标签:style blog http io ar java for strong 文件
//加载数据1~10
val num=sc.parallelize(1 to 10)
//每个数据项乘以2,注意 _*2记为一个函数(fun)
val doublenum = num.map(_*2)
//内存缓存数据
doublenum.cache()
//过滤数据,每个数据项 % 3 为0的数据为结果集;
val threenum = doublenum.filter(_ % 3 == 0)
//释放缓存
threenum.unpersist()
//出发action操作根据前面的步骤构建DAG并执行,以数据的形式返回结果集;
threenum.collect
//返回结果集中的第一个元素
threenum.first
//返回结果集中的前三个元素
threenum.take(3)
//对数据集中的元素个数统计
threenum.count
//查看以上步骤经过的RDD转换过程
threenum.toDebugString
结果:
// 加载数据
val kv1=sc.parallelize(List(("A",1),("B",2),("C",3),("A",4),("B",5)))
//根据数据集中的每个元素的K值对数据排序
kv1.sortByKey().collect
kv1.groupByKey().collect //根据数据集中的每个元素的K值对数据分组
kv1.reduceByKey(_+_).collect
注意:sortByKey 、groupByKey 、reduceByKey之间的结果集的区别;
val kv2=sc.parallelize(List(("A",4),("A",4),("C",3),("A",4),("B",5)))
kv2.distinct.collect // distinct操作去重
kv1.union(kv2).collect //kv1与kv2联合
kv1.join(kv2).collect //kv1与kv2两个数据连接,相当于表的关联
val kv3=sc.parallelize(List(List(1,2),List(3,4)))
kv3.flatMap(x=>x.map(_+1)).collect //注意这里返回的数据集已经不是K-V类型了
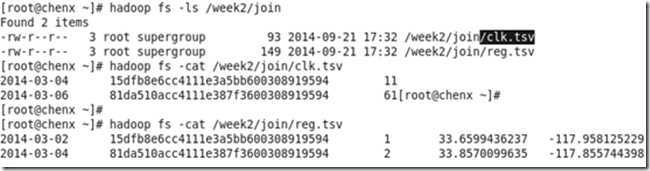
先将clk.tsv和reg.tsv文件上传到hdfs,文件格式如下;
// 定义一个对日期格式化的常量
val format = new java.text.SimpleDateFormat("yyyy-MM-dd")
// scala语法,定义Register类(根据reg.tsv数据格式)
case class Register (d: java.util.Date, uuid: String, cust_id: String, lat: Float,lng: Float)
// scala语法,定义Click类(根据clk.tsv数据格式)
case class Click (d: java.util.Date, uuid: String, landing_page: Int)
// 加载hdfs上的文件reg.tsv并将每行数据转换为Register对象;
val reg = sc.textFile("hdfs://chenx:9000/week2/join/reg.tsv").map(_.split("\t")).map(r => (r(1), Register(format.parse(r(0)), r(1), r(2), r(3).toFloat, r(4).toFloat)))
// 加载hdfs上的文件clk.tsv并将每行数据转换为Click对象;
val clk = sc.textFile("hdfs://chenx:9000/week2/join/clk.tsv").map(_.split("\t")).map(c => (c(1), Click(format.parse(c(0)), c(1), c(2).trim.toInt)))
reg.join(clk).collect
Spark系列(二) Spark Shell各种操作及详细说明
标签:style blog http io ar java for strong 文件
原文地址:http://www.cnblogs.com/jianyuan/p/4004486.html