标签:根据 实现 .com learn 最小 标准 logistic 标记 解决方案
from sklearn.processing import StandardSacler
sc=StandardScaler() #实例化
sc.fit(X_train)
sc.transform(X_train)
# - 以上两句可以并写成一句sc.fit_transform(X_trian)
# - 我们使用相同的放缩参数分别对训练和测试数据集以保证他们的值是彼此相当的。**但是在使用fit_transform 只能对训练集使用,而测试机则只使用fit即可。**
# - sklearn中的metrics类中包含了很多的评估参数,其中accuracy_score,
# - 中accuracy_score(y_test,y_pred),也就是那y_test与预测值相比较,得出正确率
y_pred=model.predict(X_test-std)过拟合现象出现有两个原因:

感知机的一个最大缺点是:在样本不是完全线性可分的情况下,它永远不会收敛。
分类算中的另一个简单高效的方法:logistics regression(分类模型)

特定的事件的发生的几率,用数学公式表示为:$\frac{p}{1-p} $,其中p为正事件的概率,不一定是有利的事件,而是我们将要预测的事件。以一个患者患有某种疾病的概率,我们可以将正事件的类标标记为y=1。


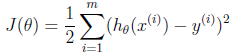











参考文献:
标签:根据 实现 .com learn 最小 标准 logistic 标记 解决方案
原文地址:https://www.cnblogs.com/onemorepoint/p/9321199.html