标签:分析 remote code gcc 海量 sof style 注意 系统
clickhouse是由俄罗斯Yandex公司开发的列式存储数据库,于2016年开源,clickhouse的定位是快速的数据分析,对于处理海量数据的情况性能非常好,在网上也有很多测试的案例,在大数据的情况下性能远超过其他数据库,并且不依赖于hadoop的生态系统,都是独立使用,在大数据存储业务上还是可以考虑的.
clickhouse官网地址:https://clickhouse.yandex/,文档地址:https://clickhouse.yandex/docs/en/
另外推荐单页文档,更方便:https://clickhouse.yandex/docs/en/single/
clickhouse有两种安装方式,第一种是使用编译好的包安装,第二种是编译源码安装,编译源码需要gcc 7的支持,前几天在centos 7下编译一直是遇到各种问题没成功,所以今天主要写一下rpm包的方式安装,之后如果搞出来会继续补充,如果有哪位大牛路过,还请多多指点,必定虚心请教^_^. 编译安装的文档页面:https://clickhouse.yandex/docs/en/development/build/
如果是ubuntu或者debian的系统,那么安装非常方便,安装文档开始给出的就是这个方法,但是对于centos 7系统,官方也是给出了安装页面,但是会跳到Altinity也就是大名鼎鼎的领英网的github页面,altinity编译并且发布了rpm包,良心项目,果断支持,安装页面在:https://github.com/Altinity/clickhouse-rpm-install,页面中给出了更新yum源安装的方式,但是网速奇慢,可以在网上搜到rpm包的直接下载地址,这里贴出来:
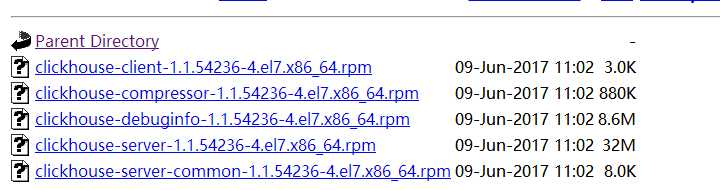
clickhouse共需要这6个rpm包,都下载下来之后直接使用rpm -ivh后面跟上所有的包安装就可以了,基本上不缺少其他依赖,安装之后clickhouse会自动加到systemd启动当中,安装后主要的目录分布如下:
/etc/clickhouse-server clickhouse服务的配置文件目录,包括:config.xml和users.xml
/etc/clickhouse-client clickhouse客户端的配置文件目录,里面只有一个config.xml并且默认为空
/var/lib/clickhouse clickhouse默认数据目录
/var/log/clickhouse-server clickhouse默认日志目录
/etc/init.d/clickhouse-server clickhouse启动shell脚本,用来方便启动服务的.
/etc/security/limits.d/clickhouse.conf 最大文件打开数的配置,这个在config.xml也可以配置
/etc/cron.d/clickhouse-server clickhouse定时任务配置,默认没有任务,但是如果文件不存在启动会报错.
/usr/bin clickhouse编译好的可执行文件目录,主要有下面几个:
clickhouse clickhouse主程序可执行文件
clickhouse-compressor
clickhouse-client 是一个软链指向clickhouse,主要是客户端连接操作使用
clickhouse-server 是一个软链接指向clickhouse,主要是服务操作使用
注意:虽然clickhouse-client是一个软链,但是执行这个软链是进入默认客户端,但是执行clickhouse却不行,需要加--client参数,这个需要注意,还是客户端和服务命令分开使用比较好.
根据上面目录我们可以将这些主要的文件收集下来,打成安装包,那么其他机器安装就完全不需要重新安装了,直接执行编译好的二进制即可,并且这个二进制不依赖其他的系统库,这里使用tree打包后的目录结构如下:
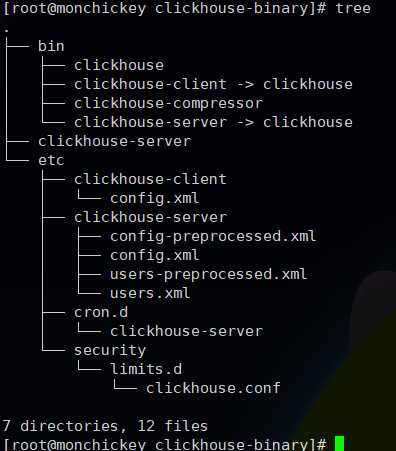
这样的话放到解压到其他服务器就可以直接使用了,不过还有一些地方需要注意,下面说一下.
在其他机器解压后,首先需要建立clickhouse用户,因为使用rpm默认会创建好这个用户,所以需要手动创建,命令如下:
useradd clickhouse -d /data/clickhouse -c ‘Clickhouse server‘ -s /sbin/nologin
其中-d指定clickhouse的数据目录,目录会自动创建并且权限为clickhouse的用户和组,然后需要修改clickhouse相关的配置:
config.xml配置
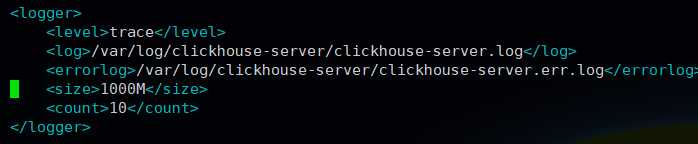
日志配置,根据需要修改,并且没有需要创建并且做授权,比如:
mkdir /var/log/clickhouse-server chown -R clickhouse:clickhouse /var/log/clickhouse-server
http端口号配置:<http_port>8123</http_port>
tcp端口号配置:<tcp_port>9000</tcp_port>
副本之间的数据交换端口:<interserver_http_port>9009</interserver_http_port>,这个多个实例单独配置即可,不同端口clickhouse自动协调交换副本不受影响.
监听地址:
<listen_host>::1</listen_host>
<listen_host>127.0.0.1</listen_host>
默认是监听的本地ipv4和ipv6地址,实际运行的时候要追加上一条真实ip.
数据目录配置:<path>/var/lib/clickhouse/</path>,需要提前创建并且授予clickhouse用户权限,这里改为/data/clickhouse
临时数据目录配置:<tmp_path>/var/lib/clickhouse/tmp/</tmp_path>,这里就配置在上面数据目录下的tmp目录即可,会自动创建
导入用户配置:<users_config>users.xml</users_config>,就是另一个配置文件users.xml
分布式配置:<remote_servers incl="clickhouse_remote_servers" />,这个后续文章会专门讲.
zookeeper复制:<zookeeper incl="zookeeper-servers" optional="true" />,这个也会讲.
副本定义:<macros incl="macros" optional="true" />
基本配置就是上面这些,更多的配置根据需要修改,最后这3个分布式高可用配置,后续会专门写一个文章.
修改好config.xml配置之后,然后可以将cron.d和security下面的文件拷贝到对应的目录中去.
现在其实就可以调用clickhouse-server二进制文件启动了,但是为了方便启动和管理我们可以修改外层clickhouse-server这个脚本启动,主要修改内容如下:
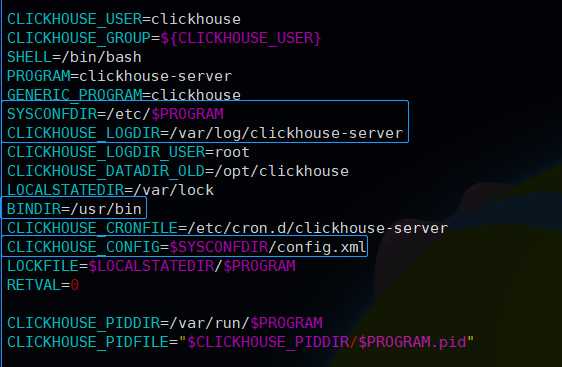
其实就需要修改配置文件目录,日志目录和二进制目录即可,pid文件根据需要修改,保存后可以执行 ./clickhouse-server start 启动,然后通过 ./bin/clickhouse-client 即可进入默认9000端口的客户端了,这样clickhouse的单机配置就可以了,之后会介绍clickhouse分布式以及复制的配置.
标签:分析 remote code gcc 海量 sof style 注意 系统
原文地址:https://www.cnblogs.com/freeweb/p/9343011.html