标签:ring 2.0 ted 方法 max selected abi mmu ati
seq2seq模型在2014年提出,这篇论文是将seq2seq模型应用在abstractive summarization任务上比较早期的论文。同组的人还发表了一篇NAACL2016(Sumit Chopra, Facebook AI Research_Abstractive sentence summarization with attentive recurrent neural networks)(作者都差不多),在这篇的基础上做了更多的改进,效果也更好。这两篇都是在abstractive summarization任务上使用seq2seq模型的经典baseline。


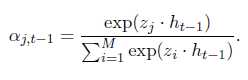
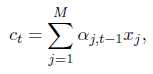
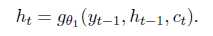
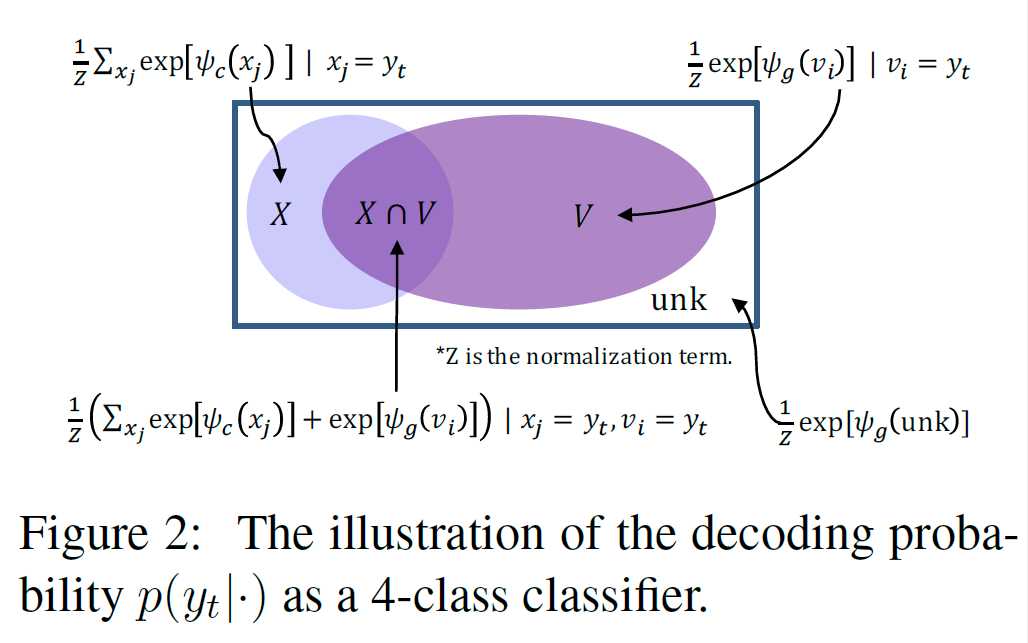
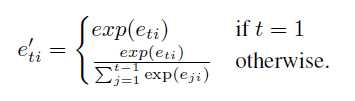

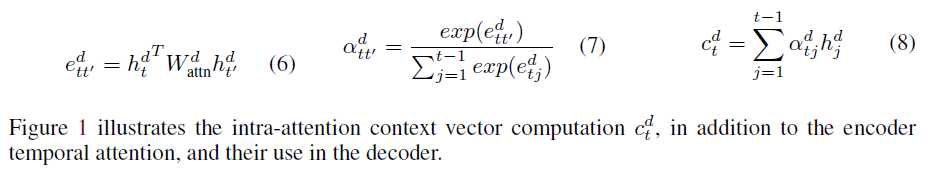
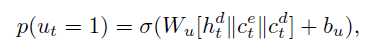
Weight Sharing: 输出的embedding matrix是由输入的embedding matrix之间加了一层非线性映射得到的。(参考Inan et al. (2017) and Press & Wolf (2016))
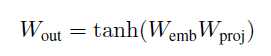
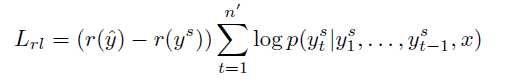
最终的混合目标函数如下:
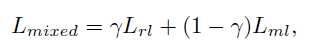
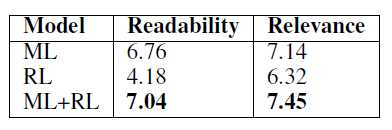
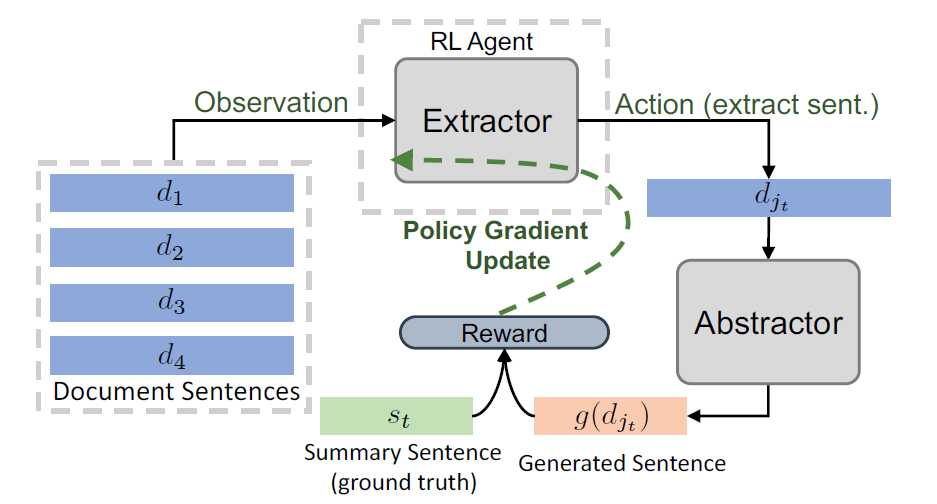
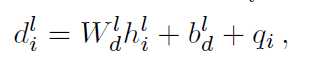
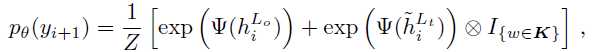
A Deep Reinforced Model for Abstractive Summarization一模一样,λ_RL=0.99A Deep Reinforced Model for Abstractive Summarization已经用过Intra-Decoder Attention尝试从已经输出过的内容上解决这个问题,这篇文章提出了Global Encoding方法使用源文本来尝试解决这个问题。标签:ring 2.0 ted 方法 max selected abi mmu ati
原文地址:https://www.cnblogs.com/dtblog/p/9365601.html