标签:数组 用处 继承 serial 效率 安全 素数 简单 方法
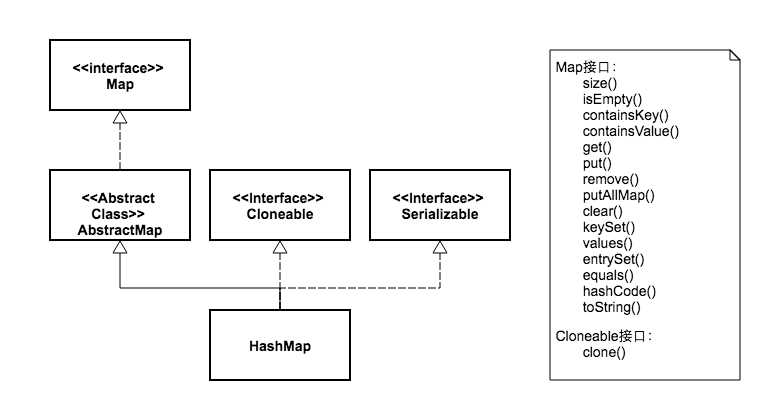
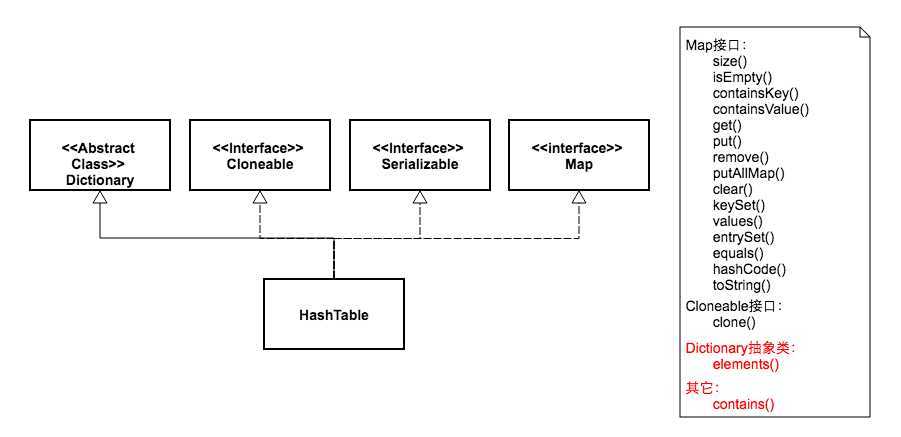
HashMap是继承自AbstractMap类,而HashTable是继承自Dictionary类(Dictionary类是一个已经被废弃的类)。不过它们都实现了同时实现了map、Cloneable(可复制)、Serializable(可序列化)这三个接口。
HashTable比HashMap多了两个公开方法。一个是elements,这来自于抽象类Dictionary,鉴于该类已经废弃,所以这个方法也就没什么用处了。另一个多出来的方法是contains,这个多出来的方法也没什么用,因为它跟containsValue方法功能是一样的。
HashMap是支持null键和null值的,而HashTable在遇到null时,会抛出NullPointerException异常。这并不是因为HashTable有什么特殊的实现层面的原因导致不能支持null键和null值,这仅仅是因为HashMap在实现时对null做了特殊处理,将null的hashCode值定为了0,从而将其存放在哈希表的第0个bucket中。
Hashtable是线程安全的,它的每个方法中都加入了Synchronize方法。在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步。
HashMap不是线程安全的,在多线程并发的环境下,可能会产生死锁等问题。
HashMap不是线程安全的,但是它的效率会比Hashtable要好很多。
当需要多线程操作的时候可以使用线程安全的ConcurrentHashMap。ConcurrentHashMap虽然也是线程安全的,但是它的效率比Hashtable要高好多倍。因为ConcurrentHashMap使用了分段锁,并不对整个数据进行锁定。
HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
HashMap和HashTable都使用数组加链表的结构来存储键值对,在数据结构上是基本相同的。
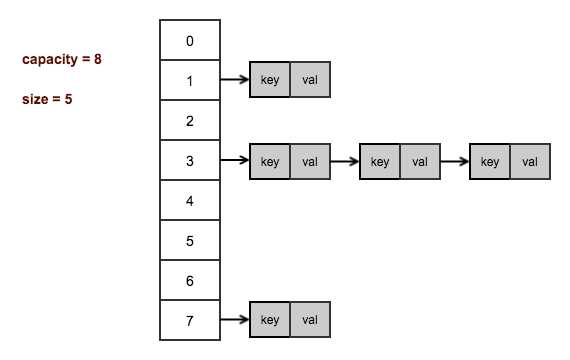
上图画出的是一个桶数量为8,存有5个键值对的HashMap/HashTable的内存布局情况。
二者初始容量大小和每次扩充容量大小的不同。
HashTable默认的初始大小为11,之后每次扩充为原来的2n+1。HashMap默认的初始化大小为16,之后每次扩充为原来的2倍。
如果在创建时给定了初始化大小,那么HashTable会直接使用你给定的大小,而HashMap会将其扩充为2的幂次方大小。(如设定大小为27,则HashTable就是27,而HashMap则为32)。
HashTable会尽量使用素数、奇数。而HashMap则总是使用2的幂作为哈希表的大小。当哈希表的大小为素数时,简单的取模哈希的结果会更加均匀,所以单从这一点上看,HashTable的哈希表大小选择,似乎更高明些。但另一方面在取模计算时,如果模数是2的幂,那么可以直接使用位运算来得到结果,效率要大大高于做除法。所以从hash计算的效率上,又是HashMap更胜一筹。
标签:数组 用处 继承 serial 效率 安全 素数 简单 方法
原文地址:https://www.cnblogs.com/deltadeblog/p/9355177.html