标签:相关系数 特征 相同 相关 osi 归一化 let diff vgg
(1)人脸验证(face verification):1对1,输入一个照片或者名字或者ID,然后判断这个人是否是本人。
(2)人脸识别(face recognition):1对多,判断这个人是否是系统中的某一个人。
(1)比如一个公司的员工,一般每个人只给一张工作照(如4个人),这时网络输出五个单元,分别代表他们以及都不是。这样设计会有两个明显的问题:第一是每个人只给了一张照片,训练样本太少;第二是如果这时候又来了一个员工,那么网络的输出得重新调整,显然不合理。
(2)实际使用的方法,是训练一个差异度函数(degree of difference between images)的网络,给网络输入两张照片,如果是同一个人则输出很小的值(差异很小),如果不是同一个人则输出很大的值,这时只要将来的人与系统中的照片逐一比较即可。同时如果来了新员工,也只需要将他的照片放入到系统中就可以了。
(1)Siamese的输出不经过softmax激活函数做分类,直接就是输出一个向量,相当于把每个人映射成一个向量,然后判断两张图片是否是同一个人时只需要,分别输入这同一个网络,然后求输出向量的范数,如下所示:
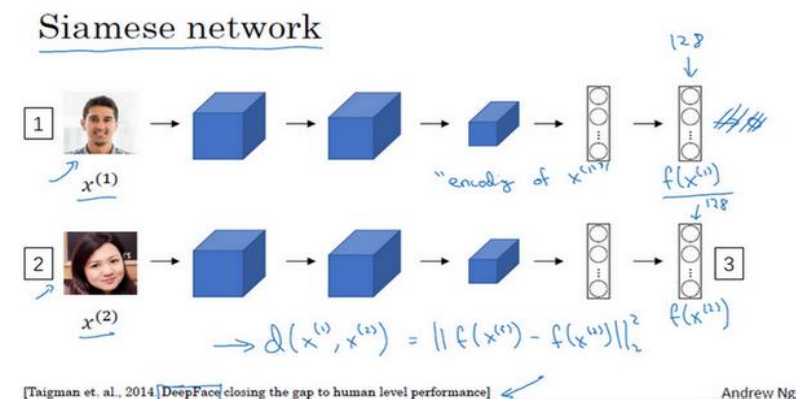
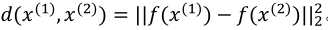
(1)首先训练集中必须有相同人的照片(网络应用的时候没这个要求),三张照片为一组(分别叫做Anchor,Positive,Negative),如下图所示:

(2)损失函数如下,将两张相同的图片的距离比两张不同图片的距离的差值(注意此处差值已经是一个负值了)小于某个阈值时,其误差视为0:
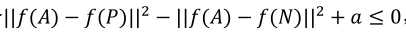
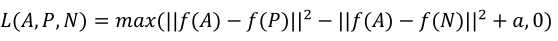
(1)可以用二分类的思想来训练上面的Siamese网络,同样是用同一个网络,输出两张照片的向量,这时候在后面将向量对应元素做差的绝对值作为一个特征,再创建一层逻辑回归即可,输出0、1,如下等式所示:
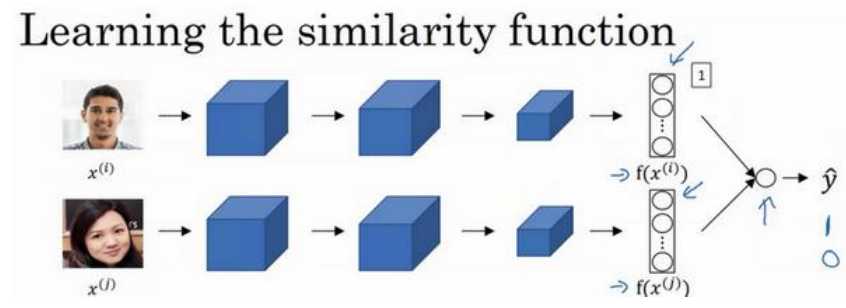
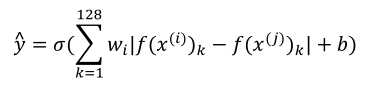
(2)用这种方法训练网络,每次是使用两张照片,而不是三张照片了。
(3)不管是上面提到的两种训练方式的哪一种,当在应用网络的时候,不需要在系统中存储大量的照片,可以提前把照片输入网络计算出来的向量存在系统中即可,这样在实际应用时就非常的快乐。
(1)下面就是一个风格转换的例子,左边是内容图(C),右边是风格图(S),下面是生成图(G)

(1)浅层检测到简单的一些边缘,越到后面,图形越来越复杂。

(1)相似度越好,代价函数越小,所以就是最小化下面的代价函数,包括内容相似度和风格相似度,(α,β是调节两者的权重,其实一个就够了):
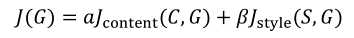
(2)生成图G一开始就是随机初始化,下面是生成图随着最小化代价函数的变化过程(其中1是内容图,2是风格图):

(1)用隐含层l来计算内容代价,如果l是一个很小的数,比如说隐含层1,这个代价函数就会使你的生成图片像素上非常接近你的内容图片。如果你用非常深的层,那么如果内容图上有狗,那么它就会确保生成图片里面有一只狗。所以在实际中,这个l既不会选择太浅也不会选择太深。用预训练的VGG网络模型。取中间的l层,这时将内容图与生成图分别输入到VGG中得到第l层的激活值,然后求其相似度,就是按元素对应相减:
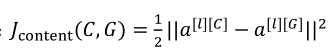
(1)需要着重理解:一个通道是由一个卷积核卷积生成的,假如这个卷积核擅长识别垂直的线段,那么这个通道将会有很多垂直线段,另一个通道的卷积核擅长识别橙色,那么这个通道可能就表现出许多橙色,如下图所示:
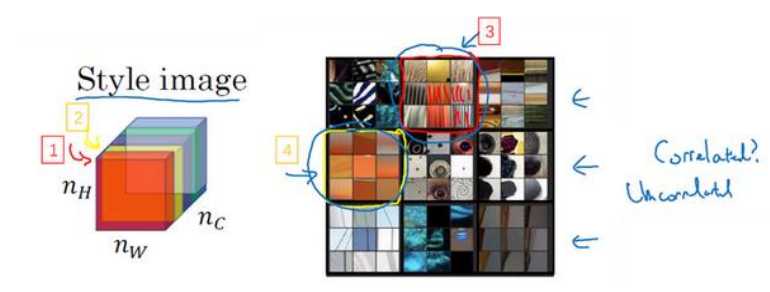
(2)那么什么是通道间的相关性呢?如果一个通道出现垂直线的地方,更容易出现橙色,即二者同时出现或者不出现的概率大那么二者就相关了。
(3)说两张图的风格相似,可以看成两张图各自不同通道之间的相关性是相同的,那么这两张图就风格相同(或者类似)。
(4)以下是一种不是很标准(之所以说不标准是因为没有减去各自的均值再相乘)的求相关系数的方法,即两个通道间对应元素相乘,然后求和,最后结果越大说明越相关:
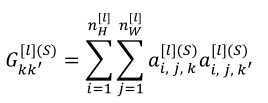
(5)最后只要把风格图和生成图在隐含层l层的各自的相关系数做差再求范数即可(前面的归一化可要可不要,因为还有超参数α、β):
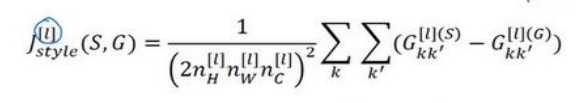
(6)最后就形成了总的代价函数:
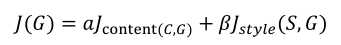
(1)一维数据,如心电图,这时候的卷积核如下所示,一个14维与一个5维卷积核卷积形成一个10维输出:
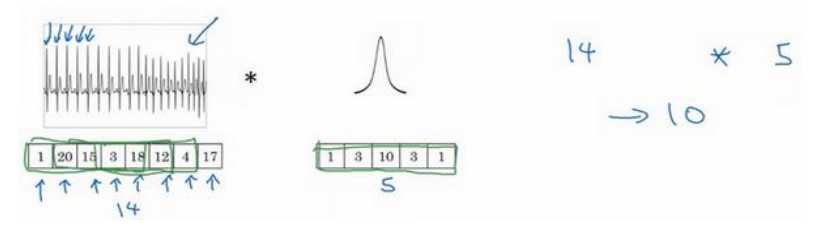
(2)三维数据,如CT图,一个3D对象,如14*14*14(这里没有出现通道数,宽度和深度是后面两个),这时候5卷积核比如说5*5*5*1(假设输入照片是1通道的),这时候输出10*10*10*5。需要时刻记住的是卷积核的通道数一定要和输入的通道数相同。

吴恩达《深度学习》第四门课(4)特殊应用:人脸识别和神经风格迁移
标签:相关系数 特征 相同 相关 osi 归一化 let diff vgg
原文地址:https://www.cnblogs.com/ys99/p/9332519.html