标签:异常 影响 部分 cal dia 避免 img database stand
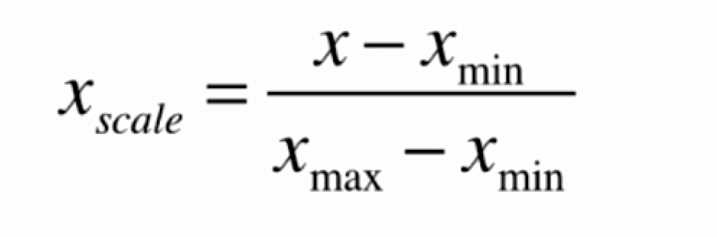
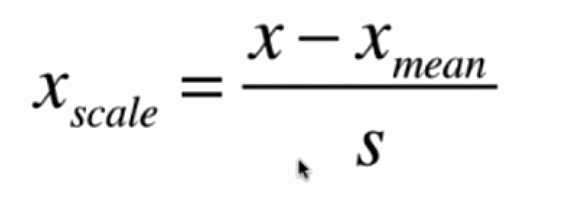
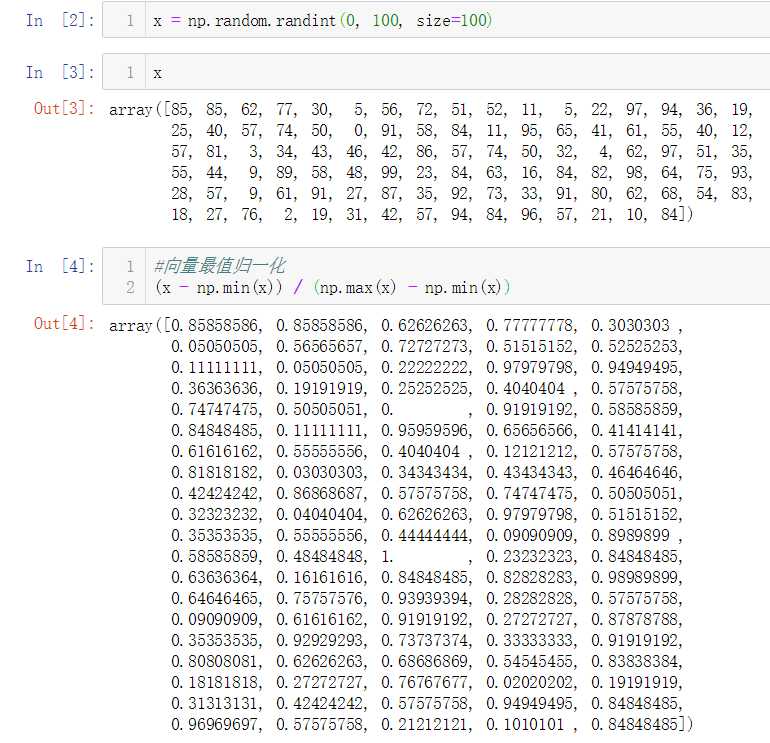
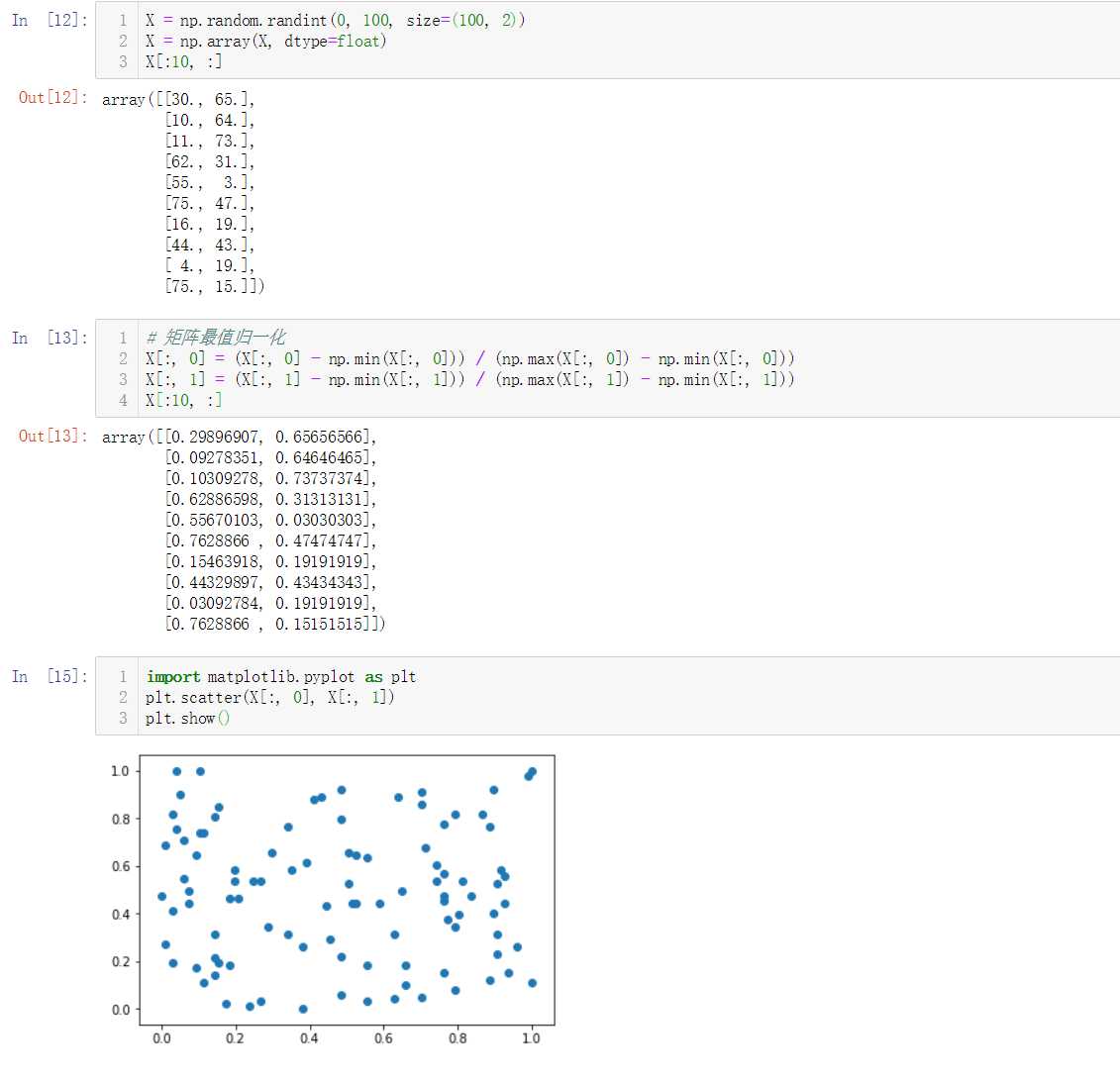
矩阵的最值归一化
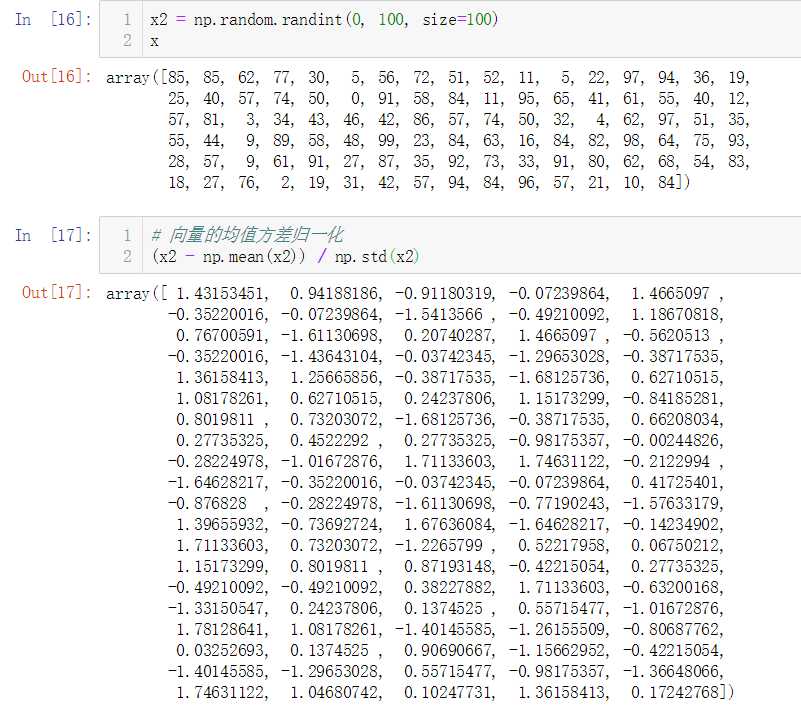
矩阵的均值方差归一化
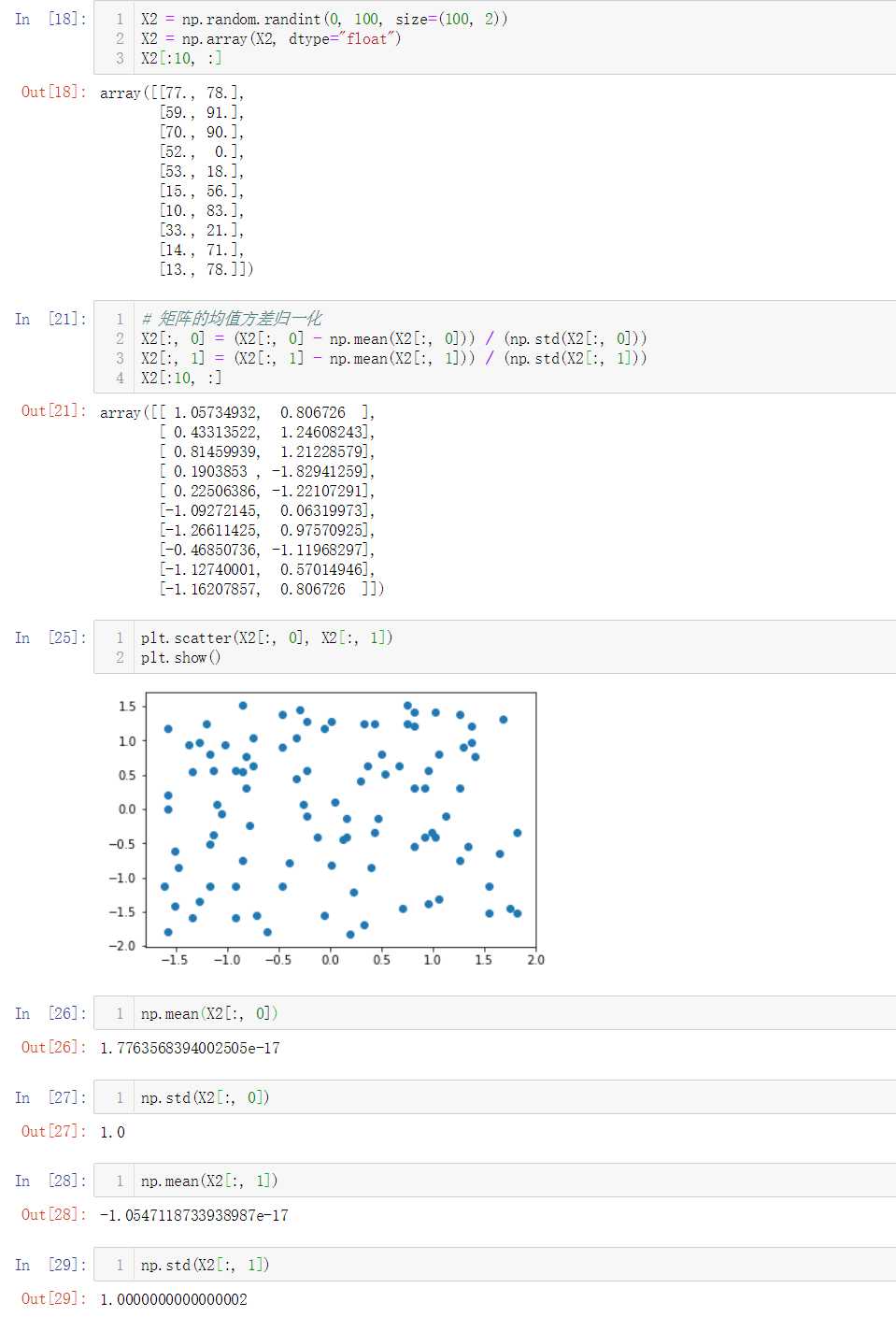
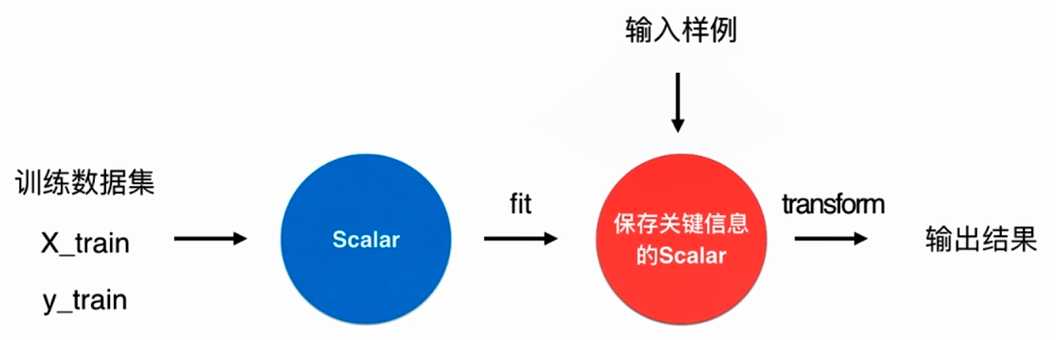
No.6. 使用鸢尾花数据集进行数据归一化
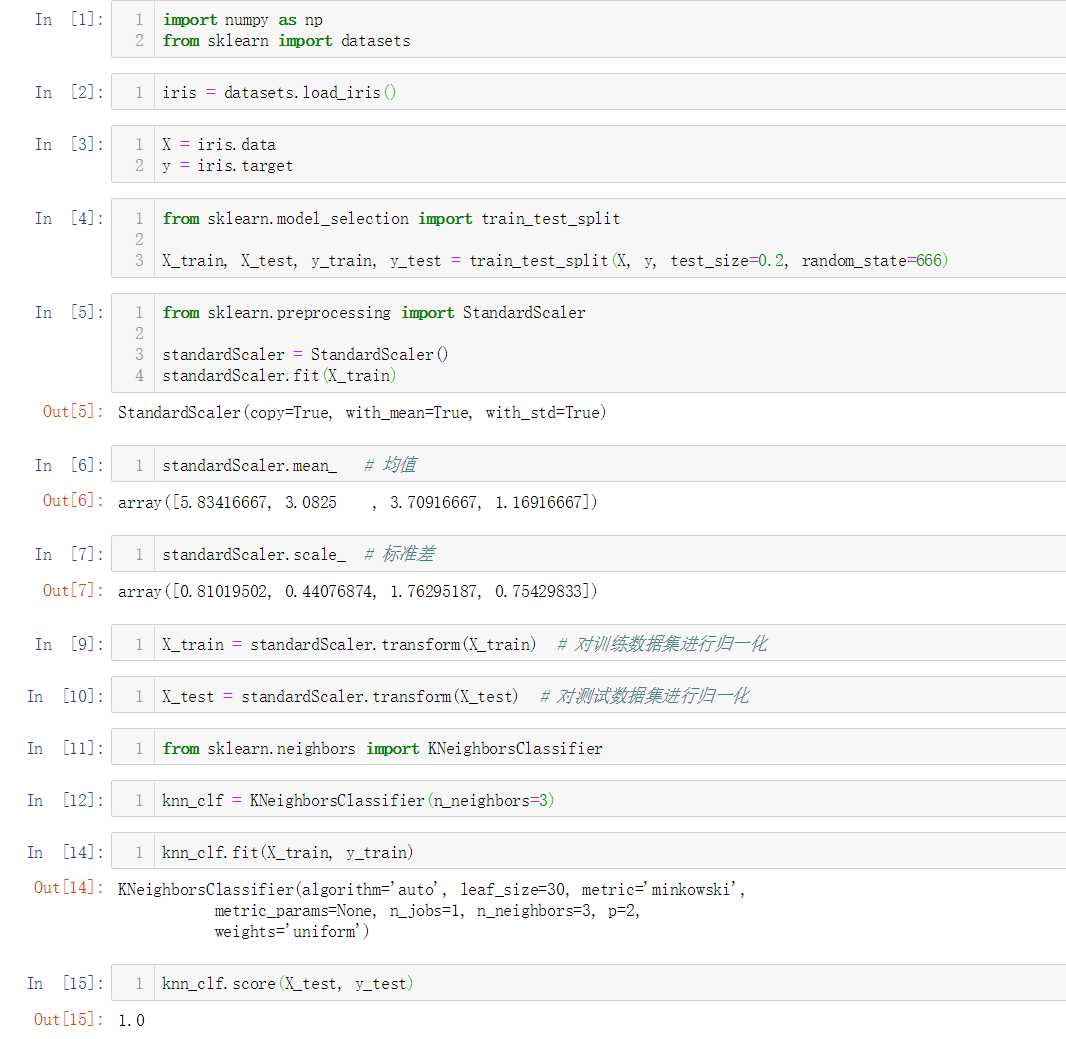
No.7. 简单实现一个自己的StandardScaler类

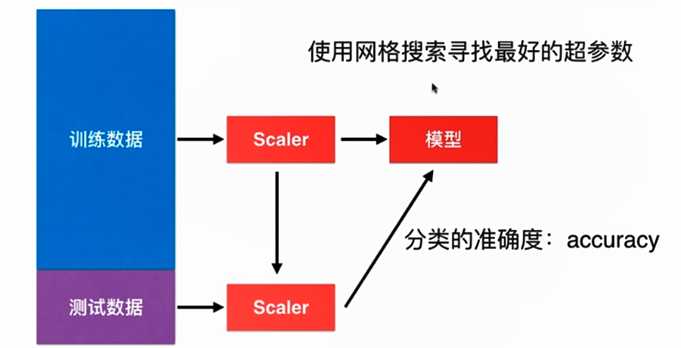
第四十九篇 入门机器学习——数据归一化(Feature Scaling)
标签:异常 影响 部分 cal dia 避免 img database stand
原文地址:https://www.cnblogs.com/xuezou/p/9332763.html