标签:需要 1.0 架构 asto 核心 行数据 use 解释器 mapr
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。用户可以利用Hadoop轻松的组织计算机资源,从而搭建自己的分布式计算平台,并且可以充分利用集群的计算和存储能力,完成海量数据的处理。
Hadoop具有高可靠性、高扩展性、高效性、高容错性的特点:
1, 高可靠性:Hadoop按位存储和处理数据。
2, 高扩展性:Hadoop是在可用的计算机集簇间分配数据完成计算任务,这些集簇可以方便地扩展到数以千计的节点中。
3, 高效性:Hadoop能够在节点之间动态移动数据以保持节点间的平衡,因此其处理速度够快。
4, 高容错性。Hadoop能够自动保存数据的多份副本,能够将失败的任务重新分配。
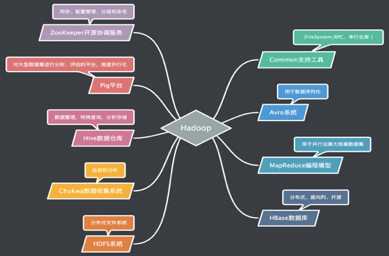
目前,Hadoop已经发展成包含很多项目的集合。虽然其核心内容是MapReduce和HDFS,但是与Hadoop相关的其他项目也是不可或缺的。
MapReduce数据流图:
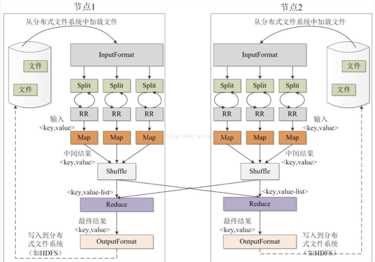
如图所示,一个MapReduce作业通常会把输入的数据集切分,由Map函数并行处理。框架会先对Map的输出进行排序(Shufile),然后把结果输入给Reduce任务。通常作业的输入和输出都会被存储在文件系统HDFS中。
MapReduce框架由一个单独的Master JobTracker 和集群节点上的Slave TaskTracker共同组成。Master负责调度、监视构成一个作业的所有任务,将这些任务分布在不同的Slave上。
在Hadoop上运行的作业需要设置路径,并通过实现合适的接口或抽象类提供Map和Reduce函数。在Hadoop的JobClient提交作业和配置信息给JobTracker之后,JobTracker会负责分发这些信息给Slave及调度任务,并监控它们的执行,同时提供状态和诊断信息给JobClient。
HBase是一个类似于Bigtable的分布式数据库。是一个稀疏的、长期存储在硬盘上的、多维度的排序映射表,这张表的索引是行关键字、列关键字和时间戳。
HBase在分布式集群上主要依靠由HRegionServer(域服务器)、HBaseMaster(主服务器)、HBaseClient(客户端)组成的体系结构从整体上管理数据。主服务器作为HBase的中心,管理整个集群中的所有域,监控每台域服务器的运行情况;域服务器接收来自服务器的分配域,处理客户端的域读写请求并回写映射文件等;客户端主要用来查找用户域所在的域服务器地址信息。
Hive是建立在Hadoop上数据仓库式的基础架构。提供了一系列工具用来进行数据的提取、转化、加载。并定义了简单的类SQL查询语言Hive QL。作为数据仓库,Hive的数据管理按照使用层次可以从元数据存储、数据存储和数据交换三方面介绍:
1,元数据存储:Hive将元数据存储在RDBMS中,有三种模式可以连接到数据库:
Single User Mode:一般用于Unit Test
Multi User Mode:通过网络连接,最常用
Remote Server Mode:用于非Java客户端访问元数据库,客户端利用Thrift协议通过MetaStoreServer来访问元数据库
2,数据存储:Hive没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由地组织Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,就可以解析数据。Hive中有4种数据模型:Table、External Table、Partition和Bucket。值得一提的是,每个Table在Hive中都有一个相应的目录来存储数据
3, 数据交换:数据交换主要分为【用户接口】,【元数据存储】,【解释器、编译器、优化器、执行器】,【Hadoop(利用HDFS进行存储,利用MapReduce进行计算】
用户接口:客户端,数据库接口,web界面
Hive将元数据存储于数据库中,如MySQL,Derby中。元数据包括表的名字,表的列,表的分区,表分区的属性,表的属性,表的数据所在目录等
解释器、编译器、优化器、执行器完成Hive QL语句的执行。
Hive的数据存放于HDFS,大部分的查询由MapReduce完成。值得一提的是,包含*的查询不会生成MapReduce任务,如:select * from tbl。
Hadoop能够将普通PC组织成能够高效稳定处理事务的大型集群,如好保证Hadoop集群的安全是必须解决的问题。安全管理是Hadoop中最复杂的、最难懂和最晦涩的模块,涉及到Hadoop的各个分支和每个分支的各个服务与组件,为了方便大家详细了解Hadoop内部的安全机制实现和各个验证流程,Apache正在编写一个文档,具体可参考HADOOP-9621,一般而言,系统安全机制由认证(authentication)和授权(authorization)两大部分构成。认证就是简单地对一个实体的身份进行判断;而授权则是向实体授予对数据资源和信息访问权限的决策过程。同Hadoop 1.0一样,Hadoop 2.0中的认证机制采用Kerbero和Token两种方案,而授权则是通过引入访问控制列表(Access Control List,ACL)实现的。
标签:需要 1.0 架构 asto 核心 行数据 use 解释器 mapr
原文地址:https://www.cnblogs.com/hhhh-ighsenberg/p/9319936.html