标签:lis mina 结构 tab user tla bio specific 引用
对于初学者,使用ANNOVAr的最简单方法是使用table_annovar.pl程序,该程序采用输入突变文件(例如,VCF文件)并生成带有多个制表符分隔的输出文件,每个列表示一组注释。另外,如果输入是VCF文件,则程序还生成新的VCF输出文件,其中INFO字段填充有注释信息。
假设我们已经下载了ANNOVAR包并使用tar zxvf annovar.latest.tar.gz解压缩包。您将看到bin/目录包含有多个.pl后缀的Perl程序。(注意,如果您已将ANNOVAR路径添加到系统可执行文件路径中,则键入annotate_variation.pl即可,而不是键入perl annotate_variation.pl。首先,我们需要使用annotate_variation.pl下载相应的数据库文件,然后我们将运行table_annovar.pl程序来注释example/ex1.avinput文件中的突变。
[yhwang@biocluster ~/]$ annotate_variation.pl -buildver hg19 -downdb -webfrom annovar refGene humandb/
[yhwang@biocluster ~/]$ annotate_variation.pl -buildver hg19 -downdb cytoBand humandb/
[yhwang@biocluster ~/]$ annotate_variation.pl -buildver hg19 -downdb -webfrom annovar exac03 humandb/
[yhwang@biocluster ~/]$ annotate_variation.pl -buildver hg19 -downdb -webfrom annovar avsnp147 humandb/
[yhwang@biocluster ~/]$ annotate_variation.pl -buildver hg19 -downdb -webfrom annovar dbnsfp30a humandb/
[yhwang@biocluster ~/]$ table_annovar.pl example/ex1.avinput humandb/ -buildver hg19 -out myanno -remove -protocol refGene,cytoBand,exac03,avsnp147,dbnsfp30a -operation gx,r,f,f,f -nastring . -csvout -polish -xref example/gene_fullxref.txt
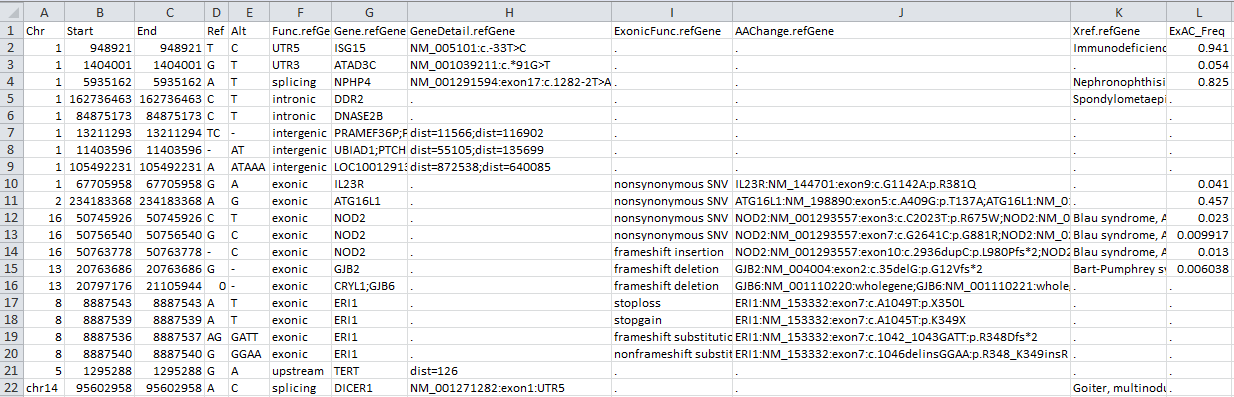
输入文件包含多个列,前几列是您的输入列,以下每个列对应于用户在命令行中指定的“协议”之一。Func.refGene, Gene.refGene, GeneDetail.refGene, ExonicFunc.refGene, AAChange.refGene列包含关于突变如何影响基因结构的各种注释。Xref.refGene列包含基因的交叉引用;在这种情况下,已知的遗传疾病是否是由该基因的缺陷引起的(该信息在命令行的示例/gene_fullxref.txt文件中被填充)。对于接下来的几列,ExAC *列表示所有样本中的等位基因频率以及Exome Aggregation Consortium数据集中的子群体,而avsnp147表示dbSNP 147版本中的SNP标识符。其它列包含预测非同义突变使用几种广泛工具的得分,PolyPhen2 HDIV得分、PolyPhen2 HVAR得分,LRT得分,MutationTaster得分,MutationAssessor得分,FATHMM得分,GERP ++得分,CADD得分,DANN得分,PhyloP得分和SiPhy得分等等。
我们可以更加详细地检查命令行。-operation参数指定ANNOVAR每个协议使用哪些操作:g表示基于基因,gx表示基于基因的交叉引用注释(来自-xref参数),r表示基于区域,f表示基于过滤器。如果您不提供外部参考文件,则操作只能是g。您将在其他网页中找到有关基因/区域/基于过滤器的注释的详细信息。有时,用户需要制表符分隔文件而不是逗号分隔文件,删除上述命令的-csvout参数就可以完成。
在上面的命令中,我们使用-xreffile参数为基因组提供注释。如果文件包含标题行,则可以为基因提供多个注释(而不仅仅是一个列)。为了说名这一点,我们可以检查example/gene_fullxref.txt文件的前两行(包括标题行)。
[yhwang@biocluster ~/project/annotate_variation]$ head -n 2 example/gene_fullxref.txt
#Gene_name pLi pRec pNull Gene_full_name Function_description Disease_description Tissue_specificity(Uniprot) Expression(egenetics) Expression(GNF/Atlas) P(HI) P(rec) RVIS RVIS_percentile GDI GDI-Phred
A1BG 9.0649236354772e-05 0.786086131023045 0.2138232197406 alpha-1-B glycoprotein . . TISSUE SPECIFICITY: Plasma.; unclassifiable (Anatomical System);amygdala;prostate;lung;islets of Langerhans;liver;spleen;germinal center;brain;thymus; fetal liver;liver;fetal lung;trigeminal ganglion; 0.07384 0.31615 -0.466531444 23.51380042 79.3774 1.88274
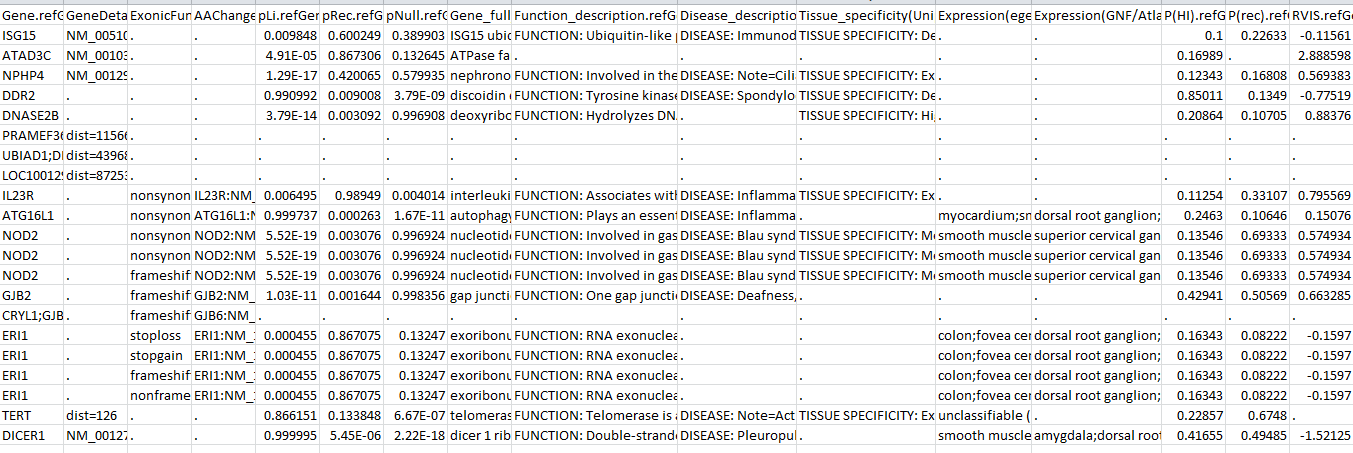
标题行以#开头。然后,交叉引用文件包含15种基因注释。您可以运行上面的相同命令,结果文件可以从此处下载。下面显示了部分文件,为用户提供了一个示例:
table_annovar.pl可以直接支持VCF文件的输入和输出(注释将被写入输出VCF文件的INFO字段)。我们试试这个:
[yhwang@biocluster ~/]$ table_annovar.pl example/ex2.vcf humandb/ -buildver hg19 -out myanno -remove -protocol refGene,cytoBand,exac03,avsnp147,dbnsfp30a -operation g,r,f,f,f -nastring . -vcfinput
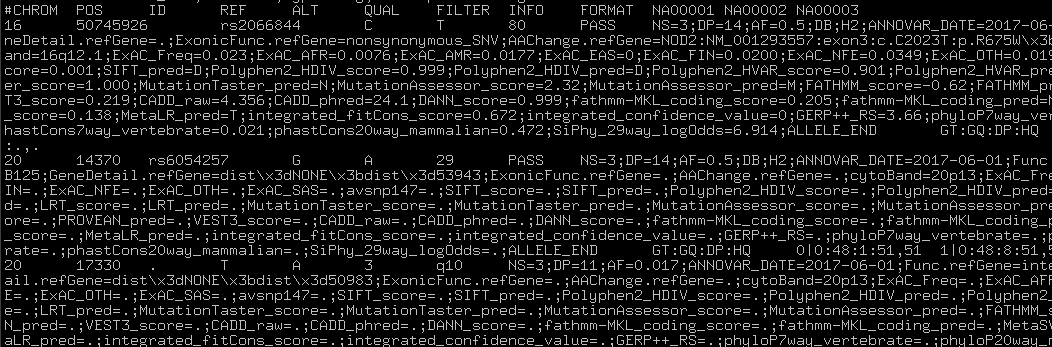
您可以在此处下载输出文件:ex2.hg19_multianno.vcf。此外,制表符分隔的输出文件也可以(例如, ex2.hg19_multianno.txt),其中包含不同格式的类似信息。您可以在文本编辑器中打开新的VCF文件,并检查文件中已更改的内容:VCF文件中的INFO字段现在包含您需要的注释,以字符串ANNOVAR_DATE开始,ALLELE_END结束。如果多个等位基因位于同一个基因座中,您将在INFO字段中看到多个此类符号。屏幕截图如下所示:
annotate_variation.pl程序是ANNOVAR中的核心程序。 我们可以转到ANNOVAR目录,然后逐个运行以下三个命令。
annotate_variation.pl -geneanno -dbtyep refGene -buildver hg19 example/ex1.avinput humandb/
annotate_variation.pl -regionanno -dbtype cytoBand -buildver hg19 example/ex1.avinput humandb/
annotate_variation.pl -filter -dbtype exac03 -buildver hg19 example/ex1.avinput humandb/
这三个命令分别对应于基于基因、基于区域和基于过滤器的注释。
第一个命令注释ex1.avinput文件中的12种突变,并将它们分类为intergenic、intronic、non-synonymous SNP、feameshift delete、large-scale duplication等。
检查ex1.avinput文件以查看简单文本格式,每一行对应一个突变。花费几秒钟完成注释,生成两个输出文件为ex1.avinput.variant_function和ex1.avinput.exonic_variant_function。检查example/目录中的两个输出文件以查看它们包含的内容:在variant_function文件中,第一列和第二列注释突变对基因结构和受影响的基因,但其他列则从输入文件中重现。在exonic_variant_function文件中,第一,第二和第三列注释输入文件中的突变行号,突变对编码序列的影响和基因/转录本受到影响,但其他列从输入文件中复制。
接下来,该程序在ex1.avinput文件中注释突变,并为这些突变识别细胞遗传学带。注释过程应该小几秒钟。检查输出文件ex1.avinput.hg19_cytoBand以查看它包含的内容。第一列显示cytoBand,第二列显示注释结果,其他列从输入文件中再现。
接下来,程序识别ex1.avinput中exac03数据库中未观察到的突变子集(保存在ex1.avinput.hg19_exac03_filtered中)以及用等位基因频率观察到的突变子集(保存在ex1.avinput.hg19_exac03_dropped文件中)。
上述命令代表了一组关于ANNOVAR如何帮助研究人员宣传高通量测序数据产生的遗传变异的基本实例。
标签:lis mina 结构 tab user tla bio specific 引用
原文地址:https://www.cnblogs.com/yahengwang/p/9332610.html