标签:字典 ipc 流程 开发 先后 tcp传输 输入 为什么 命令
首先tcp协议又叫流式协议。tcp协议有一种机制,就是将数据量小和间隔时间较短的,比如几次数据,就会当作一次发送过去。这样能减少多次传输的所浪费的网络延迟,这样提示的tcp传输数据的效率,但是这样也会出现粘包现象。所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
这里提醒一点,只有tcp协议才会有粘包现象,upd永远不会有粘包现象。这里说下,upd是数据报协议,由报头和数据组成,报头是有固定的长度,里面包括一系列的信息等。
之前我也提到,conn.recv(1024)只能接收最大1024大小的字节,要是我发送的是大于1024字节的信息呢,会出现什么情况,最开始我们接收1024字节,剩下的数据,就在操作系统里保存着,下次接收再从操作系统里去取。
下面来个例子吧:
服务端端代码:
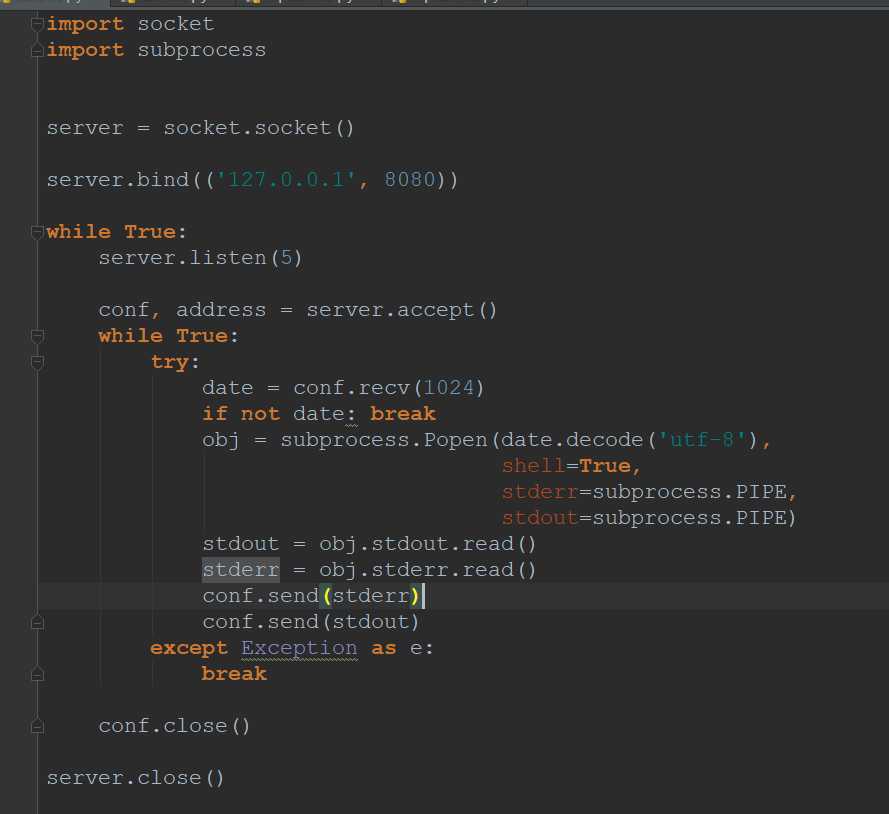
客户端代码:
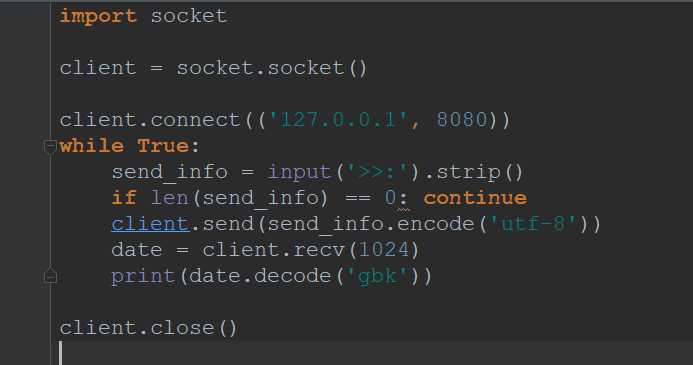
上面我贴出例子的代码,然后先后运行服务端,客户端
并在客户端中输入cdm的命令操作,比如简单的 dir ipconfig
下面是执行结果:
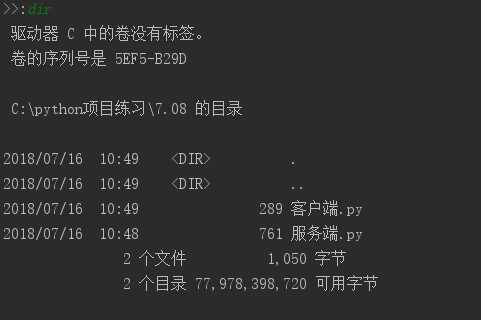

我们可以完整的接收到服务端发过来的信息,因为这些数据都是小于1024字节的。
我们再来看看这条命令,查看windows系统下的进程:tasklist
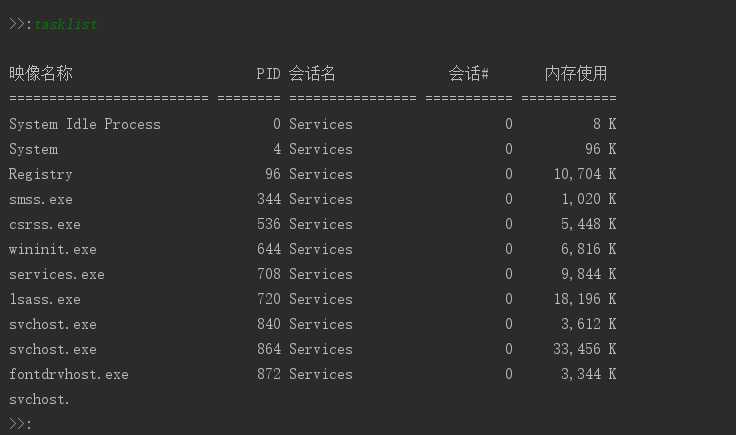
很明显我们接收到的数据不完整,我们再执行一下dir命令:
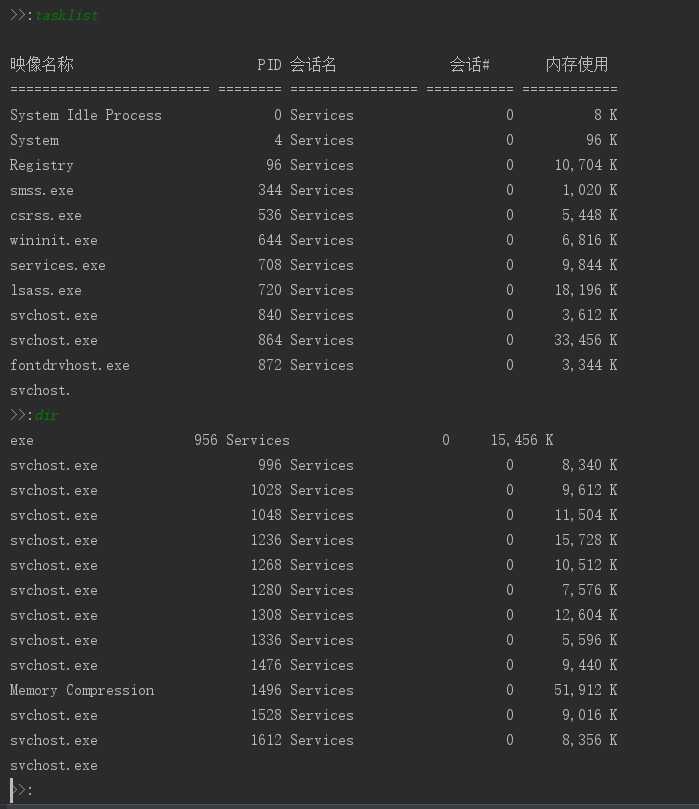
分析:基于上面输入完tasklist,我们再输入dir ,就会出现这种情况,数据根本就不是我么想要的,这就是粘包现象。
解决:这是客户机发送数据到服务机,这数据的流动流程
客户机上面的应用软件,将发送的数据丢给操作系统,操作系统通过调动硬件,将0101101这种二进制通过网线发给服务端的硬件,服务端的将接收到的信息存放在缓存内存中,服务端软件向操作系统要,操作系统就将数据发送给软件。为什么会出现上面的现象,就是因为客户端发送的字节大于1024,而服务端一次就收了1024,剩下的就是缓存空间里,下次再取的就是取上次没有取完的数据。
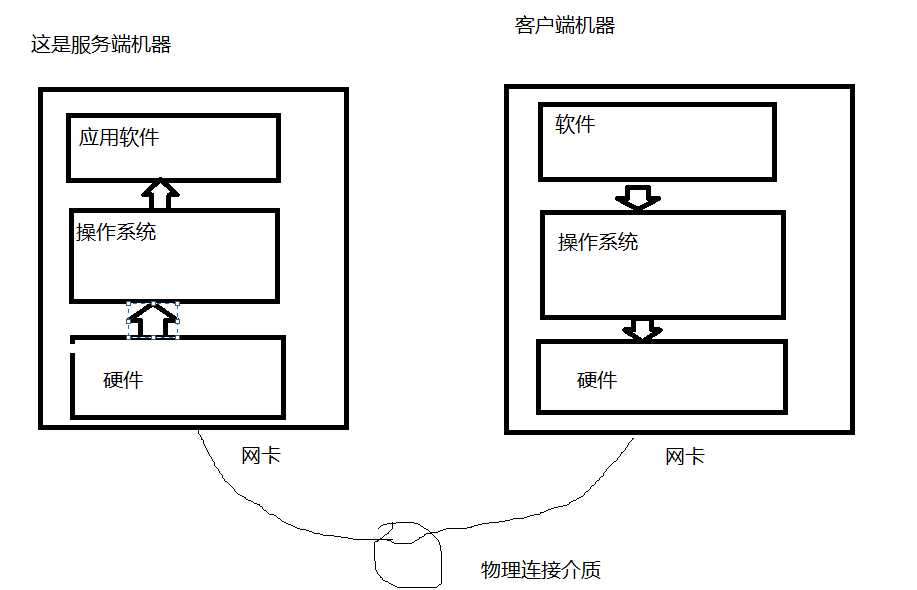
解决这是问题要服务端知道客户端发送数据的大小,他发多少我就接收多少,可以通过循环去实现大于1024字节的数据,如何明确知道呢?因为这软件是我们自己开发的,所以我们可以自己定义规则。
我们在发送真是数据之前,可以先向服务端发送一个类似报头一样的数据,里面有一系列关于数据的信息。定义报头首先就是要固定长度,我们可以通过struck这个模块去固定报头长度。下面我写写代码。
发送数据的方法
import struck,json
dic = {‘size‘:你要发送信息的长度,....可以自己看情况加}
info_json = json.loads(dic) #转化成json中间格式
info_bytse = info_json.encode(‘utf-8‘) #转成二进制
client.send(struck.park(‘i‘),len(info_bytse)) # 我们先发送4个字节大小的报头过去,里面有数据的信息 可以去看看struck模块怎么用
client.send(info_bytes) #发送自定义报头数据
client.sent(发送你要发送的真实数据) #记住是二进制
接收数据的方法
import struck,json
data = conn.recv(4) # 先收取4个字节,里面包含一些报头的信息,记住不是报头数据
heard_len = struck.unpark(‘i‘,data) [0] #通过这个我们知道报头数据的长度,然后我们再接收报头
heard_bytes = conn.recv(heard_len) #这就是报头的数据
heard_json = heard_bytes.decode(‘utf-8‘)
heard_info = json.dumps(heard_json) #得到报头那个字典
a_size = 0
b_size = heard_info[‘size‘] #文件长度
res = b‘‘
while a_size<b_size :
data = conn.recv(1024)
res += data
a_size += len(data)
print(data.decode(‘utf-8‘))
服务端客户端都可以这样,这样的话,就不会出现粘包现象,也能接收到完整的信息。
上面都是自己的理解,有错误的话可以提醒下。
标签:字典 ipc 流程 开发 先后 tcp传输 输入 为什么 命令
原文地址:https://www.cnblogs.com/zhuchunyu/p/9317137.html