标签:过程 需要 map 本地磁盘 http 完成 任务 大数 流程
Hadoop的mapreduce是一个快速、高效、简单用于编写的并运行处理大数据程序并应用在大数据集群上的编程框架。它将复杂的、运行于大规模集群上的并行计算过程高度的抽象到两个函数:map、reduce。适用于MP来处理的数据集(或者任务),需要满足一个基本的要求:待处理的数据集可以分解成许多小的数据集额,而且每一个小数据集都可以完全并行的进行处理。
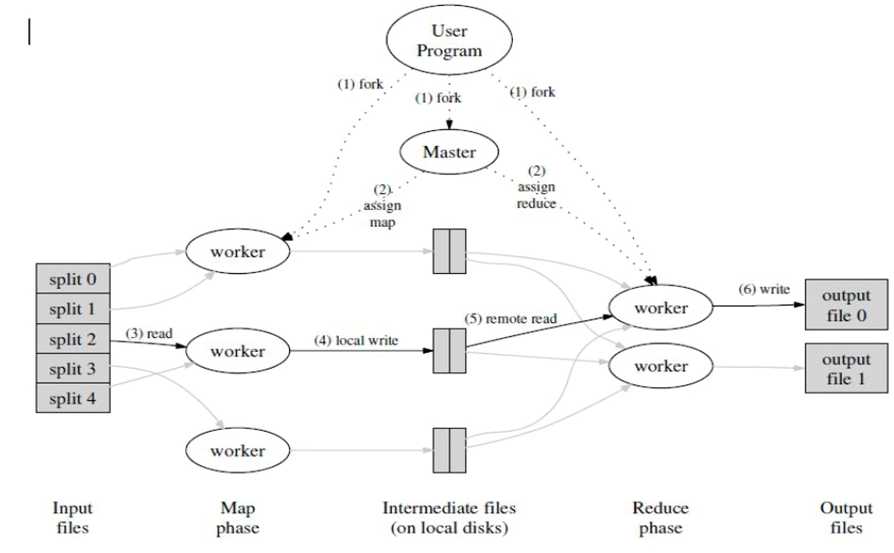
图1.2-1MP框架数据流
MP框架包括一个主节点(ResourceManager)、多个子节点(运行NodeManager)和MRAppMaster(每个任务一个)共同组成。
针对上面的流程图可以分为两个阶段来描述:
(1)MAP阶段
1)input根据输入文件产生键值对,并传送到Mapper类的MAP函数中;
2)map输出键值对到一个没有排序的缓冲内存中;
3)当缓冲内存到给定值或者map的任务完成后,在缓冲内存中的键值对就会被排序,然后输出到磁盘中溢出文件;
4)如果有多个溢出文件,那么就会整合这些文件到一个文件中,且是排序的;
5)这些排序过的、在溢出文件中的键值对会等待reduce的获取。
(2)Reduce阶段
1)reduce获取map的记录,然后产生另外的键值对,最后输出到HDFS中;
2)shuffe:相同的key被传送到同一个reduce中
3)当有一个mapper完成后,reduce就开始获取相关数据,所有的溢出文件就会被整合排序到一个内存缓冲区
4)当内存缓冲区满了后,就会溢出文件到本地磁盘
5)当reduce所有相关的数据都传输完后,所有溢出文件就会被整合和排序
6)Reducer中reduce方法针对每个key调用一次
7)Reduce的输出到hdfs
标签:过程 需要 map 本地磁盘 http 完成 任务 大数 流程
原文地址:https://www.cnblogs.com/sirlijun/p/9326253.html