标签:算法 分而治之 解决 基于 数据集 image 趋势 center 关注
基本的序列模式挖掘:主要包括一些经典算法,分为以下三类。
2)基于垂直格子的算法:SPADE算法
3)增量式序列模式挖掘:用来研究当序列增加时,如何维护序列模式,提高数据挖掘效率的问题,典型算法有:ISM算法、ISE算法、IUS算法。
4)多维序列模式挖掘:它是将多维有价值的信息融合到单位序列中,进而挖掘出最优价值的信息。典型算法有三种Uni-Seq、Seq-Dim,Dim-Seq。
5)基于约束的序列模式挖掘:目前的序列模式挖掘算法产生了大量的无用信息或者冗余信息,降低了挖掘的效率,因此提出了约束序列模式挖掘,通过添加约束条件,挖掘用户最感兴趣、最优价值的序列模式。
序列模式挖掘的发展方向:并行序列模式挖掘、周期序列模式挖掘、分布式序列模式挖掘、图序列模式挖掘
1)如何进一步提高挖掘海量数据的效率?
2)如何结合相关领域知识来解决实际问题?
3)进一步改进算方法,并将应用大数据挖掘很重。
大数据挖掘研究主要集中采用以下几种方式:
序列模式挖掘概念:
序列模式是找出序列数据库中数据之间的先后顺序。比如:用户访问某个网站各个网页的顺序,关联规则是找出事务数据库中数据之间的并发关系。比如:啤酒喝尿布。关联规则挖掘不关注事务之间的先后顺序,序列模式挖掘需要考虑序列间的先后顺序。
序列模式挖掘经典算法
存在的问题:
GSP算法基于 Apriori 理论,首先产生较短的候选项集,然后将短候选项集进行剪枝,接着通过连接生成长候选序列模式,最后计算其支持度。
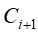 ;再次扫描序列数据库,统计每个候选序列support,然后产生长度为i+1的序列
;再次扫描序列数据库,统计每个候选序列support,然后产生长度为i+1的序列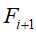 ,并将
,并将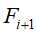 作为新种子集
作为新种子集 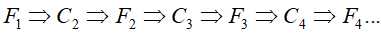
该算法基于分而治之的思想,将原始数据集进行划分,同时在分割的过程中动态地进行序列模式挖掘,并将产生的序列模式作为新的划分集。
从性能上分析,FreeSpan算法要由于类Apriori算法,它不仅能够高效的挖掘到所有长度的频繁序列,而且能够大大减少候选项集的数量
在挖掘过程中会产生大量的投影数据库,而且投影数据库一般不会缩减,另外,候选序列很多,需要考虑每一个的候选序列的组合情况
采用分而治之的思想,首先扫描序列数据库,找到所有长度为1的序列模式,把这些序列模式作为前缀,将序列数据库划分为多个小投影数据库,然后在各个投影数据库上进行递归的序列模式挖掘,效果如图所示,首先有一个序列数据库S,根据前缀划分,产生多个投影数据库 ,然后分别在这多个投影数据库中进行递归的挖掘,直到找到所有的频繁序列模式为止。
,然后分别在这多个投影数据库中进行递归的挖掘,直到找到所有的频繁序列模式为止。
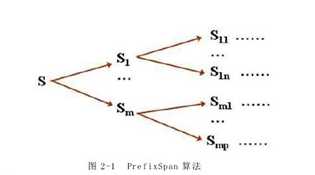
尽管PrefixSpan算法能够提升挖掘的效率,但该算法仍存在一些不足,第一:该算法需要构造大量的投影数据库,并且构造投影数据库的开销较大;第二,该算法需要递归的扫描投影数据库,耗费大量的时空代价,同时也大大降低了算法的挖掘效率;第三,该算法挖掘出的频繁序列模式,都是按照字典序进行排列,不能满足实际的需求。
(1)算法基本特性分析
下表列出了四种算法在候选序列、存储结构、数据库缩减、扫描次数、算法执行方面的对比
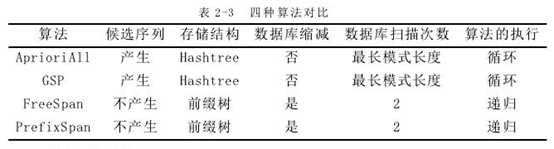
(2)执行效率分析
Apriori All 算法会产生大量的候选项集,尤其是当挖掘频繁序列长度增加时,产生
的候选项集呈现指数式增长,因此需要消耗大量的存储空间。此外还需要扫描投影数
据库,也需要消耗大量的扫描时间。尽管 GSP算法和Apriori All算法都属于Apriori类,但是GSP算法能够在一定程度上减少候选序列的数量,因此总体效率比Apriori All算法高很多。Free Span算法是基于模式增长的算法,不会产生大量的候选项集,并且每一次仅仅扫描投影数据库,而不是扫描原数据库的候选序列,比类 Apriori 的算法效率要高的多,尤其在支持度较低时更为明显。Free Span 的缺点有两个方面:(1)在挖掘的过程中会产生大量的投影数据库。(2)产生的候选序列很多,需要考虑每一个候选序列的组合情况,因此造成了很大的开销。Prefixspan算法是对Free Span算法的改进,不会产生候选序列模式,另外Prefix Span算法也需要构造大量的投影数据库,造成较大的开销但Prefix Span算法比Free Span算法的收缩速度快,它能够大大缩减搜索空间,缩小投影数据库的规模。
标签:算法 分而治之 解决 基于 数据集 image 趋势 center 关注
原文地址:https://www.cnblogs.com/yejintianming00/p/9339708.html