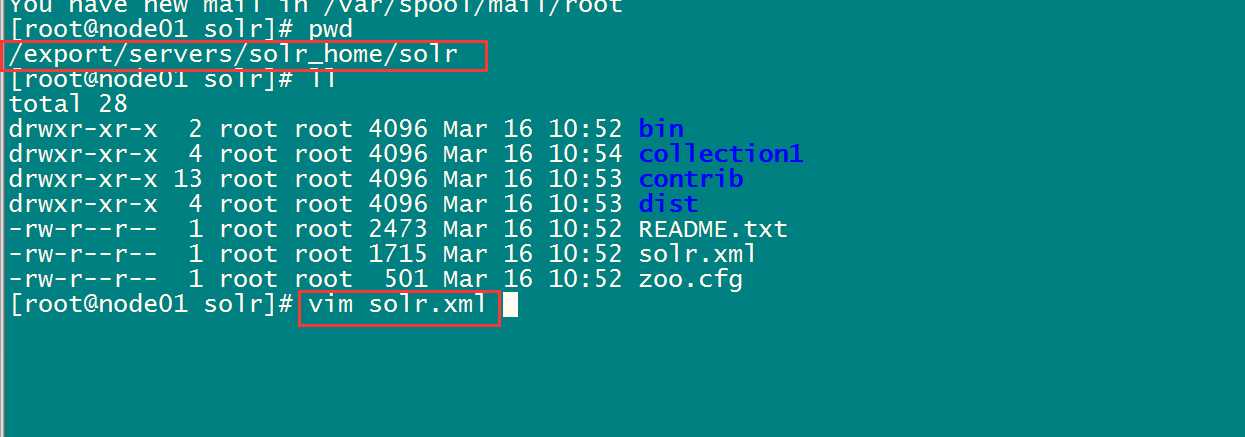

修改每一台solr的tomcat 的 bin目录下catalina.sh文件中加入DzkHost指定zookeeper服务器地址:
cd /export/servers/apache-tomcat-7.0.57/bin
vim catalina.sh

|
export JAVA_OPTS="-Dsolr.solr.home=/export/servers/solr_home/solr -DzkHost=hadoop(主机名称):2181,node02:2181,node03:2181" |
export JAVA_OPTS="-Dsolr.solr.home=/export/servers/solr_home/solr -DzkHost=hadoop
01:2181,hadoop02:2181,hadoop1:2181,hadoop2:2181,hadoop3:2181"
也可以修改一台后使用SCP覆盖其他两台的catalina.sh。
|
scp -r solr_home/ (主机名)hadoop2(IP地址也可以):$PWD scp -r solr_home/ hadoop3:$PWD
cd /export/servers scp -r apache-tomcat-7.0.57/ solr_home/ node02:$PWD scp -r apache-tomcat-7.0.57/ solr_home/ node03:$PWD |
由于zookeeper统一管理solr的配置文件(主要是schema.xml、solrconfig.xml), solrCloud各各节点使用zookeeper管理的配置文件。以后无论创建任何的core,本地的配置文件都没用了,使用的都是zookeeper的配置文件,先部署zookeeper在部署其他。看课堂笔记
在第一台机器切换到:
/export/servers/solr-4.10.2/example/scripts/cloud-scripts 这个路径下,执行以下命令,将所有solr的配置文件上传到zk上
执行下边的命令将/home/solr/solrhome/conf下的配置文件上传到zookeeper:
./zkcli.sh -zkhost node01(主机名称):2181,node02:2181,node03:2181 -cmd upconfig -confdir /export/servers/solr_home/solr/collection1/conf/ -confname solrconf

./zkcli.sh -zkhost hadoop1:2181,hadoop2:2181,hadoop3:2181 -cmd upconfig -confdir /export/servers/solr_home/solr/collection1/conf/ -confname solrconf
登陆zookeeper服务器查询配置文件:
./zkCli.sh
部署完成后可以通过zookeeper可视化工具连接一下查看。
启动每一台solr的tomcat服务。Tomcat目录下的Bin/startup.sh
cd /export/servers/apache-tomcat-7.0.57
bin/startup.sh
执行后可以jps查看一下进程。
http://192.168.25.120:8080/solr/
访问任意一台solr,左侧菜单出现Cloud:
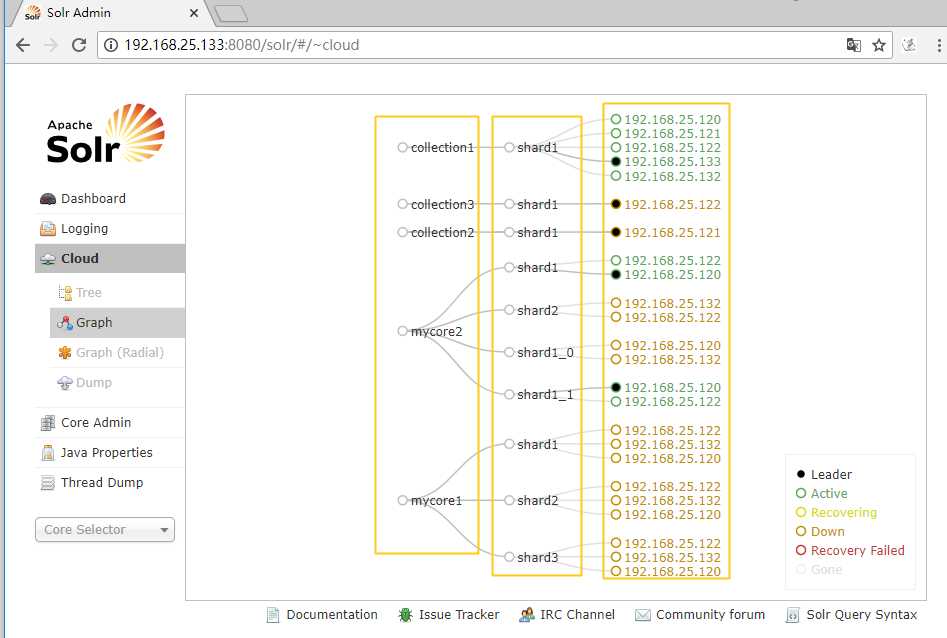
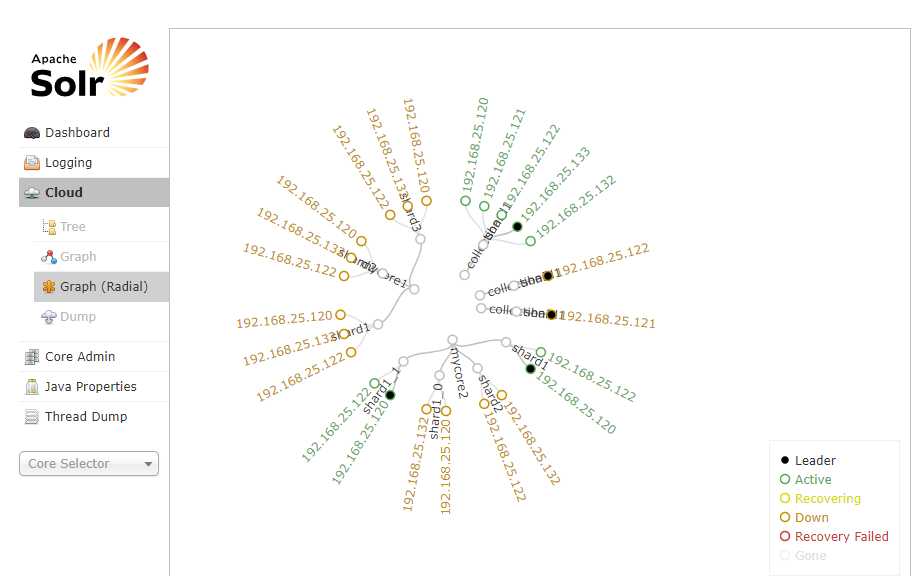
上面的关系图中有5个核,对应5台服务器,其中120网段的是已有的集群,132网段的是本教程新添的两个服务器。如果你们按照本教程安装步骤安装的话,可能与上图不一样,但是基本的core、shard、服务器都会有的。
标签:编辑器 需要 目录 获取ip 编辑 nod 部署 inux .gz
原文地址:https://www.cnblogs.com/hwe-sinen/p/9310770.html