标签:简单 大数 xshell ring 之间 封装 选择 not 节点
Mapreduce过程中理解
简单的来说map是大数据,reduce是计算<运行时如果数据量不大,但是却要分工做这就比较花时间了>
首先想要使用mapreduce,需要一些配置:
1.在notepad++里修改yarn-site.xml文件,新添加
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.64.141</value>
</property>
<property>
<name>yarn.nodemanager.aux-service</name>
<value>mapreduce_shuffle</value>
</property>
在notepad++里修改mapred-site.xml文件,新添加
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2.在xshell里将soft/soft/hadoop/etc/hadoop下的mapred-site.xml.template去掉后缀名

3.保证在start-dfs.sh
打开start--yarn.sh

输入Jps,显示namenod 和 datanod
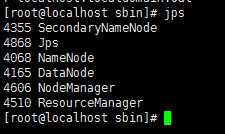
4.到hadoop目录下新建一个有数据的txt

5.确保文件存在之后,将其放在hadoop文件下

6.在我们的ip下查看,已经将hadoop.txt放进了hadoop下


7.到hadoop下的mapreduce文件下
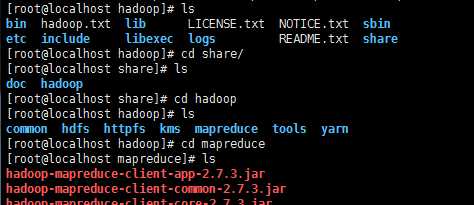
8.在hadoop下运行

可以看见数据在map和reduce之间传



9.也可以刷新eclipse里面的hadoop文件下的abc.txt查看结果
自己来写一个mapreduce吧!
在mapreduce中,map和reduce是有个字不同的所以要单独写成两个类。
1.需要在maven 项目 下的pom.xml导仨包 1.hadoop-common 2.hadoop-client 3.mapreduce-jobclient ------- 要求版本号要一致,可以选择封装起来
2建类
2.1 map里 注意输入输出都是键值对key-vaue
如一行文字-就是value,字节偏移量--就是key,整型类型;Abd ss m 就是Abd - 1 ss -2 m-3
-----注意:
输入value不是string,hadoop有自己的包装类,输入value是Text,
输入key不是int,因为大数据不知道有多大所以设置大一点---hadoop自己的包装类LongWritable
输出时,单词作为key,次数是value,即输出key是Test,输出value是IntWritabl
2.2 reduce里 上下文信息,处理
2.3 提交作业里
重写run方法,给job赋map,reduce,设置端口,输入、输出路径
注意输出文件目录必须是不存在的(原因是为了避免覆盖数据)
3.开启yarn(所有mapreduce项目都需要开启yarn,yarn下管理资源和节点),运行Myjob
Job就是mapreduce程序运行的主类。指定使用的是哪个mapper哪个reduce
指定mapper、reduce输入输出的key-value类型
以及输入、输出的数据位置
Job提交---一般是用waitforCompletion(true)可以看见运行过程(不用submit)

标签:简单 大数 xshell ring 之间 封装 选择 not 节点
原文地址:https://www.cnblogs.com/Amyheartxy/p/9360002.html