标签:udt nsf image rdd http cto 假设 sse 临时
| 软件 | 版本 |
|---|---|
| Spark | 1.6.0 |
| Hive | 1.2.1 |
在使用Spark时,有时需要存储DataFrame数据到Hive表中,一般的存储方式如下:
// 注册临时表
myDf.registerTempTable("t1")
// 使用SQLContext从临时表创建Hive表
sqlContext.sql("create table h1 as select * from t1")
在DataFrame中存储一般的数据类型,比如Double、Float、String等到Hive表是没有问题的,但是在DataFrame中还有一个数据类型:vector , 如果存储这种类型到Hive表那么会报错,类似:
org.apache.spark.sql.AnalysisException: cannot resolve ‘cast(norF as struct<type:tinyint,size:int,indices:array<int>,values:array<double>>)‘
due to data type mismatch: cannot cast org.apache.spark.mllib.linalg.VectorUDT@f71b0bce to StructType(StructField(type,ByteType,true), StructField(size,IntegerType,true), StructField(indices,ArrayType(IntegerType,true),true), StructField(values,ArrayType(DoubleType,true),true));
这个错误如果搜索的话,可以找到类似这种结果: Failed to insert VectorUDT to hive table with DataFrameWriter.insertInto(tableName: String)
也即是说暂时使用Spark是不能够直接存储vector类型的DataFrame到Hive表的,那么有没有一种方法可以存储呢?
想到这里,那么在Spark中是有一个工具类VectorAssembler 可以达到相反的目的,即把多个列(也需要要求这些列的类型是一致的)合并成一个vector列。但是并没有相反的工具类,也就是我们的需求。
这里提出一个解决方法如下:
假设:
1. DataFrame中数据类型是vector的列中的数据类型都是已知的,比如Double,数值类型;
2. vector列中的具体子列个数也是已知的;
有了上面两个假设就可以通过构造RDD[Row]以及schema的方式来生成新的DataFrame,并且这个新的DataFrame的类型是基本类型,如Double。这样就可以保存到Hive中了。
本例流程如下:
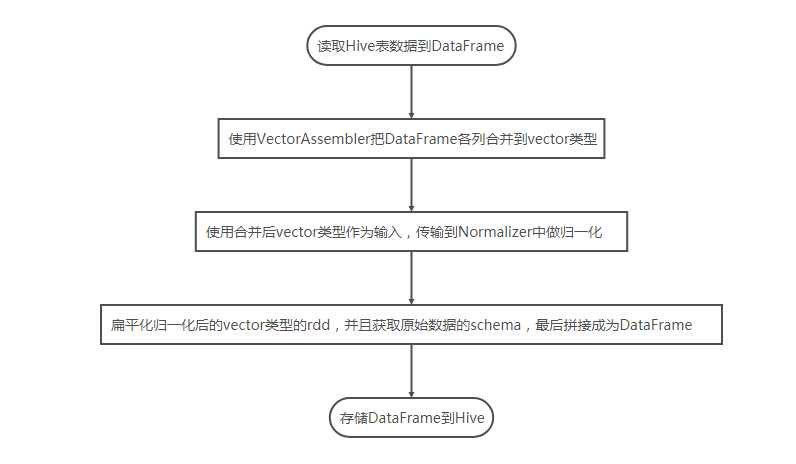
代码如下:
// 1.读取数据
val data = sqlContext.sql("select * from normalize")
读取数据如下:

// 2.构造vector数据
import org.apache.spark.ml.feature.VectorAssembler
val cols = data.schema.fieldNames
val newFeature = "fea"
val asb = new VectorAssembler().setInputCols(cols).setOutputCol(newFeature)
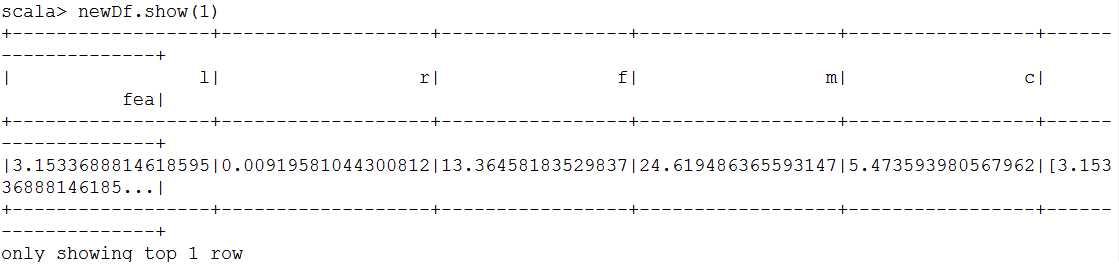
val newDf = asb.transform(data)
newDf.show(1)
// 3.做归一化
import org.apache.spark.ml.feature.Normalizer
val norFeature ="norF"
val normalizer = new Normalizer().setInputCol(newFeature).setOutputCol(norFeature).setP(1.0)
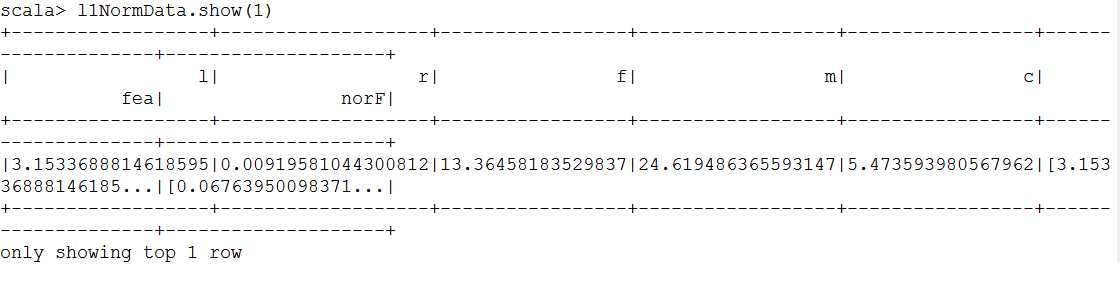
val l1NormData = normalizer.transform(newDf)
l1NormData.show(1)
// 存储DataFrame vector类型报错
// l1NormData.select(norFeature).registerTempTable("t1")
// sqlContext.sql("create table h2 as select * from t1")
// 4.扁平转换vector到row
import org.apache.spark.sql.Row
val finalRdd= l1NormData.select(norFeature).rdd.map(row => Row.fromSeq(row.getAs[org.apache.spark.mllib.linalg.DenseVector](0).toArray))
val finalDf = sqlContext.createDataFrame(finalRdd,data.schema)
finalDf.show(1)

// 5. 存储到Hive中
finalDf.registerTempTable("t1")
sqlContext.sql("create table h1 as select * from t1")

Spark DataFrame vector 类型存储到Hive表
标签:udt nsf image rdd http cto 假设 sse 临时
原文地址:https://www.cnblogs.com/itboys/p/9332574.html