标签:ini version 16px src fetch strong shel start select
1 1、需要用时,即时配置,在cli执行属性设置,这种配置方式,当重新打开cli时,就会生效: 2 hive> set hive.cli.print.current.db=true; 3 4 2、一次配置,永久生效,在当前用户的HOME目录下,新建.hiverc文件,把属性设置命令放置到该文件中,每次打开cli时,都会先执行该文件。 5 [yun@mini01 ~]$ pwd 6 /app 7 [yun@mini01 ~]$ cat .hiverc 8 set hive.cli.print.current.db=true; 9 10 3、在hive配置文件中添加配置【推荐】,上一篇文章hive配置中已经有了该配置项 11 <!-- 显示当前使用的数据库 --> 12 <property> 13 <name>hive.cli.print.current.db</name> 14 <value>true</value> 15 <description>Whether to include the current database in the Hive prompt.</description> 16 </property>
1 # 没有显示当前使用库 2 [yun@mini01 ~]$ hive 3 4 Logging initialized using configuration in jar:file:/app/hive-1.2.1/lib/hive-common-1.2.1.jar!/hive-log4j.properties 5 hive> show databases; # 默认库为default 6 OK 7 default 8 Time taken: 0.774 seconds, Fetched: 1 row(s) 9 # 创建库 10 hive> create database zhang; 11 OK 12 Time taken: 0.168 seconds 13 hive> show databases; 14 OK 15 default 16 zhang 17 Time taken: 0.02 seconds, Fetched: 2 row(s)
浏览器访问
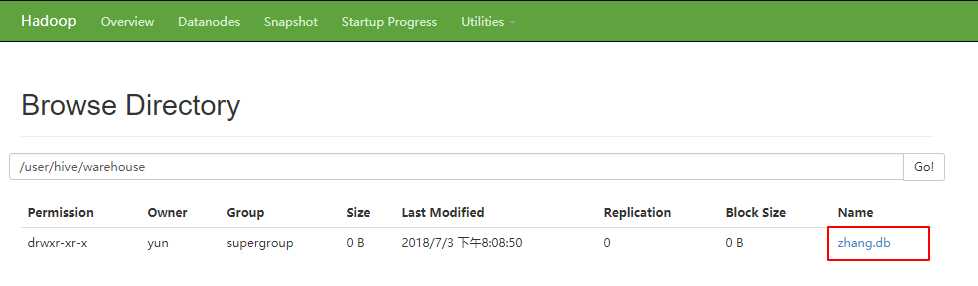
1 # 默认显示当前使用库 2 hive (default)> show databases; 3 OK 4 default 5 zhang 6 Time taken: 0.729 seconds, Fetched: 2 row(s) 7 hive (default)> use zhang; 8 OK 9 Time taken: 0.036 seconds 10 hive (zhang)> create table t_sz01(id int, name string) 11 > row format delimited 12 > fields terminated by ‘,‘; 13 OK 14 Time taken: 0.187 seconds 15 hive (zhang)> show tables; 16 OK 17 t_sz01 18 Time taken: 0.031 seconds, Fetched: 1 row(s)
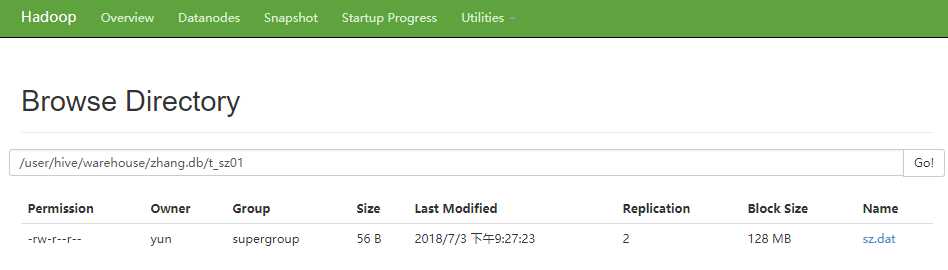
浏览器访问
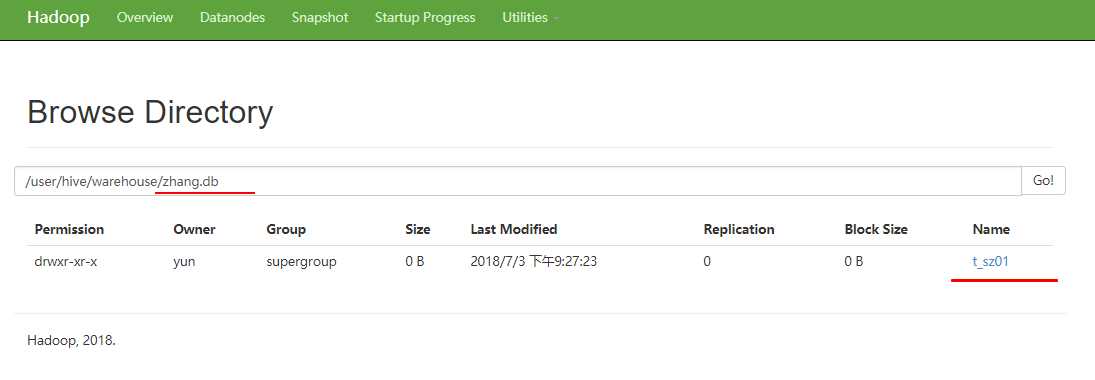
1 [yun@mini01 hive]$ cat sz.dat 2 1,zhangsan 3 5,李四 4 3,wangwu 5 2,赵六 6 4,zhouqi 7 6,孙八 8 [yun@mini01 hive]$ hadoop fs -put sz.dat /user/hive/warehouse/zhang.db/t_sz01 # 上传 9 [yun@mini01 hive]$ hadoop fs -ls /user/hive/warehouse/zhang.db/t_sz01/ 10 Found 1 items 11 -rw-r--r-- 2 yun supergroup 56 2018-07-03 21:27 /user/hive/warehouse/zhang.db/t_sz01/sz.dat 12 [yun@mini01 hive]$ hadoop fs -cat /user/hive/warehouse/zhang.db/t_sz01/sz.dat 13 1,zhangsan 14 5,李四 15 3,wangwu 16 2,赵六 17 4,zhouqi 18 6,孙八
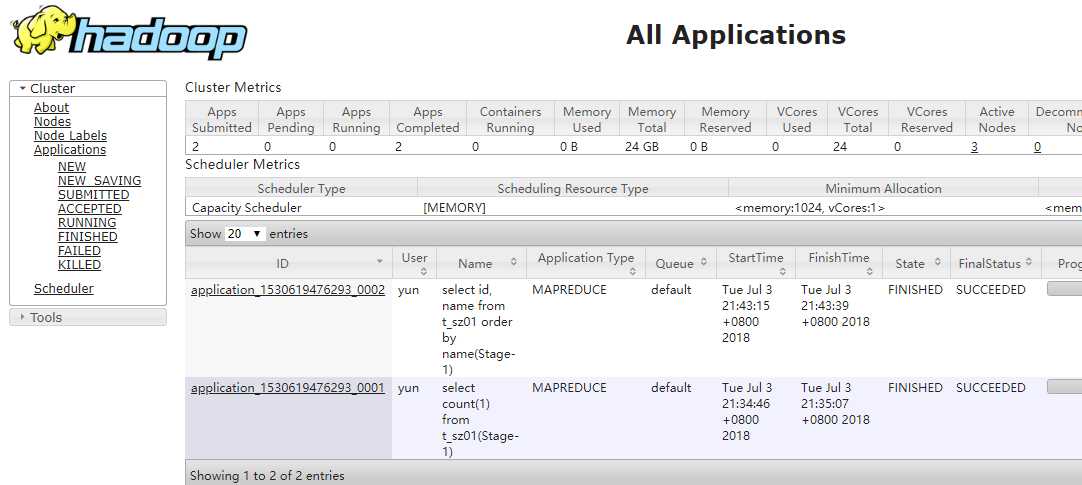
1 hive (zhang)> show tables; 2 OK 3 t_sz01 4 Time taken: 0.028 seconds, Fetched: 1 row(s) 5 hive (zhang)> select * from t_sz01; # 全表查询 6 OK 7 1 zhangsan 8 5 李四 9 3 wangwu 10 2 赵六 11 4 zhouqi 12 6 孙八 13 Time taken: 0.264 seconds, Fetched: 6 row(s) 14 hive (zhang)> select count(1) from t_sz01; # 表数据条数 15 Query ID = yun_20180703213443_ebca743c-2025-405a-8832-59359e1566c2 16 Total jobs = 1 17 Launching Job 1 out of 1 18 Number of reduce tasks determined at compile time: 1 19 In order to change the average load for a reducer (in bytes): 20 set hive.exec.reducers.bytes.per.reducer=<number> 21 In order to limit the maximum number of reducers: 22 set hive.exec.reducers.max=<number> 23 In order to set a constant number of reducers: 24 set mapreduce.job.reduces=<number> 25 Starting Job = job_1530619476293_0001, Tracking URL = http://mini02:8088/proxy/application_1530619476293_0001/ 26 Kill Command = /app/hadoop/bin/hadoop job -kill job_1530619476293_0001 27 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 28 2018-07-03 21:34:53,810 Stage-1 map = 0%, reduce = 0% 29 2018-07-03 21:35:00,224 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.5 sec 30 2018-07-03 21:35:07,882 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.37 sec 31 MapReduce Total cumulative CPU time: 6 seconds 370 msec 32 Ended Job = job_1530619476293_0001 33 MapReduce Jobs Launched: 34 Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 6.37 sec HDFS Read: 6513 HDFS Write: 2 SUCCESS 35 Total MapReduce CPU Time Spent: 6 seconds 370 msec 36 OK 37 6 38 Time taken: 25.312 seconds, Fetched: 1 row(s) 39 hive (zhang)> select id,name from t_sz01 where id >3; # 查询id>3 40 OK 41 5 李四 42 4 zhouqi 43 6 孙八 44 Time taken: 0.126 seconds, Fetched: 3 row(s) 45 hive (zhang)> select id,name from t_sz01 where id >3 limit 2; # 不能使用 limit m,n 46 OK 47 5 李四 48 4 zhouqi 49 Time taken: 0.072 seconds, Fetched: 2 row(s) 50 hive (zhang)> select id, name from t_sz01 order by name; # 使用order by 排序 51 Query ID = yun_20180703214314_db222afe-3287-4c8e-8077-73aa4fec62ef 52 Total jobs = 1 53 Launching Job 1 out of 1 54 Number of reduce tasks determined at compile time: 1 55 In order to change the average load for a reducer (in bytes): 56 set hive.exec.reducers.bytes.per.reducer=<number> 57 In order to limit the maximum number of reducers: 58 set hive.exec.reducers.max=<number> 59 In order to set a constant number of reducers: 60 set mapreduce.job.reduces=<number> 61 Starting Job = job_1530619476293_0002, Tracking URL = http://mini02:8088/proxy/application_1530619476293_0002/ 62 Kill Command = /app/hadoop/bin/hadoop job -kill job_1530619476293_0002 63 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 64 2018-07-03 21:43:25,676 Stage-1 map = 0%, reduce = 0% 65 2018-07-03 21:43:34,166 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.64 sec 66 2018-07-03 21:43:40,606 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.85 sec 67 MapReduce Total cumulative CPU time: 4 seconds 850 msec 68 Ended Job = job_1530619476293_0002 69 MapReduce Jobs Launched: 70 Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.85 sec HDFS Read: 5789 HDFS Write: 74 SUCCESS 71 Total MapReduce CPU Time Spent: 4 seconds 850 msec 72 OK 73 3 wangwu 74 1 zhangsan 75 4 zhouqi 76 6 孙八 77 5 李四 78 2 赵六 79 Time taken: 26.768 seconds, Fetched: 6 row(s)
MapReduce信息
1 http://mini02:8088
1 # 之间已经添加环境变量 2 [yun@mini01 ~]$ hive
启动方式,(例如是在mini01上):
1 # 之间已经添加环境变量 2 启动为前台: hiveserver2 3 启动为后台: nohup hiveserver2 1>/app/hive/logs/hiveserver.log 2>/app/hive/logs/hiveserver.err & 4 # 没有 /app/hive/logs 目录就创建
启动成功后,可以在别的节点上用beeline去连接
方式1
1 # 由于没有在其他机器安装,所以还是在本机用beeline去连接 2 [yun@mini01 bin]$ beeline 3 Beeline version 1.2.1 by Apache Hive 4 beeline> !connect jdbc:hive2://mini01:10000 # jdbc连接 可以是mini01、127.0.0.0、10.0.0.11、172.16.1.11 5 Connecting to jdbc:hive2://mini01:10000 6 Enter username for jdbc:hive2://mini01:10000: yun 7 Enter password for jdbc:hive2://mini01:10000: 8 Connected to: Apache Hive (version 1.2.1) 9 Driver: Hive JDBC (version 1.2.1) 10 Transaction isolation: TRANSACTION_REPEATABLE_READ 11 0: jdbc:hive2://mini01:10000>
方式2
1 # 或者启动就连接: 2 [yun@mini01 ~]$ beeline -u jdbc:hive2://mi
接下来就可以做正常sql查询了
例如:
1 0: jdbc:hive2://mini01:10000> show databases; 2 +----------------+--+ 3 | database_name | 4 +----------------+--+ 5 | default | 6 | zhang | 7 +----------------+--+ 8 2 rows selected (0.437 seconds) 9 0: jdbc:hive2://mini01:10000> use zhang; 10 No rows affected (0.058 seconds) 11 0: jdbc:hive2://mini01:10000> show tables; 12 +-----------+--+ 13 | tab_name | 14 +-----------+--+ 15 | t_sz01 | 16 +-----------+--+ 17 1 row selected (0.054 seconds) 18 0: jdbc:hive2://mini01:10000> select * from t_sz01; 19 +------------+--------------+--+ 20 | t_sz01.id | t_sz01.name | 21 +------------+--------------+--+ 22 | 1 | zhangsan | 23 | 5 | 李四 | 24 | 3 | wangwu | 25 | 2 | 赵六 | 26 | 4 | zhouqi | 27 | 6 | 孙八 | 28 +------------+--------------+--+ 29 6 rows selected (0.641 seconds) 30 0: jdbc:hive2://10.0.0.11:10000> select count(1) from t_sz01; # 条数查询 31 INFO : Number of reduce tasks determined at compile time: 1 32 INFO : In order to change the average load for a reducer (in bytes): 33 INFO : set hive.exec.reducers.bytes.per.reducer=<number> 34 INFO : In order to limit the maximum number of reducers: 35 INFO : set hive.exec.reducers.max=<number> 36 INFO : In order to set a constant number of reducers: 37 INFO : set mapreduce.job.reduces=<number> 38 INFO : number of splits:1 39 INFO : Submitting tokens for job: job_1530619476293_0003 40 INFO : The url to track the job: http://mini02:8088/proxy/application_1530619476293_0003/ 41 INFO : Starting Job = job_1530619476293_0003, Tracking URL = http://mini02:8088/proxy/application_1530619476293_0003/ 42 INFO : Kill Command = /app/hadoop/bin/hadoop job -kill job_1530619476293_0003 43 INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 44 INFO : 2018-07-03 22:58:43,405 Stage-1 map = 0%, reduce = 0% 45 INFO : 2018-07-03 22:58:49,882 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.56 sec 46 INFO : 2018-07-03 22:58:57,815 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.28 sec 47 INFO : MapReduce Total cumulative CPU time: 5 seconds 280 msec 48 INFO : Ended Job = job_1530619476293_0003 49 +------+--+ 50 | _c0 | 51 +------+--+ 52 | 6 | 53 +------+--+ 54 1 row selected (25.433 seconds)
1、Hive创建表格报【Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask.
标签:ini version 16px src fetch strong shel start select
原文地址:https://www.cnblogs.com/zhanglianghhh/p/9348958.html