标签:.sh sys 不同 pat apache 良好的 export 获取 命名
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
Spark是一个开源的类似于Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Spark中的Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。

Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。

Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。

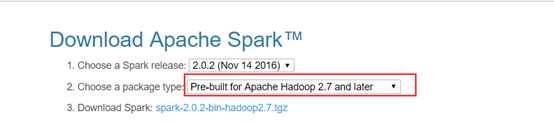
下载地址spark官网:http://spark.apache.org/downloads.html
这里我们使用 spark-2.0.2-bin-hadoop2.7版本.
/opt/bigdata
tar -zxvf spark-2.0.2-bin-hadoop2.7.tgz
mv spark-2.0.2-bin-hadoop2.7 spark
配置文件目录在 /opt/bigdata/spark/conf
#配置java环境变量 export JAVA_HOME=/opt/bigdata/jdk1.7.0_67 #指定spark老大Master的IP export SPARK_MASTER_HOST=hdp-node-01 #指定spark老大Master的端口 export SPARK_MASTER_PORT=7077
hdp-node-02
hdp-node-03
通过scp 命令将spark的安装目录拷贝到其他机器上
scp -r /opt/bigdata/spark hdp-node-02:/opt/bigdata scp -r /opt/bigdata/spark hdp-node-03:/opt/bigdata
将spark添加到环境变量,添加以下内容到 /etc/profile
export SPARK_HOME=/opt/bigdata/spark
export PATH=$PATH:$SPARK_HOME/bin
注意最后 source /etc/profile 刷新配置
#在主节点上启动spark
/opt/bigdata/spark/sbin/start-all.sh
#在主节点上停止spark集群
/opt/bigdata/spark/sbin/stop-all.sh
正常启动spark集群后,可以通过访问 http://hdp-node-01:8080,查看spark的web界面,查看相关信息。spark的web界面
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障的问题。如何解决这个单点故障的问题,Spark提供了两种方案:
(1)基于文件系统的单点恢复(Single-Node Recovery with Local File System)。
主要用于开发或测试环境。当spark提供目录保存spark Application和worker的注册信息,并将他们的恢复状态写入该目录中,这时,一旦Master发生故障,就可以通过重新启动Master进程(sbin/start-master.sh),恢复已运行的spark Application和worker的注册信息。
(2)基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)。
用于生产模式。其基本原理是通过zookeeper来选举一个Master,其他的Master处于Standby状态。将spark集群连接到同一个ZooKeeper实例并启动多个Master,利用zookeeper提供的选举和状态保存功能,可以使一个Master被选举成活着的master,而其他Master处于Standby状态。如果现任Master死去,另一个Master会通过选举产生,并恢复到旧的Master状态,然后恢复调度。整个恢复过程可能要1-2分钟。
该HA方案使用起来很简单,首先需要搭建一个zookeeper集群,然后启动zooKeeper集群,最后在不同节点上启动Master。具体配置如下:
(1)vim spark-env.sh
注释掉export SPARK_MASTER_HOST=hdp-node-01
(2)在spark-env.sh添加SPARK_DAEMON_JAVA_OPTS,内容如下:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hdp-node-01:2181,hdp-node-02:2181,hdp-node-03:2181 -Dspark.deploy.zookeeper.dir=/spark"
spark.deploy.recoveryMode:恢复模式(Master重新启动的模式)参数说明
有三种:(1)ZooKeeper (2) FileSystem (3)NONE
spark.deploy.zookeeper.url:ZooKeeper的Server地址
spark.deploy.zookeeper.dir:保存集群元数据信息的文件、目录。
包括Worker,Driver和Application。
注意:
在普通模式下启动spark集群,只需要在主机上面执行start-all.sh 就可以了。
在高可用模式下启动spark集群,先需要在任意一台节点上启动start-all.sh命令。然后在另外一台节点上单独启动master。命令start-master.sh。
Spark是基于内存计算的大数据并行计算框架。因为其基于内存计算,比Hadoop中MapReduce计算框架具有更高的实时性,同时保证了高效容错性和可伸缩性。从2009年诞生于AMPLab到现在已经成为Apache顶级开源项目,并成功应用于商业集群中,学习Spark就需要了解其架构。
Spark架构图如下:
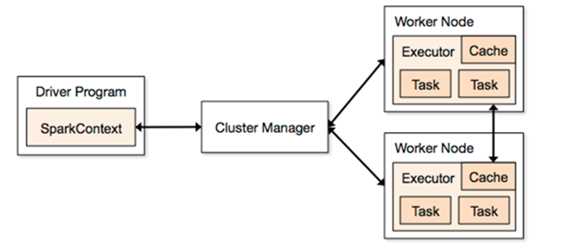
Spark架构使用了分布式计算中master-slave模型,master是集群中含有master进程的节点,slave是集群中含有worker进程的节点。
(1)Standalone: spark原生的资源管理,由Master负责资源的分配
(2)Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架
(3)Hadoop Yarn: 主要是指Yarn中的ResourceManager
标签:.sh sys 不同 pat apache 良好的 export 获取 命名
原文地址:https://www.cnblogs.com/jifengblog/p/9335752.html