标签:不同的 targe 式表 std htm 均衡 浮点 blog 编码
目录
1) 删除包含缺失值的数据列(这种方法适用于数据列包含的缺失值太多的情况) 8
使用sklearn做单机特征工程
原文链接:https://www.cnblogs.com/jasonfreak/p/5448385.html
有这么一句话在业界流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。那特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用,通过总结和归纳,人们认为特征工程包括以下方面:
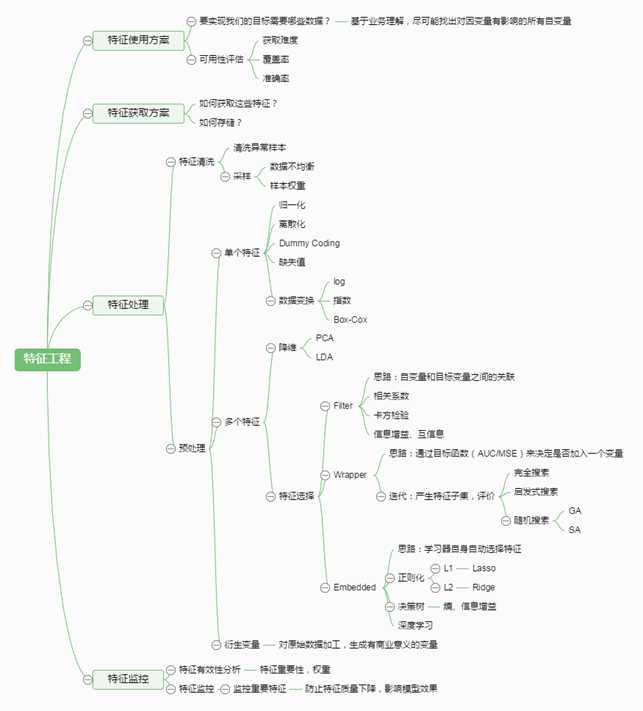
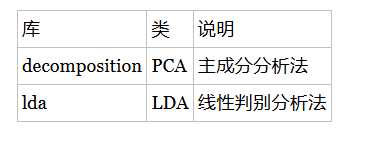
?降维(PCA、LDA)
?特征选择
特征处理时特征工程的核心部分,sklearn提供了较为完整的特征处理方法,包括数据预处理,特征选择,降维等等。首次接触到sklearn,通常会被其丰富且方便的算法模型库吸引,但是这里介绍的特征处理库也十分强大。
本文中使用sklearn中的IRIS(鸢尾花)数据集来对特征处理功能进行说明。IRIS数据集由Fisher在1936年整理,包含4个特征(Sepal.Length(花萼长度)、Sepal.Width(花萼宽度)、Petal.Length(花瓣长度)、Petal.Width(花瓣宽度)),特征值都为正浮点数,单位为厘米。目标值为鸢尾花的分类(Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),Iris Virginica(维吉尼亚鸢尾))。导入IRIS数据集的代码如下:
|
from sklearn.datasets import load_iris #导入IRIS数据集 iris = load_iris() #特征矩阵 dataset=iris.data #目标向量 labels=iris.target |
通过特征提取,我们能得到未经处理的特征,这时的特征可能有以下问题:
我们使用sklearn中的preproccessing库来进行数据预处理,可以覆盖以上问题的解决方案。
无量纲化可以加快梯度下降法收敛速度,有可能提高精度。
无量纲化使不同规格的数据转换到同一规格。常见的无量纲化方法有标准化和区间缩放法。标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0, 1]等。
1.1标准化
标准化方法是将变量的每个值与其平均值之差除以该变量的标准差,无量纲化后变量的平均值为0,标准差为1。使用该方法无量纲化后不同变量间的均值和标准差都相同,即同时消除了变量间变异程度上的差异。
标准化公式为:
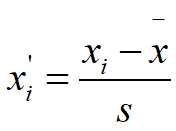
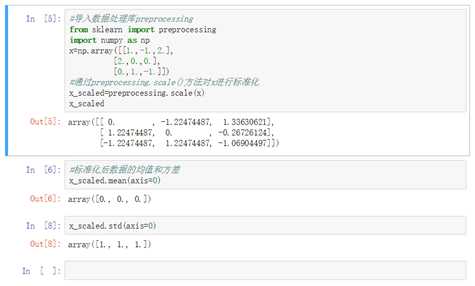
sklearn实现标准化有两种不同的方式:

其中:参数x(类数组,稀疏矩阵)
axis:int类型(默认为0),如果为0,按特征(即列)标准化;如果为1,按样本(即行)标准化
with_mean:均值,默认为真
with_std:方差,默认为真
据。
|
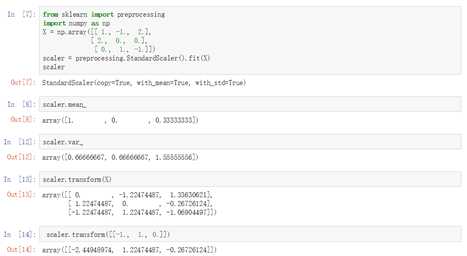
class sklearn.preprocessing.StandardScaler(copy=True, with_mean=True, with_std=True) |
通过删除平均值和缩放到单位方差来标准化特征
参数:copy:默认为True
这个类的属性:
scale_:数据的相对缩放
mean_:训练集中每个特征的均值
var_:训练集中每个特征的方差、
n_samples_seen_:int类型,样本数
这个类的方法:
fit(X[,y]):计算均值和方差为了之后的缩放
fit_transform():训练,然后标准化数据
get_params(deep=True):得到估计量的参数
inverse_transform(X, copy=None):反标准化
transform(X, y=‘deprecated‘, copy=None):标准化
1.2区间缩放法
区间缩放法的思路有多种,常见的一种是利用两个最值进行缩放,公式表达为:
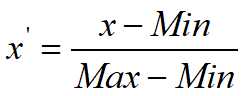
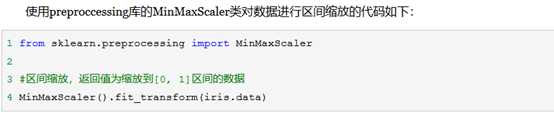
1.3归一化方法有两种
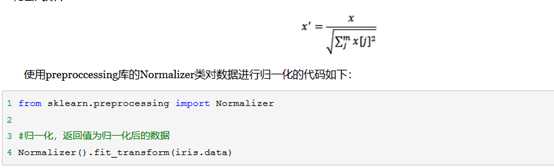
1)使用Normalizer类的方法归一化
|
class sklearn.preprocessing.Normalizer(norm=‘l2‘, copy=True) |
将样品归一化为单位范数
2)使用normalize()方法进行归一化
|
sklearn.preprocessing.normalize(X, norm=‘l2‘, axis=1, copy=True, return_norm=False) |
对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心"及格"或不"及格",那么需要将定量的考分,转换成"1"和"0"表示及格和未及格。二值化可以解决这一问题。
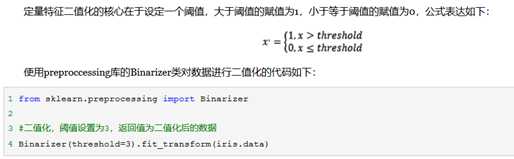

给定一个数据集,我们让编码器找到每个特征的最大值,并将数据转换为二进制的形式表现出来。
比如输入特征1的三个样本值为1,2,9,会编为一个二进制
将标签编码为不同的数字来表示不同的类别
在python语言中,缺失值一般被称为nan,是"not a number"的缩写。
下面的代码可以计算出数据总共有多少个缺失值,这里数据是存储在pandas中的DateFrame中:


在大多数情况下,我们必须在训练集(training dataset)和测试集(test dataset)中删除同样的数据列。

这种方法比直接删除数据列好点,能训练出更好的模型。

默认的填补策略是使用均值填充
如果缺失数据包含重要特征信息的话,我们需要保存原始数据的缺失信息,存储在boolearn列中

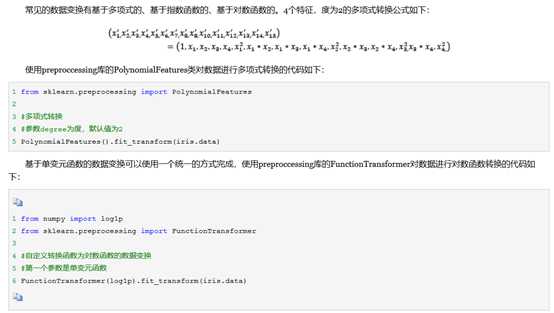
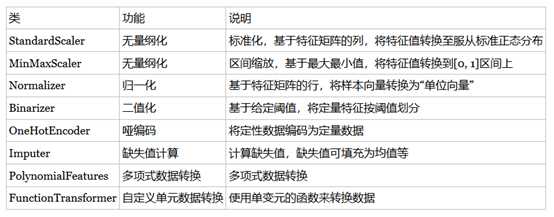
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。通常来说,
****从两个方面选择特征:
①特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么作用。
②特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优先选择。除方差法外,本文介绍的其他方法均从相关性考虑。
****根据特征选择的形式又可以将特征方法分为3种:
①Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
②Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
Embedder:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据稀疏从大到小选择特征,类似于Filter方法,但是是通过训练来确定大哥特征的优劣。
我们使用sklearn中的feature_selection库来进行特征选择。
1.Filter过滤法
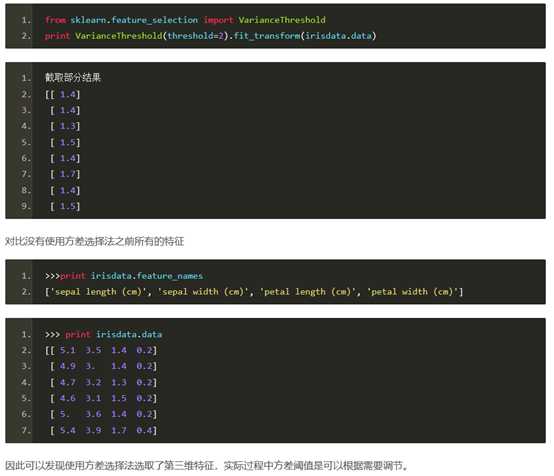
1.1方差选择法
使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。使用feature_selection库的VarianceThreshold类来选择特征的代码如下:

1.2相关系数法
使用相关系数法,先要计算各个特征对目标值得相关系数以及相关系数得P值,用feature_selection库得SelectKBest类结合相关系数来选择特征得代码如下:
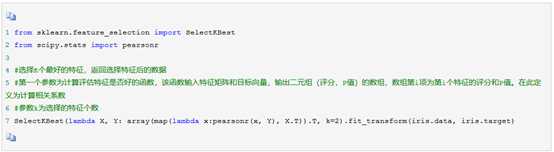
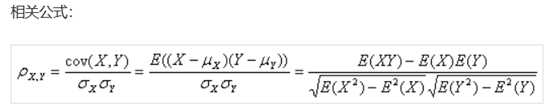
相关系数表征两组数得相关程度。
1.3卡方检验
经典得卡方检验是检验定性自变量对定性因变量得相关性。假设自变量有N中取值,因变量有M中取值,考虑自变量等于i且因变量等于j得样本频数得观察值与期望得差距,构建统计量:
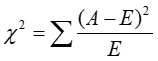
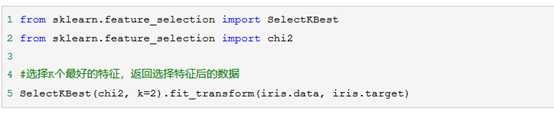
这个统计量的含义简而言之就是自变量对因变量的相关性。用feature_selection库的SelectKBest类结合卡方检验来选择特征的代码如下:
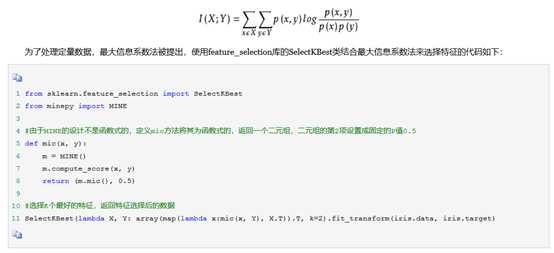
1.4互信息法
经典得互信息也是评价定性自变量对定性因变量得相关性的,互信息计算公式如下:
2.Wrapper:包装法
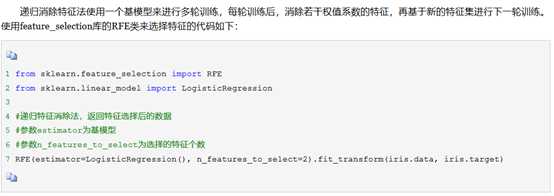
2.1递归特征消除法
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。使用feature_selection库的RFE类来选择特征的代码如下:

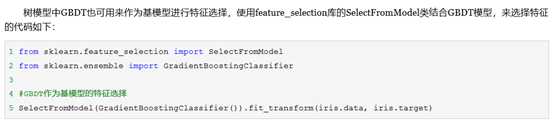
3.Embedder
3.1基于惩罚项的特征选择法
3.2基于树模型的特征选择法
4回顾

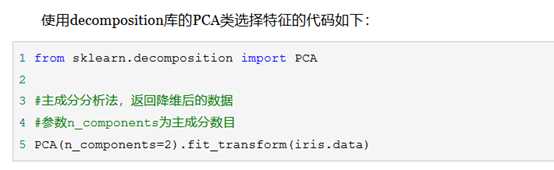
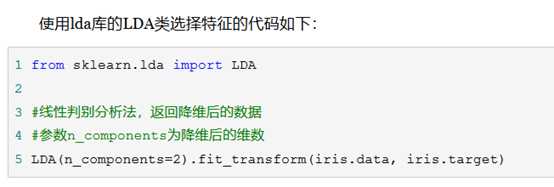
当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。常见的降维方法除了以上提到的基于L1惩罚项的模型以外,另外还有主成分分析法(PCA)和线性判别分析(LDA),线性判别分析本身也是一个分类模型。PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
再让我们回归一下本文开始的特征工程的思维导图,我们可以使用sklearn完成几乎所有特征处理的工作,而且不管是数据预处理,还是特征选择,抑或降维,它们都是通过某个类的方法fit_transform完成的,fit_transform要不只带一个参数:特征矩阵,要不带两个参数:特征矩阵加目标向量。这些难道都是巧合吗?还是故意设计成这样?方法fit_transform中有fit这一单词,它和训练模型的fit方法有关联吗?接下来,我将在《使用sklearn优雅地进行数据挖掘》中阐述其中的奥妙!
标签:不同的 targe 式表 std htm 均衡 浮点 blog 编码
原文地址:https://www.cnblogs.com/yejintianming00/p/9338959.html