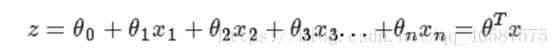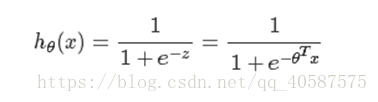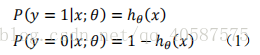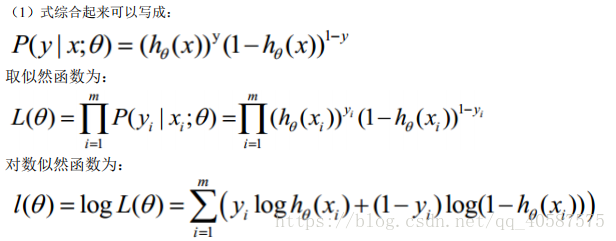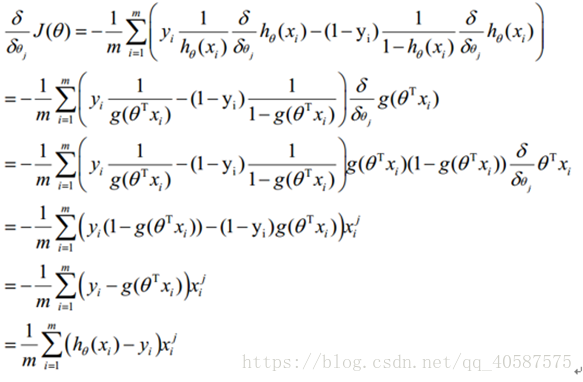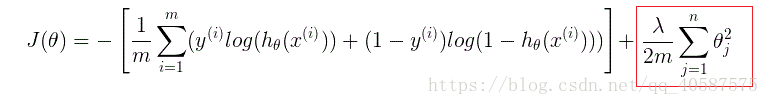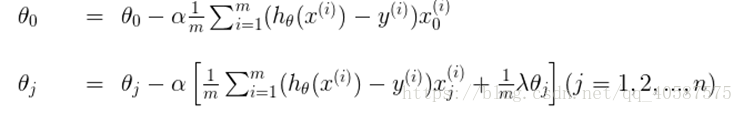标签:list any https tran intercept splay 学习 chm table
逻辑回归的基本过程:a建立回归或者分类模型--->b 建立代价函数 ---> c 优化方法迭代求出最优的模型参数 --->d 验证求解模型的好坏。
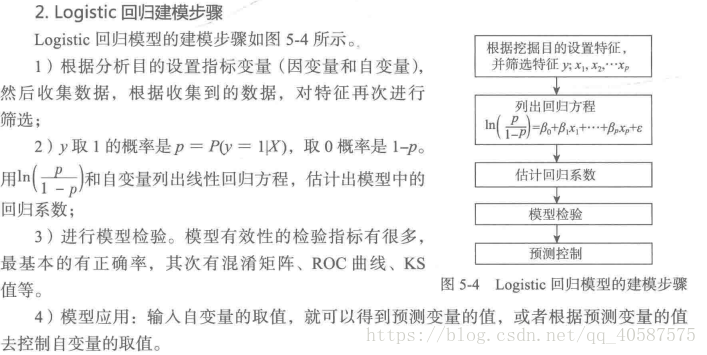
1.逻辑回归模型:
逻辑回归(Logistic Regression):既可以看做是回归算法,也可以看做是分类算法。通常作为分类算法,一般用于解决二分类问题。
线性回归模型如下:![]() ?
?
逻辑回归思想是基于线性回归(Logistic Regression是广义的线性回归模型),公式如下:
![]() ?
?
其中,![]() ?
?
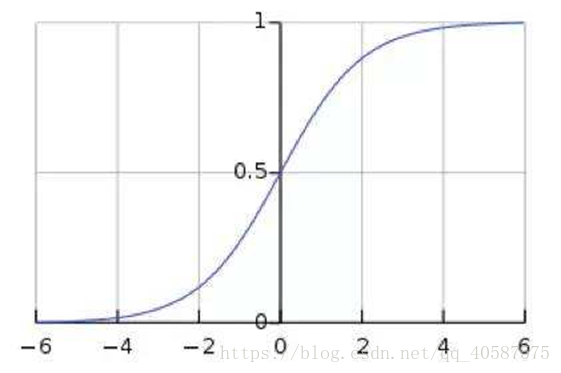
称为Sigmoid函数
![]() ?
?
由图可知:Sigmoid函数值域是在(0 , 1)之间,中间值为0.5 ,所以逻辑回归函数可以表示数据属于某一类别的概率:
h_θ(x) ≥ 0.5,预测 y=1 类
h_θ(x) < 0.5,预测 y=0类
代价函数是基于最大似然函数推导出来的。
![]() ?
?
将上式(1)可写成下面这个式子:
![]() ?
?
将式子乘一个(-1/m),使用梯度下降法求最优解 θ 参数
当x和y为多维时:
![]() ?
?
2.1 梯度下降法求解最小值
求解函数的最优解(极大值和极小值),在数学中我们一般会对函数求导,然后让导数等于0,获得方程,然后通过解方程直接得到结果。但是在机器学习中,我们的函数常常是多维高阶的,得到导数为0的方程后很难直接求解(有些时候甚至不能求解),所以就需要通过其他方法来获得这个结果,而梯度下降就是其中一种。
![]() ?
?
对θ 参数进行更新:
α 为学习率
![]() ?
?
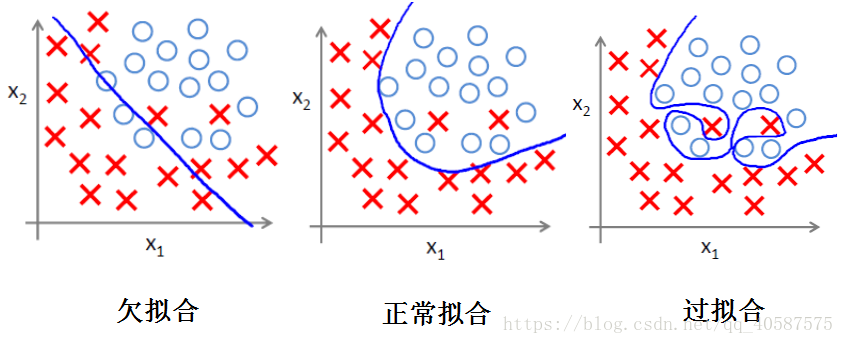
(1)过拟合问题
过拟合即是过分拟合了训练数据,使得模型的复杂度提高,但是泛化能力较差。
![]() ?
?
(2)正则化方法 :
正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项或惩罚项。
正则项可以取不同的形式,在回归问题中取平方损失,就是参数的L2范数,也可以取L1范数。取平方损失时,模型的损失函数变为:
![]() ?
?
lambda是正则项系数(λ):
? 如果它的值很大,说明对模型的复杂度惩罚大,可能导致欠拟合; (使得J(θ) 最小化,当λ 值很大时,θ→0)
如:曲线为 z=θ_0+θ_1 x_1+θ_2 x_1^2+λθ_3 x_2^3 ----> θ_3→0
? 如果它的值很小,说明比较注重对训练数据的拟合,在训练数据上的偏差会小,但是可能会导致过拟合。(保留更多的θ)
正则化后的梯度下降算法θ的更新变为:
![]() ?
?
优点:(1)速度快, 适合二分类问题
(2)简单易于理解, 直接看到各个特征的权重
(3)能容易吸收新的数据
缺点:对数据和场景的使用能力有限, 不如决策树算法适应性强
![]() ?
?
使用稳定性选择方法中的随机逻辑回归进行特征筛选, 然后对筛选后的特征建立逻辑回归模型
#coding=gbk
#使用稳定性选择方法中的随机逻辑回归进行特征筛选, 然后对筛选后的特征建立逻辑回归模型
import pandas as pd
import numpy as np
filename = r‘D:\datasets\bankloan.xls‘
data = pd.read_excel(filename)
print(data.head())
# 年龄 教育 工龄 地址 收入 负债率 信用卡负债 其他负债 违约
# 0 41 3 17 12 176 9.3 11.359392 5.008608 1
# 1 27 1 10 6 31 17.3 1.362202 4.000798 0
# 2 40 1 15 14 55 5.5 0.856075 2.168925 0
# 3 41 1 15 14 120 2.9 2.658720 0.821280 0
# 4 24 2 2 0 28 17.3 1.787436 3.056564 1
x = data.iloc[:,:8].as_matrix()
y = data.iloc[:,8].as_matrix() #转换成矩阵形式,使其没有索引项 是否违约1,0
from sklearn.linear_model import RandomizedLogisticRegression as RLR
rlr = RLR()
rlr.fit(x, y)
rlr.get_support() #获取特征筛选结果,
print(rlr.get_support()) #[False False True True False True True False]
print(rlr.scores_) #[0.085 0.045 0.995 0.395 0. 0.995 0.595 0.04 ] 获取特征结果的分数
print(‘通过随机逻辑回归模型筛选特征结束‘)
# print(u‘有效特征为:%s‘ % ‘,‘.join(data.columns[rlr.get_support()]))
# x = data[data.columns[rlr.get_support()]].as_matrix()
print(u‘有效特征为:%s‘ % ‘,‘.join(np.array(data.iloc[:,:8].columns)[rlr.get_support()]))
x = data[np.array(data.iloc[:,:8].columns)[rlr.get_support()]].as_matrix() #筛选好特征
from sklearn.linear_model import LogisticRegression as LR
lr = LR()
lr.fit(x,y)
print(‘通过逻辑回归模型训练结束‘)
print(‘模型的平均正确率为: %s‘ % lr.score(x,y))
# 通过随机逻辑回归模型筛选特征结束
# 有效特征为:工龄,地址,负债率,信用卡负债
# 通过逻辑回归模型训练结束
# 模型的平均正确率为: 0.8142857142857143
Python中逻辑回归的实现:
#coding=gbk
‘‘‘
Created on 2018年7月2日
@author: Administrator
‘‘‘
from math import exp
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets.samples_generator import make_blobs
#定义一个sigmoid函数
def sigmoid(num):
if type(num)==int or type(num)== float:
return 1.0/(1 + exp(-1 * num))
else:
raise ValueError(‘只有int and float 类型才能进行计算‘)
#定义一个逻辑回归的类
class logistic():
def __init__(self,x,y): #判断输入的数据是否符合,并将其转换成ndarray
if type(x) == type(y) == list:
self.x = np.array(x)
self.y = np.array(y)
elif type(x) == type(y) ==np.ndarray:
self.x = x
self.y = y
else:
raise ValueError(‘输入数据错误‘)
def sigmoid(self,x): #输出向量整体进行sigmoid 计算后的向量结果
s = np.frompyfunc(lambda x: sigmoid(x), 1,1) #得到矩阵
return s(x)
def train_and_punish(self,alpha, errors , punish = 0.0001):
‘‘‘
alpha 为学习率
errors 为误差小于多少时停止迭代的次数
punish 为惩罚系数
times 为最大迭代次数
‘‘‘
self.punish = punish
dimension = self.x.shape[1] #得到列的数量
self.theta = np.random.random(dimension) #对theta 去随机数
computer_error = 100000000
times = 0
while computer_error > errors:
res = np.dot(self.x, self.theta)
delta = self.sigmoid(res) - self.y #这里使用了向量化,计算sigmoid函数得出的结果与0,1的差
self.theta = self.theta - alpha * np.dot(self.x.T, delta) - punish * self.theta #更新学习率
computer_error = np.sum(delta)
times+=1
def predict(self, x):
x = np.array(x)
if self.sigmoid(np.dot(x, self.theta)) > 0.5:
return 1
else:
return 0
def test():
#scikit中的make_blobs方法常被用来生成聚类算法的测试数据,
#直观地说,make_blobs会根据用户指定的特征数量、中心点数量、范围等来生成几类数据,这些数据可用于测试聚类算法的效果。
# n_samples是待生成的样本的总数。
# n_features是每个样本的特征数。
# centers表示类别数。
# cluster_std表示每个类别的方差,例如我们希望生成2类数据,其中一类比另一类具有更大的方差,可以将cluster_std设置为[1.0,3.0]。
#center_box 表示x,y轴的范围
x, y = make_blobs(n_samples=200, centers =2, n_features=2, random_state=0, center_box=(10,20))
x1=[]
y1=[]
x2=[]
y2=[]
#生成两类数据
for i in range(len(y)):
if y[i] ==0:
x1.append(x[i][0])
y1.append(x[i][1])
elif y[i] == 1:
x2.append(x[i][0])
y2.append(x[i][1])
p = logistic(x,y)
p.train_and_punish(alpha=0.00001, errors=0.005, punish=0.01)
x_test = np.arange(10,20,0.01)
y_test = (-1* p.theta[0] / p.theta[1]) * x_test
plt.plot(x_test, y_test, c=‘g‘, label = ‘logistic_line‘)
plt.scatter(x1, y1, c=‘r‘, label = ‘positive‘)
plt.scatter(x2, y2, c=‘b‘,label =‘negtive‘)
plt.legend(loc =2)
plt.title(‘punish value = ‘ + p.punish.__str__())
plt.show()
if __name__ == ‘__main__‘:
test() ![]() ?
?
LogisticRegression类的各项参数的含义:
class sklearn.linear_model.LogisticRegression(penalty=‘l2‘,
dual=False, tol=0.0001, C=1.0, fit_intercept=True,
intercept_scaling=1, class_weight=None,
random_state=None, solver=‘liblinear‘, max_iter=100,
multi_class=‘ovr‘, verbose=0, warm_start=False, n_jobs=1)
penalty=‘l2‘ : 字符串‘l1’或‘l2’,默认‘l2’。
dual=False : 对偶或者原始方法。Dual只适用于正则化相为l2的‘liblinear’的情况,通常样本数大于特征数的情况下,默认为False。C=1.0 : C为正则化系数λ的倒数,必须为正数,默认为1。和SVM中的C一样,值越小,代表正则化越强。fit_intercept=True : 是否存在截距,默认存在。intercept_scaling=1 : 仅在正则化项为‘liblinear’,且fit_intercept设置为True时有用。solver=‘liblinear‘ : solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择。
| 正则化 | 算法 | 适用场景 |
|---|---|---|
| L1 | liblinear | liblinear适用于小数据集;如果选择L2正则化发现还是过拟合,即预测效果差的时候,就可以考虑L1正则化;如果模型的特征非常多,希望一些不重要的特征系数归零,从而让模型系数稀疏化的话,也可以使用L1正则化。 |
| L2 | liblinear | libniear只支持多元逻辑回归的OvR,不支持MvM,但MVM相对精确。 |
| L2 | lbfgs/newton-cg/sag | 较大数据集,支持one-vs-rest(OvR)和many-vs-many(MvM)两种多元逻辑回归。 |
| L2 | sag | 如果样本量非常大,比如大于10万,sag是第一选择;但不能用于L1正则化。 |
multi_class=‘ovr‘ : 分类方式。官网有个对比两种分类方式的例子:链接地址。
class_weight=None : 类型权重参数。用于标示分类模型中各种类型的权重。默认不输入,即所有的分类的权重一样。
{class_label: weight}。例如0,1分类的er‘yuan二元模型,设置class_weight={0:0.9, 1:0.1},这样类型0的权重为90%,而类型1的权重为10%。random_state=None : 随机数种子,默认为无。仅在正则化优化算法为sag,liblinear时有用。
max_iter=100 : 算法收敛的最大迭代次数。
tol=0.0001 : 迭代终止判据的误差范围。
verbose=0 : 日志冗长度int:冗长度;0:不输出训练过程;1:偶尔输出; >1:对每个子模型都输出
warm_start=False : 是否热启动,如果是,则下一次训练是以追加树的形式进行(重新使用上一次的调用作为初始化)。布尔型,默认False。
n_jobs=1 : 并行数,int:个数;-1:跟CPU核数一致;1:默认值。
LogisticRegression类的常用方法
fit(X, y, sample_weight=None)
fit_transform(X, y=None, **fit_params)
X_new:numpy矩阵。predict(X)
predict_proba(X)
score(X, y, sample_weight=None)
参考:机器学习之逻辑回归
标签:list any https tran intercept splay 学习 chm table
原文地址:https://www.cnblogs.com/junge-mike/p/9334943.html