标签:proposal 固定 依赖 锚点 其他 需要 矩形区域 fast 分布
 ?
?
| 术语 | 描述 |
|---|---|
| RoI | Region of Interest |
| RPN | Region Proposal Network |
| FRCN | Fast RCNN |
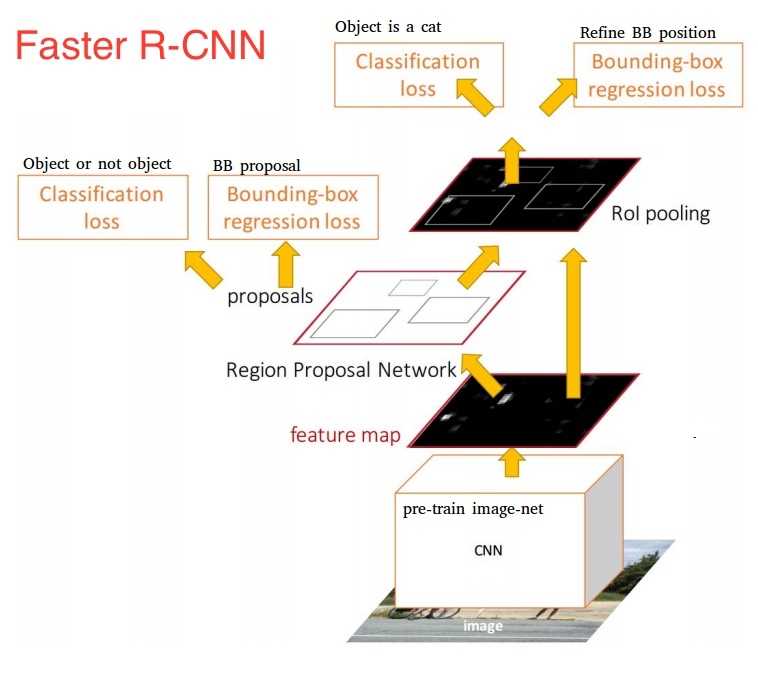
Faster R-CNN,由两个模块组成:
第一个模块是深度全卷积网络 RPN,用于 region proposal;
第二个模块是 Fast R-CNN 检测器,它使用了RPN产生的region proposal进行检测。
 ?
?
网络输入
网络输出
目标检测的两大困难
主要贡献: 简化了 RCNN 训练步骤;
性能: VOC2007/2010, mAP 约为 66.7%;
前向传播
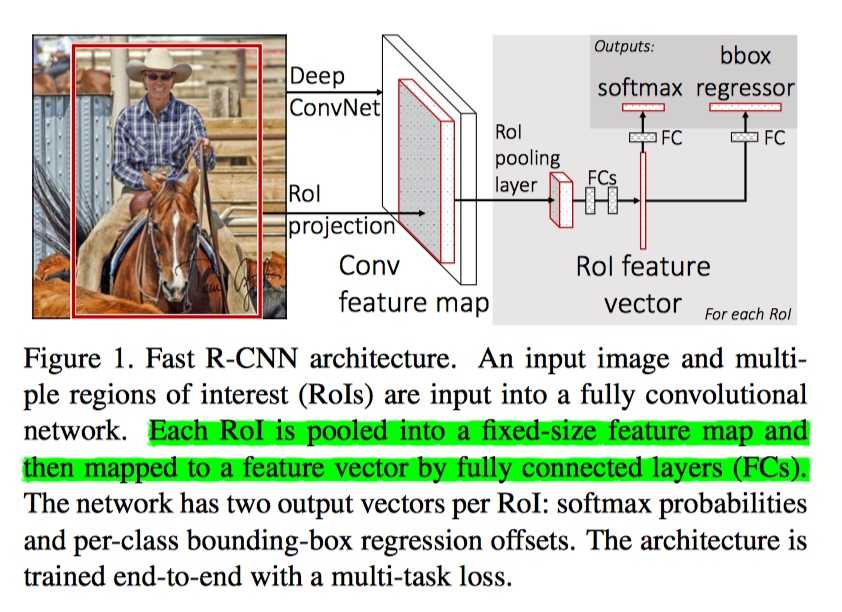
网络首先使用卷积层和最大池化层处理整个图像生成 feature map。 然后,对于每个 object proposal,RoI池化层从 feature map 中提取固定长度的特征向量。每个特征向量被馈送到全连接层,最终输入到两个输出层, 为 (N类+背景类)分类器和 Bounding Box 回归器.
RoI定义:
可以说是最后一个卷积 feature map 上的一个矩形区域, 每个 RoI 由四元组(r,c,h,w)定义,为其左上角(r,c) 及其高度和宽度(h,w);
那么 RoI 是如何产生的呢 ?
我们先来看看 Region Proposal 是什么? 即输入图片上的一个矩形区域, 二者的映射关系, 大约为卷积网络所有的 downsampling strirde 相乘, 将 Region Proposal 映射到最后一个卷积 feature map 上的一个矩形区域上.
那么我们获得 RoI 之后, 怎么处理它呢?
这就说要这一节的主角啦, RoI 池化层(RoI pooling layer 或 RoI max pooling), 它的作用是将高宽为 h×w RoI 窗口划分为包含 H×W 个大小约 \(\frac{h}{H}×\frac{w}{W}\) 的子窗口的网格,然后将每个子窗口中的最大值汇集到相应的输出网格单元中来, 其中 H 和 W 是超参数, 独立于任何特定的 RoI。
损失函数设计
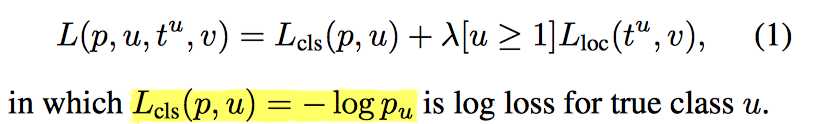 ?
?
 ?
?
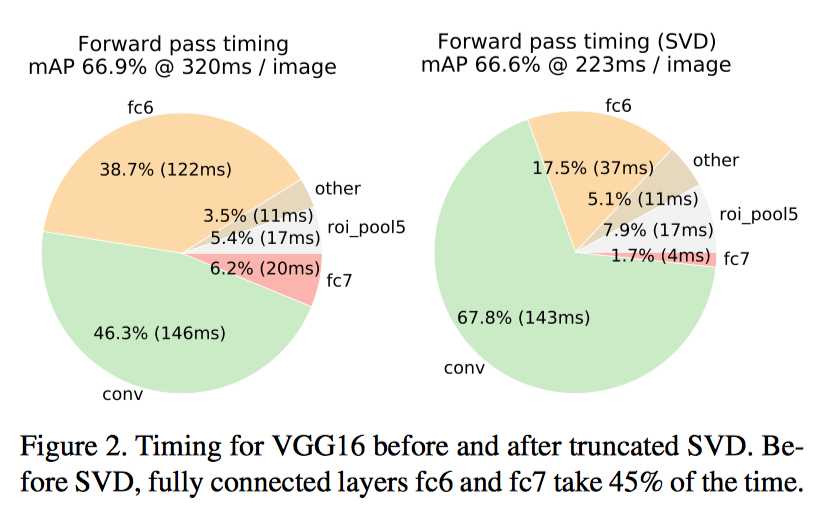
对于图像分类来说,与卷积层相比,计算全连接层所花费的时间很少。而对于检测问题来说,由于要处理的 RoI 的数量很大,并且有近一半的正向传播时间用于计算全连接层。 通过截断的 SVD 压缩, 可以很容易地加速大的全连接层的计算速度。
\[W ≈ UΣ_t V^T\]
 ?
?
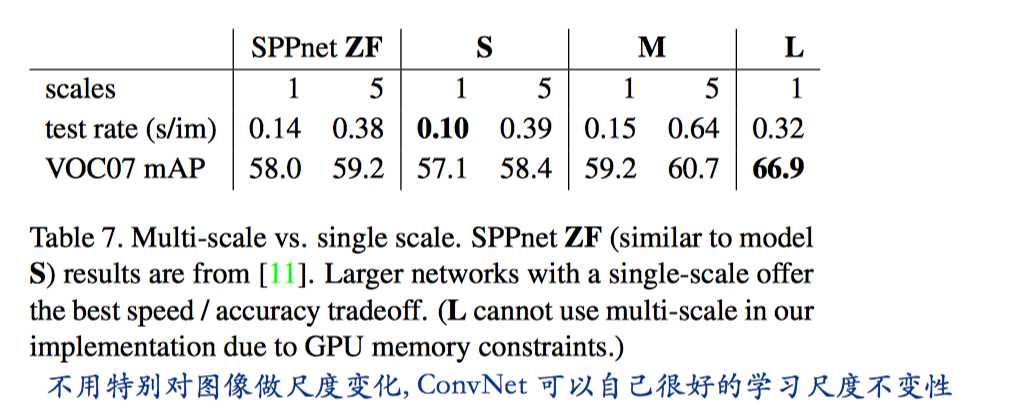
Scale invariance: to brute force or finesse ?
 ?
?
卷积神经网络的第一层是通用的,任务无关的,所以检测微调时, 不需要考虑第一层, FRCN 从 conv_3 层开始微调
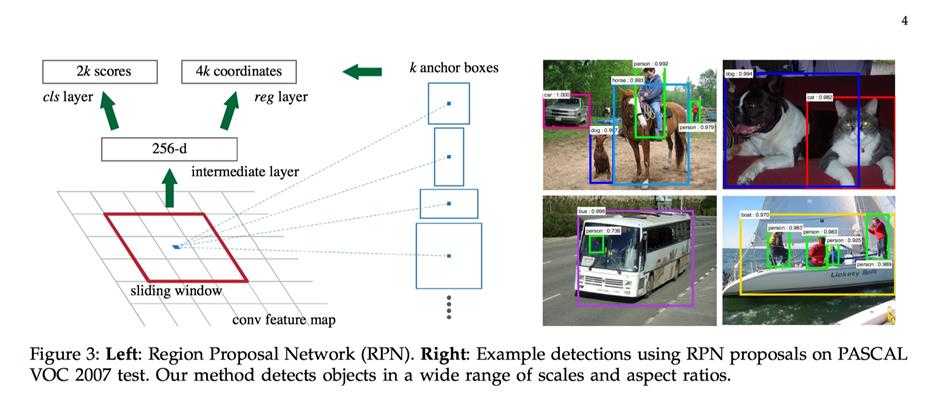
RPN 的提出, 将 region proposal 融入 CNN 网络中, 整个系统是一个单一的,统一的对象检测网络。 具体为使用 RPN 的技术代替之前 Selection Search, 完成 region proposal, 那么 RPN 需要完成两个任务:
RPN 提出的是在图片上的坐标, 然后通过 RoI 映射投影到最后一层卷积 feature map 上
下面我们说说是训练 RPN 的事, 首先看看 RPN 是什么?
RPN 输入输出就如下,
输入: 整张图片
输出: objectness classification + bounding box regression
\(\color{red}{\bf来说说 RPN 中关键概念 \space anchor}\)
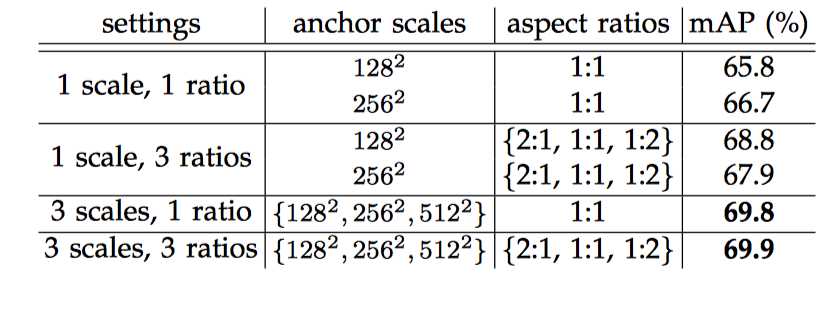
anchor 其实就是预训练网络卷积层的最后一层 feature map 上的一个像素,以该 anchor 为中心(更确切的说是以 feature map 的尺寸 SxS 分割输入图像为 SxS 个 cell, 将 anchor 对应于相应cell的中心, 然后通过尺寸和宽高比在图像上形成 anchor boxes),可以生成 k 种 anchor boxes(理解为 region proposal 就好了); 每个 anchor box 对应有一组缩放比例( scale)和宽高比(aspect). 论文中共使用 3 种 scale(128, 256, 512), 3 种 aspect(1:2, 1:1, 2:1), 所以每个 anchor 位置产生 9 个 anchor boxs.
 ?
?
为何要提出 anchor呢?
来说说 anchor 的优点: 它只依赖与单个 scale 的 images 和 feature map, 滑动窗口也只使用一个尺寸的 filter. 不过却能解决 multiple scales and sizes的问题.
为何选择 128 ,256, 512? 论文中用到的网络如 ZFNet 在最后一层卷积层的 feature map 上的一个像素的感受野就有 171(如何计算感受野看这里), filter size 3x3, 3x171=513. 而且论文中提到: 我们的算法允许比底层接受域更大的预测。 这样的预测并非不可能 - 如果只有对象的中间部分是可见的,那么仍然可以大致推断出对象的范围。
在预训练网络卷积层的最后一层 feature map 上进行 3x3 的卷积, anchor 就位于卷积核的中心位置.
记住这里 anchor boxes 坐标对应的就是在图片上的坐标, 而不是在最后一层卷积层 feature map 上的坐标.
anchor box 这么简单粗暴, 为什么有效?
列举了这么多, 相当于穷举了吧, 比如论文中所说,由于最后一层的全局 stride 为16, 那么100x600 的图片就能生成大约 60x40x9≈20000个 anchor boxes). 当然列举了这么多 anchor boxes, 这region proposal 也太粗糙啊, 总不能就这样把这么多的质量层次不齐 anchor boxes 都送给 Fast R-CNN来检测吧. 那该怎么剔除质量不好的呢? 这就是后面 RPN 的 bounding box regression 和 objectness classification 要解决的事情:)
有必要先说说 RPN 的 objectness classification 和 bounding box regression 有什么用?
一句话就是 "少生优育"
bounding box regression: 调整输入的 anchor boxer 的坐标, 使它更接近真实值, 就是一个 bbox regression, 输出称为 RPN proposal, 或者 RoIs. 提高 anchor boxer 的质量
objectness classification: 一些 RPN proposal(anchor boxer经过)可能相互重叠度很高, 为了减少冗余, 通过objectness classification的输出的分数score 对这些RPN proposal做 NMS(non-maximum suppression), 论文中设置threshold 为 0.7, 只保留 threshold < 0.7 的RPN proposal, 减少 anchor boxes 的数量
RPN 的任务是什么?
训练 RPN 网络来选择那些比较好的 anchor boxes.
因为现在我们要训练 RPN, 我们只提出了 anchor boxer, 却不知道这些 anchor boxes是不是包含物体, 就是没有标签啊! 那么问题来了? objectness classification 分类时没有标签啊. 怎么办?
办法就是使用 image 检测用 gt-bbox(ground-truth bounding box), 注意这里我们只是检测图片中有没有物体, 而不判断是哪一类物体.
positive anchors
与任意 gt-box 的 IoU > 0.7, 或者具有最大 IoU, 即标记为1, 就是包含物体, 当然该 gt-box 就是 anchor boxes bounding box regression任务对应的标签
negative anchors
与任意 gt-box 的 IoU < 0.3, 即标记为 negative anchor, 标记为0, 就是不包含物体, 是背景, 从后面的损失函数知道, 背景不参与回归损失函数.
IoU 位于 positive anchors, negative anchors 之间 anchor boxer 背景和物体掺杂, 的对于训练目标没有贡献, 不使用.
注意一点, 每个 regressor 只负责一个 <scale, aspect>, 不与它 regressor共享权重, 所以需要训练 k 个 regressor.
其他不多说, 只贴贴公式
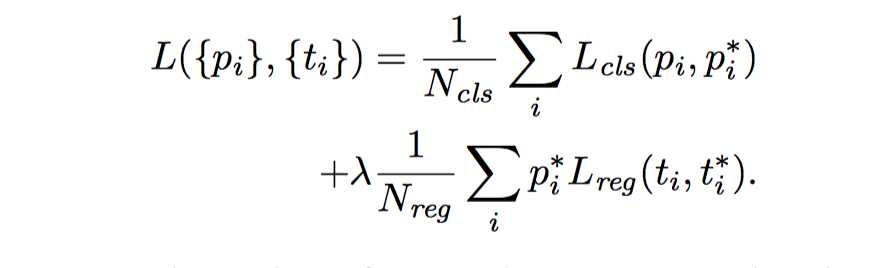 ?
?
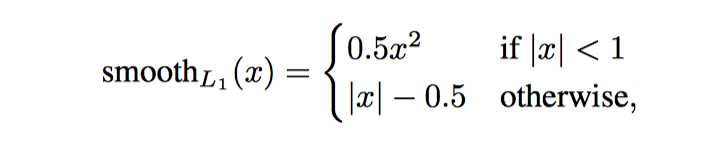 ?
?
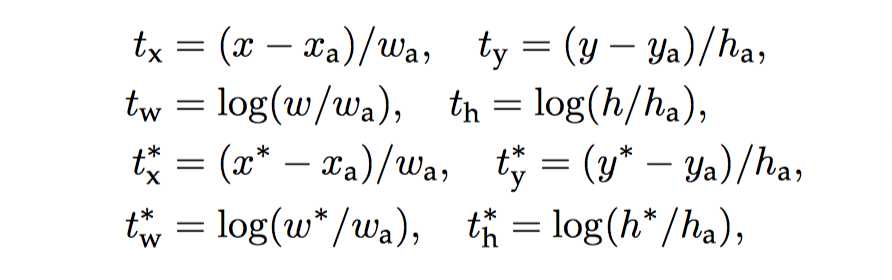 ?
?
交替训练: 在这个解决方案中,我们首先训练 RPN,并使用这些 proposal 来训练 Fast R-CNN。 由 Fast R-CNN 调节的网络然后用于初始化 RPN,并且该过程被重复。
细节:
re-size image 最短边为 600 像素
total stride for ZFNet, VGGNet 16 pixels
跨图像边缘的 anchor boxes 处理
跨越图像边界的 anchor boxes 需要小心处理。 在训练期间,忽略了所有的跨界 anchor boxes,所以他们不会影响损失函数。 对于典型的1000×600图像,总共将有大约20000个(≈60×40×9)anchor boxes。 在忽略跨界锚点的情况下,每个图像有大约 6000 个 anchor boxes 用于训练。 如果跨界异常值在训练中不被忽略,它们会引入大的难以纠正误差项的,并且训练不会收敛。 然而,在测试过程中,我们仍然将完全卷积RPN应用于整个图像。 这可能会生成跨边界anchor boxes,我们将其剪切到图像边界(即将坐标限制在图片坐标内)。
 ?
?
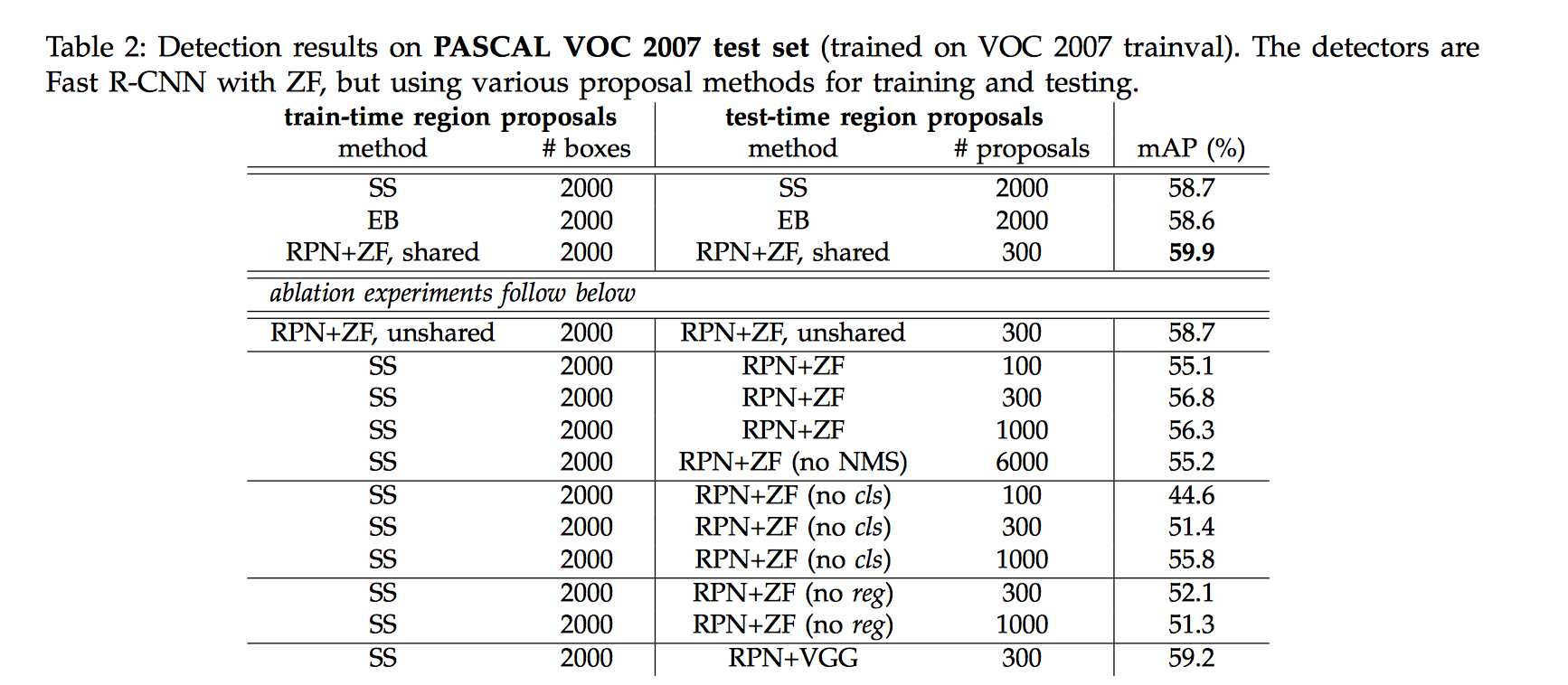
RPN+FRCN( ZFNet), mAP=59.9
RPN+FRCN( VGGNet), mAP=69.9
 ?
?
标签:proposal 固定 依赖 锚点 其他 需要 矩形区域 fast 分布
原文地址:https://www.cnblogs.com/nowgood/p/FasterRCNN.html