标签:返回 方法体 执行方法 cache 检索 直接 com 解锁 inf
目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题。分布式的CAP理论:任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(partition Tolerance),最多只能同时满足两项。
所以,很多系统在设计之初就要对这三者做出取舍。在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
在很多场景中,为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。有的时候,需要保证一个方法在同一时间内只能被同一个线程执行。在单机环境中,Java中其实提供了很多并发处理的相关的API,但是这些API在分布式场景中就无能为力。单纯的Java API并不能提供分布式锁的实现。目前比较常见的有以下几种方案:
分布式需要具有如下的特性:
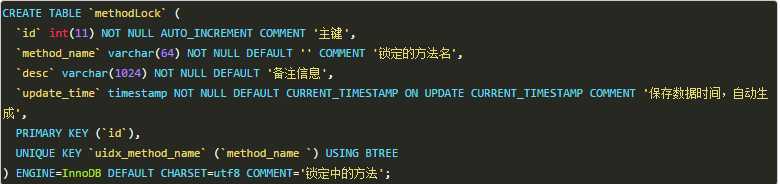
要实现分布式锁,最简单的方式可能就是直接创建一张锁表,然后通过操作该表的数据来实现。
当锁住某个方法或资源时,就在该表中增加一条记录,想要释放锁的时候就删除这条记录。
创建这样一张数据库表:
想要锁住某个方法时,执行以下SQL:

因为method_name是唯一索引,如果有多个请求同时提交到时数据库的话,数据库会保证只有一个操作可以成功,就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。
当方法执行完毕周后,想要释放锁的话,需要执行以下SQL:

上面这种简单的实现有以下几个问题:
当然可以有其他方式解决上面的问题:
除了可以通过增删操作数据库表中的记录之外,其实还可以借助数据库中自带的锁来实现分布式锁。
可以通过数据库的排他锁来实现分布式锁,基于MySQL的InnoDB引擎,可以使用一下方法来实现加锁操作:
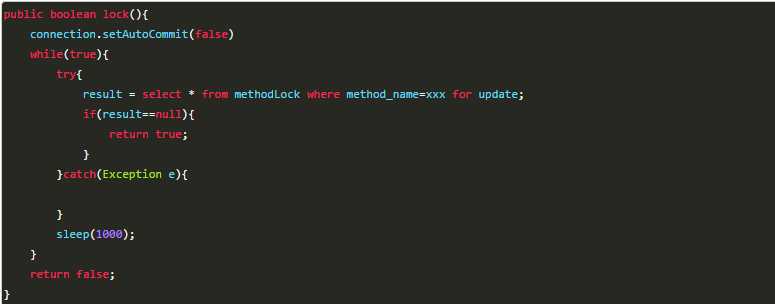
在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁,当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。
(备注:InnoDB引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。我们希望使用行级锁,就要给method_name添加索引,值得注意的是,这个索引一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题,重载方法的话,建议把参数类型也加上)
可以认为获得排他锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,在通过以下方法解锁。

通过connection.commit()操作来释放锁。
这种方法可以有效的解决上面提到定位无法释放锁和阻塞锁的问题。
但是还是无法直接解决数据库单点和可重入问题。
相比于基于数据库实现分布式锁的方案来说,基于缓存来实现在性能方面会表现的更好一点,而且很多缓存是可以集群部署的,可以解决单点问题。
目前有很多成熟的缓存产品,包括Redis,memcached,tair。
以tair为例来分析使用缓存实现分布式锁的方案。
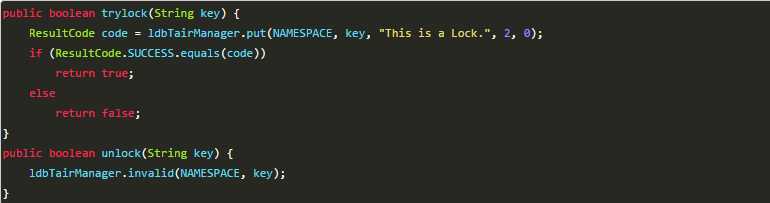
以上实现同样存在几个问题:
标签:返回 方法体 执行方法 cache 检索 直接 com 解锁 inf
原文地址:https://www.cnblogs.com/lujiango/p/9335017.html