标签:无数据 副本 off 故障 tor cto 网络拓扑 ase ted
Cassandra如何存储数据的概述。
·Cassandra数据库分布在几个一起操作的机器上。最外层容器被称为集群。对于故障处理,每个节点包含一个副本,如果发生故障,副本将负责。Cassandra按照环形格式将节点排列在集群中,并为它们分配数据。
键空间是Cassandra中数据的最外层容器。Cassandra中的一个键空间的基本属性是 -
复制因子 - 它是集群中将接收相同数据副本的计算机数。
副本放置策略 - 它只是把副本放置策略。我们有简单策略(机架感知策略),旧网络拓扑策略(机架感知策略)和网络拓扑策略(数据中心共享策略)等策略。
列族(类似于关系型数据库中的表(Table)) - 键空间是一个或多个列族的列表的容器。列族又是一个行集合的容器。每行包含有序列。列族表示数据的结构。每个键空间至少有一个,通常是许多列族。
创建键空间的语法如下 -
CREATE KEYSPACE Keyspace name
WITH replication = {‘class‘: ‘SimpleStrategy‘, ‘replication_factor‘ : 3};
Cassandra列族示意如下:整个是一个列族,包含了两行,两行的列可以不一样。(类比关系型数据库,相当于整个表有两条记录Row key1和Row key2)
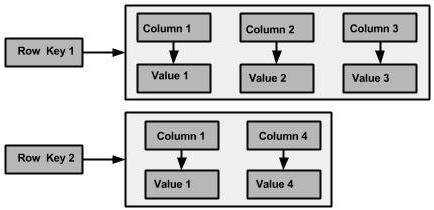
下面的示例可以让我们更好地理解Cassandra的数据存储:
Musician: ColumnFamily 1 (列族)
bootsy: RowKey
email: bootsy@pfunk.com, ColumnName:Value
instrument: bass ColumnName:Value
george: RowKey
email: george@pfunk.com ColumnName:Value
Band: ColumnFamily 2
george: RowKey
pfunk: 1968-2010 ColumnName:Value
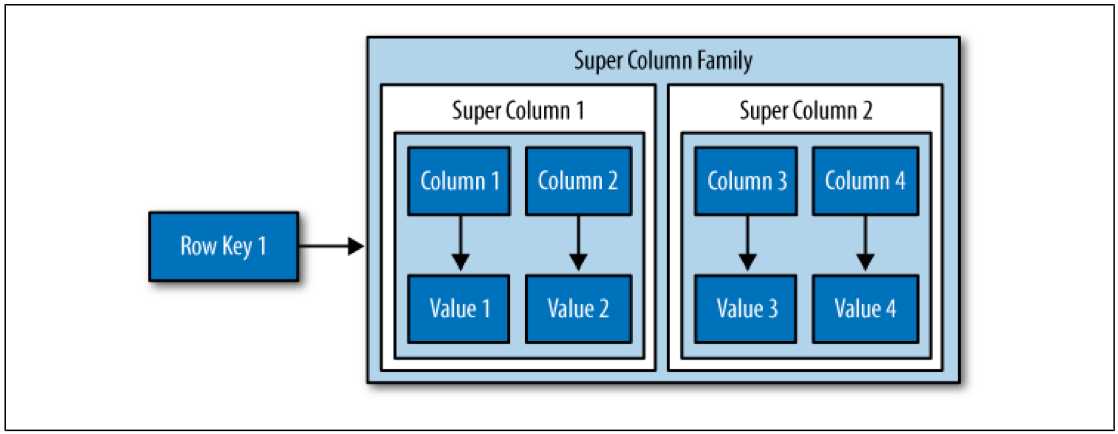
另外,Cassandra还有一种可在列之间建立关联的超级列(Super Column),你可以往超级列中添加子列。
如果用JSON表示,一组存放在列族中的数据看起来是这样的:
Hotel {
key: AZC_043 { name: Cambria Suites Hayden, phone: 480-444-4444,address: 400 N. Hayden Rd., city: Scottsdale, state: AZ, zip: 85255}
key: AZS_011 { name: Clarion Scottsdale Peak, phone: 480-333-3333,address: 3000 N. Scottsdale Rd, city: Scottsdale, state: AZ, zip: 85255}
key: CAS_021 { name: W Hotel, phone: 415-222-2222,address: 181 3rd Street, city: San Francisco, state: CA, zip: 94103}
key: NYN_042 { name: Waldorf Hotel, phone: 212-555-5555,address: 301 Park Ave, city: New York, state: NY, zip: 10019} }使用Cassandra创建键空间Hotelier,列族为Hotel,并查询行键(Row Key)为“NYN_042”的结果,
cassandra> get Hotelier.Hotel[‘NYN_042‘]
=> (column=zip, value=10019, timestamp=3894166157031651)
=> (column=state, value=NY, timestamp=3894166157031651)
=> (column=phone, value=212-555-5555, timestamp=3894166157031651)
=> (column=name, value=The Waldorf=Astoria, timestamp=3894166157031651)
=> (column=city, value=New York, timestamp=3894166157031651)
列(Column)
Cassandra的列是一组键值对(和关系型数据库中的列不一样)
使用JSON描述的列结构:
{
"name": "email",
"value: "me@example.com",
"timestamp": 1274654183103300
}超级列(Super Column)的结构:(键值对的嵌套)

最后让我们来巩固一下Cassandra和关系型数据库的区别吧:
没有查询语言:No SQL (Structured Query Language);
没有外键约束:关系型数据库的最重要特征;
双重簇索引:在关系型数据库中,每个表只能指定一个簇索引,其它的索引查询都会导致全表扫描,但在Cassandra中,我们可以有第二级的簇索引;
排序是在设计时决策:Cassandra不支持Order By,排序是需要设计时考虑,而不是像在关系型数据库查询时刻使用Order By;
无数据结构约定:这是Cassandra最大的优势,在关系型数据库中,我们设计数据库结构时总是慎之又慎,但在Cassandra中不需要预先约定数据结构。
标签:无数据 副本 off 故障 tor cto 网络拓扑 ase ted
原文地址:https://www.cnblogs.com/liufei1983/p/9363150.html