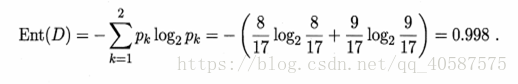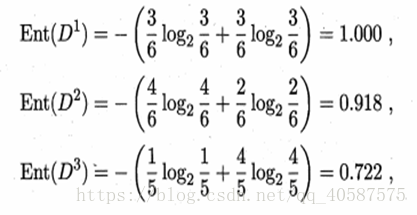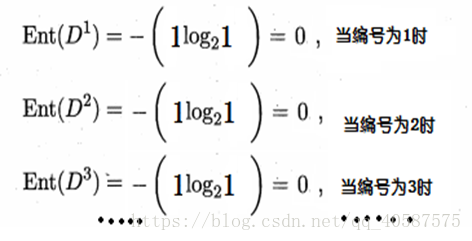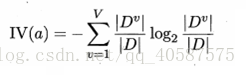标签:随机选择 lsp https add 直接 就是 state aaa nts
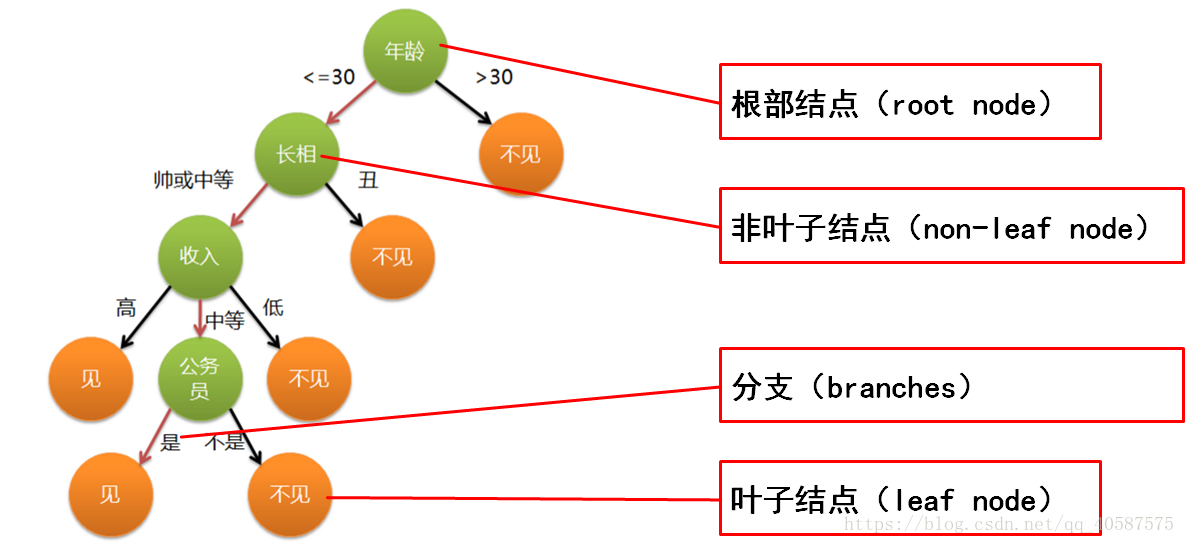
决策树是以树状结构表示数据分类的结果
![]() ?
?
非叶子结点代表测试的条件。
分支代表测试的结果
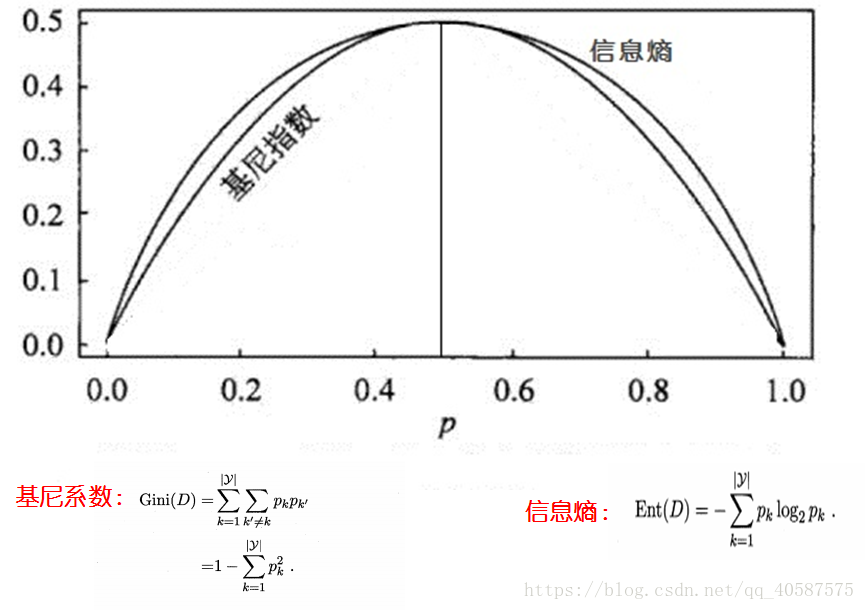
′1.信息熵(informationentropy):是度量样本集合纯度最常用的一种指标。
![]() ?
?
2.基尼系数(gini):是度量样本集合不确定性指标。(基尼指数与熵可近似看做是统一概念,都是越大,确定性越差)
![]() ?
?
基尼指数和信息熵的图像:(当熵和基尼指数为0.5时,即确定某件事的概率为50%,是最不能肯定的事件。如:小明后天再路上捡钱的概率为50%,很不确定。如果概率为30%,代表很可能捡不到钱;如果概率为60%,则代表更可能捡到钱。)
![]() ?
?
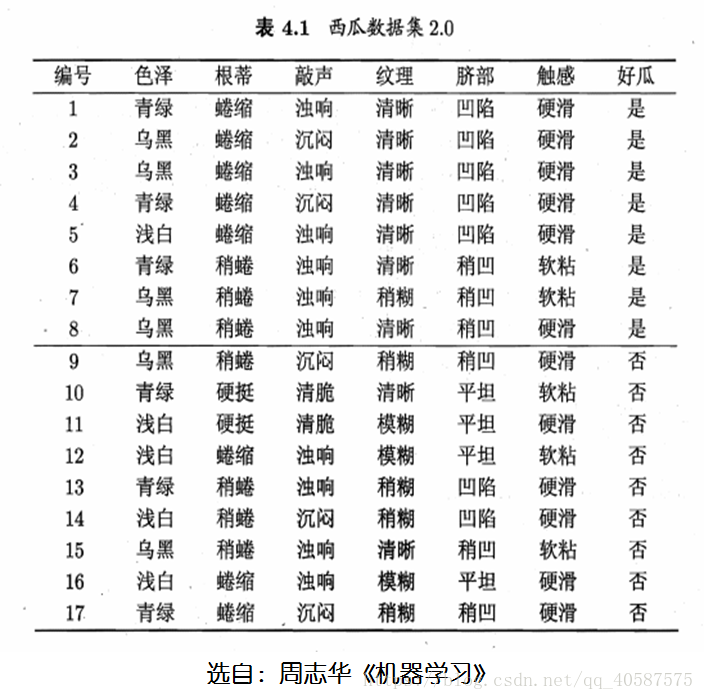
一个小栗子:
![]() ?
?
1.系统信息熵:(是,否为好瓜的两个属性)
![]() ?
?
2.每个特征的信息熵:(以色泽为例)(先计算出3 个属性的信息熵,依次为:青绿,乌黑,浅白)
![]() ?
?
然后,结合3 个属性,计算出特征为色泽的信息熵。
![]() ?
?
3.信息增益:
![]() ?
?
信息增益大,代表着熵小,所以确定性较高。
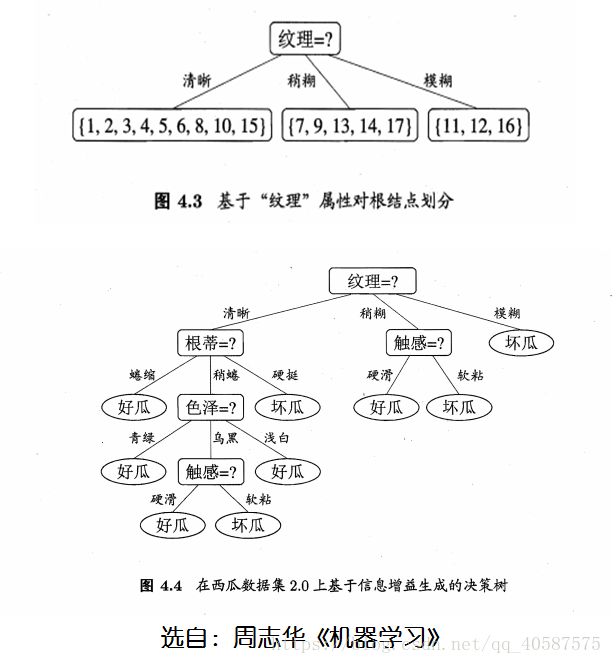
得出决策结果
![]() ?
?
但是,当我们使用ID编号作为一个特征量的时候
′得到信息熵:
![]() ?
?
′信息增益为:
![]() ?
?
所以需要使用编号作为根节点吗?显然不可能。
(所以说:ID3决策树倾向于选择属性较多的特征,当这个特征不一定是最优的属性特征。同时,ID3决策树只能处理离散的属性,对于连续的属性,需要在 分类前对其进行离散化。)
因此,引入增益率:
![]() ?
?
求得IV(编号):
![]() ?
?
′=1/(17)*17*log2(1/(17))=4.08
′如果一个特征的取值越多,其IV(a)分母也越大。
|
决策树常见算法 |
ID3算法 |
C4.5算法 |
CART算法 |
|
结点选择准则 |
信息增益 |
信息增益率 |
基尼系数 |
![]() ?
?
#coding=gbk
#使用ID3决策树预测销量的高低,基于信息熵
import pandas as pd
filename = r‘D:\datasets\sales_data.xls‘
data = pd.read_excel(filename, index_col= u‘序号‘) #将序号作为索引
data[data == u‘好‘] = 1 #使用1 表示‘好’,是,高,3个属性
data[data == u‘是‘] = 1
data[data == u‘高‘] = 1
data[data != 1] = -1
print(data.head())
# 序号 天气 是否周末 是否有促销 销量
# 1 -1 1 1 1
# 2 -1 1 1 1
# 3 -1 1 1 1
# 4 -1 -1 1 1
# 5 -1 1 1 1
x = data.iloc[:,:3].as_matrix().astype(int) #将前3列作为输入
y = data.iloc[:,3].as_matrix().astype(int)#最后列作为标签
#建立决策树
from sklearn.tree import DecisionTreeClassifier as DTC
dtc = DTC(criterion=‘entropy‘) #建立决策树,基于信息熵
dtc.fit(x,y)
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
x = pd.DataFrame(x)
with open(r‘D:\datasets\tree.dot‘,‘w‘) as f:
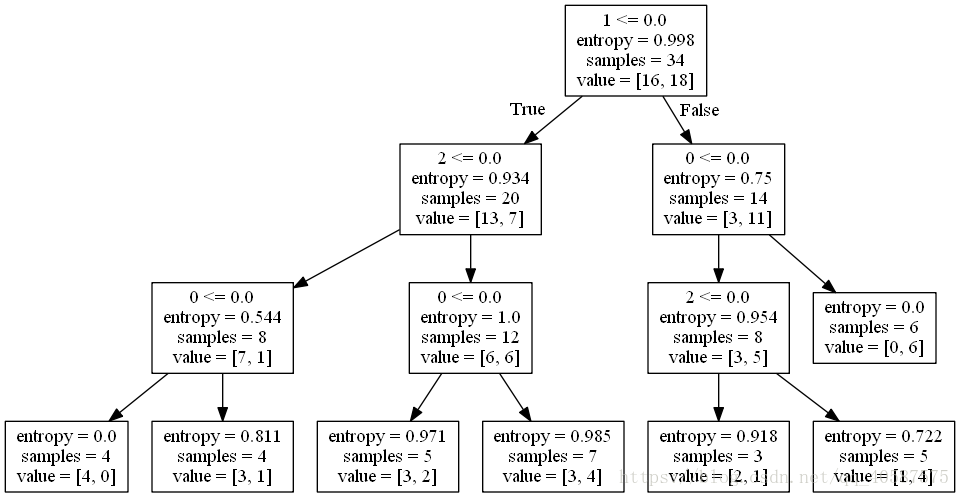
f = export_graphviz(dtc, feature_names=x.columns, out_file=f)安装Graphviz,显示决策树图像,可参考一篇博客
进入windows命令行界面,cd 切换到tree.dot所在的路径,执行
dot -Tpng tree.dot -o tree.png可获取图像:
![]() ?
?
决策树的参数:
sklearn.tree.DecisionTreeClassifier
(criterion=‘gini‘, splitter=‘best‘, max_depth=None, min_samples_split=2,
min_samples_leaf=1,min_weight_fraction_leaf=0.0, max_features=None,
random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, class_weight=None, presort=False)criterion:特征选择的标准,有信息增益和基尼系数两种,使用信息增益的是ID3和C4.5算法(使用信息增益比),使用基尼系数的CART算法,默认是gini系数。
splitter:特征切分点选择标准,决策树是递归地选择最优切分点,spliter是用来指明在哪个集合上来递归,有“best”和“random”两种参数可以选择,best表示在所有特征上递归,适用于数据集较小的时候,random表示随机选择一部分特征进行递归,适用于数据集较大的时候。
max_depth:决策树最大深度,决策树模型先对所有数据集进行切分,再在子数据集上继续循环这个切分过程,max_depth可以理解成用来限制这个循环次数。
min_samples_split:子数据集再切分需要的最小样本量,默认是2,如果子数据样本量小于2时,则不再进行下一步切分。如果数据量较小,使用默认值就可,如果数据量较大,为降低计算量,应该把这个值增大,即限制子数据集的切分次数。
min_samples_leaf:叶节点(子数据集)最小样本数,如果子数据集中的样本数小于这个值,那么该叶节点和其兄弟节点都会被剪枝(去掉),该值默认为1。
min_weight_fraction_leaf:在叶节点处的所有输入样本权重总和的最小加权分数,如果不输入则表示所有的叶节点的权重是一致的。
max_features:特征切分时考虑的最大特征数量,默认是对所有特征进行切分,也可以传入int类型的值,表示具体的特征个数;也可以是浮点数,则表示特征个数的百分比;还可以是sqrt,表示总特征数的平方根;也可以是log2,表示总特征数的log个特征。
random_state:随机种子的设置,与LR中参数一致。
max_leaf_nodes:最大叶节点个数,即数据集切分成子数据集的最大个数。
min_impurity_decrease:切分点不纯度最小减少程度,如果某个结点的不纯度减少小于这个值,那么该切分点就会被移除。
min_impurity_split:切分点最小不纯度,用来限制数据集的继续切分(决策树的生成),如果某个节点的不纯度(可以理解为分类错误率)小于这个阈值,那么该点的数据将不再进行切分。
class_weight:权重设置,主要是用于处理不平衡样本,与LR模型中的参数一致,可以自定义类别权重,也可以直接使用balanced参数值进行不平衡样本处理。
presort:是否进行预排序,默认是False,所谓预排序就是提前对特征进行排序,我们知道,决策树分割数据集的依据是,优先按照信息增益/基尼系数大的特征来进行分割的,涉及的大小就需要比较,如果不进行预排序,则会在每次分割的时候需要重新把所有特征进行计算比较一次,如果进行了预排序以后,则每次分割的时候,只需要拿排名靠前的特征就可以了。
函数方法:
decision_path(X):返回X的决策路径
fit(X, y):在数据集(X,y)上使用决策树模型
get_params([deep]):获取模型的参数
predict(X):预测数据值X的标签
predict_log_proba(X):返回每个类别的概率值的对数
predict_proba(X):返回每个类别的概率值(有几类就返回几列值)
score(X,y):返回给定测试集和对应标签的平均准确率
标签:随机选择 lsp https add 直接 就是 state aaa nts
原文地址:https://www.cnblogs.com/junge-mike/p/9335018.html