标签:tar 学习 www. 标记 集合 技术 权重 target 最大

欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习、深度学习的知识!也可以搜索公众号:磐创AI,关注我们的文章。
作者:磐石
一、简述
聚类是对探索性数据分析最广泛使用的技术,在现在各个科学领域中处理没有类标的数据时,人们总是想通过确定数据中不同样本的归类,来获取对数据的直观印象。传统的聚类方法有很多,像K-means,single linkage等,但是k-means算法有些缺点,比如当样本维度特别大的时候,k-means的计算量是很大的。最近几年时间,谱聚类成为了最受欢迎的聚类算法,它很容易执行,能够用标准的线代软件高效地解决,而且比传统的聚类算法比如k-means表现效果要好很多。不管怎样,初次一瞥谱聚类时看起来很神秘,不太能弄透为什么谱聚类能够用于聚类。为了介绍谱聚类到底如何能够作聚类,我们需要先了解相似度矩阵,拉普拉斯矩阵的概念,然后才能最终理解谱聚类原理。
二、图相关的符号标记
现有给定样本x_1,……x_n,想要用谱聚类来给这些样本集进行聚类的话,需要将这些样本之间的联系用图的形式来表示。在这里介绍下图的相关符号。假设有若干个样本x_i被归为一类,该集合为A。这里先给出相关需要的概念,刚看到不理解不用担心,先记住他们是做什么的就行。
设定:
1)谱聚类中,我们需要描述样本与样本间的联系,这时候需要构建一个图。G=(V,E)是一个无向图,其中V={v_1,…,v_n}代表这些样本点,E是代表不同点之间相似度,其中e_ij代表v_i与v_j之间的权值(有多种方式构建此相似度),用w_ij表示,其中w_ij>=0,构成了邻接矩阵W(两样本v_i与v_j之间有连接则w_ij>0,无连接则w_ij=0),因为G是无向图,所以可知道w_ij=w_ji。
2)度矩阵D,其中,代表v_i样本与其他v_j样本的权重之和。
三、相似度矩阵S
谱聚类算法需要的输入是一个图,该图包含了所有样本与样本之间的相似度,该图为一个矩阵,大小是n*n。这样通过某种标准定义了样本之间联系构建出来的矩阵,我们叫做它相似度矩阵。有很多种构建相似度矩阵的方式,比如K近邻构建的相似度矩阵,高斯相似度矩阵等,eg:用高斯相似度S(x,y)计算两样本间的联系时:

其他相似度构造标准在此不再详细阐述,你需要知道,这些不同的构建相似度矩阵的方式,他们有各自对样本间相似度的构建标准,通过他们,给定的样本就能变成一个相似度矩阵S,S_ij代表样本v_i与v_j之间相似度,这里的出的S_ij矩阵其实就是用作于后边的W_ij邻接矩阵。这里需要指出的是,目前还没有理论结果指明在不同的数据训练中使用哪种方案构建相似度矩阵最合适。
四.拉普拉斯矩阵L性质
谱聚类中最重要的工具就是拉普拉斯矩阵,在这里我们给出拉普拉斯矩阵的定义和一些他的重要性质。之前上文已经给出了一些相关符号的定义,我们已经根据不同的相似度标准求出了样本与样本之间的相似度,构建了邻接矩阵W。这里我们也知道了度矩阵D:
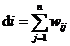
而谱聚类中所需要的最重要的拉普拉斯矩阵L:
L=D-W
拉普拉斯矩阵有如下的一些重要性质:
以上就是拉普拉斯矩阵L所具有的一些重要的性质,证明比较多,本次讲解就不详细展开,以后会将其单独罗列出来并讲下谱聚类更深入的细节,体会下当初发明人多么巧妙的用拉普拉斯矩阵去解决样本的均匀聚类问题。
五.谱聚类算法
将所有的样本构建成一个图,x_i与x_j之间的关联程度构建了图对应的边。那现在我们就得到了一个图,图上有所有样本和样本间的联系。谱聚类算法是对这个图进行合理的切分,分成几类,这样切分得到的每类都比较均匀。
输入:样本x_i,需要聚类的个数k
输出:k个类,每个样本标记聚成的类别。
谱聚类切割出来的图的特点,他会让所切分的样本构建的图比较均匀。
六.总结
本次只是简单的阐述了下谱聚类所需要的一些相关和算法流程。想要对样本进行合理的切割,用谱聚类算法相对于传统的k-means算法会更高效,聚类的效果会均匀。谱聚类需要先将样本通过某种标准计算出样本间的相似度构建成相似度矩阵,也就是邻接矩阵。然后计算拉普拉斯矩阵,求出拉普拉斯矩阵对应的前k个最小的特征值,得到对应的特征向量组成的矩阵V后,用V来给样本在低维度上进行聚类,相比k-means直接对样本聚类会更快。刚开始你需要先了解谱聚类的整个运作流程。然后再带着这个流程去分析每一部分会更好理解些。本次讲解并没有涉及深层次的原理,比如为什么用拉普拉斯矩阵能够解决图的均匀分割问题,拉普拉斯矩阵的这些性质怎么得来的,并且直观上这些性质意味着什么。我会在下次详细讲解这些性质的由来,并讲解通过拉普拉斯矩阵如何去巧妙地解决聚类问题。
最后,对深度学习感兴趣,热爱Tensorflow的小伙伴,欢迎关注我们的网站!http://www.tensorflownews.com。我们的公众号:磐创AI。
标签:tar 学习 www. 标记 集合 技术 权重 target 最大
原文地址:https://www.cnblogs.com/lm3306/p/9314046.html