标签:算法 并且 转移 strlen tor == 最大 路径 pac
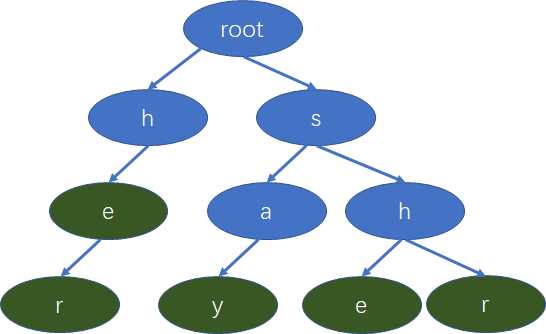
1.将所有模式串构建成 Trie 树
2.对 Trie 上所有节点构建前缀指针(类似kmp中的next数组)
字典树的构建过程是这样的,当要插入许多单词的时候,我们要从前往后遍历整个字符串,
当我们发现当前要插入的字符其节点再先前已经建成,我们直接去考虑下一个字符即可,
当我们发现当前要插入的字符没有再其前一个字符所形成的树下没有自己的节点,
我们就要创建一个新节点来表示这个字符,接下往下遍历其他的字符。然后重复上述操作。
假设我们有下面的单词,she , he ,say, her, shr ,我们要构建一棵字典树
在KMP算法中,当我们比较到一个字符发现失配的时候我们会通过next数组,
找到下一个开始匹配的位置,然后进行字符串匹配,当然KMP算法试用于单模式匹配,
所谓单模式匹配,就是给出一个模式串,给出一个文本串,然后看模式串在文本串中是否存在。
AC自动机中,有fail指针,当发现失配的字符失配的时候,跳转到fail指针指向的位置,
然后再次进行匹配操作,AC自动机之所以能实现多模式匹配,就归功于Fail指针的建立。
当前节点t有fail指针,其fail指针所指向的节点和t所代表的字符是相同的。
因为t匹配成功后,我们需要去匹配 t->child,发现失配,那么就从t->fail开始再次匹配。
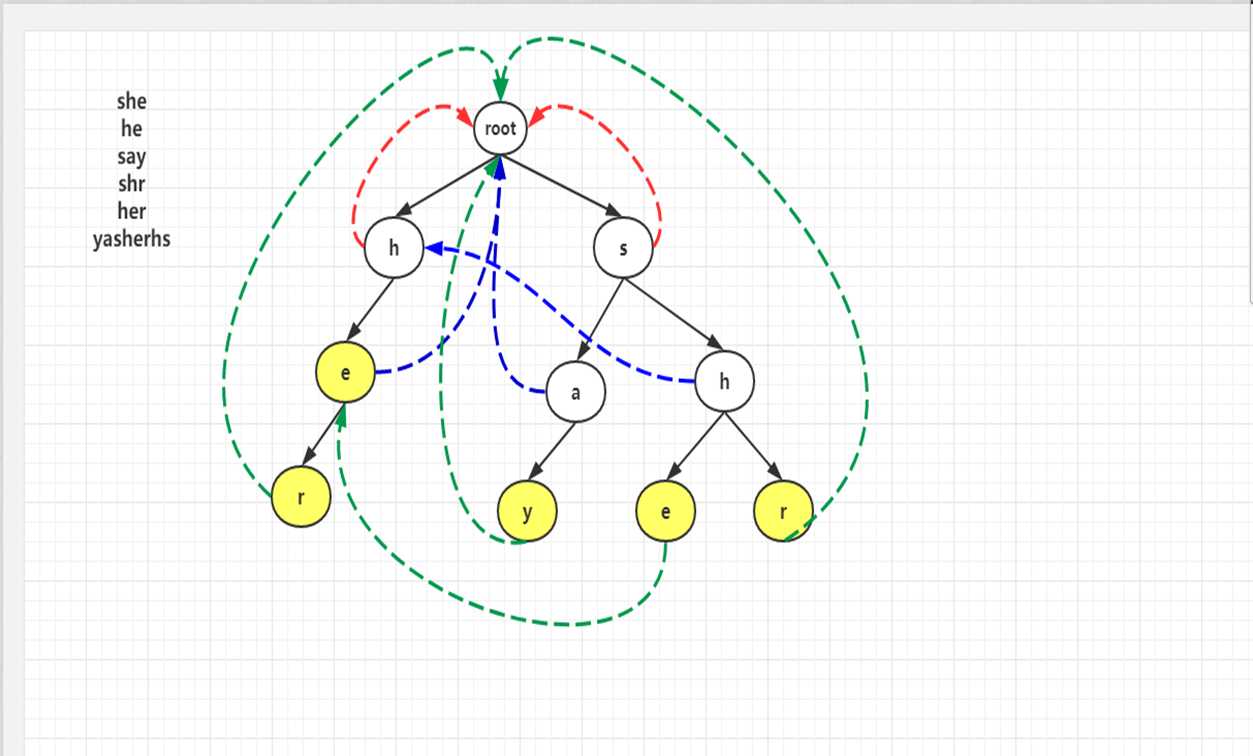
Fail指针的求法:
Fail指针用BFS来求得,对于直接与根节点相连的节点来说,
如果这些节点失配,他们的Fail指针直接指向root即可,其他节点其Fail指针求法如下:
假设当前节点为father,其孩子节点记为child。
求child的Fail指针时,首先我们要找到其father的Fail指针所指向的节点,
假如是t的话,我们就要看t的孩子中有没有和child节点所表示的字母相同的节点,
如果有的话,这个节点就是child的fail指针,
如果发现没有,则需要找father->fail->fail这个节点,然后重复上面过程,
如果一直找都找不到,则child的Fail指针就要指向root。
匹配过程分两种情况:
(1)当前字符匹配,表示从当前节点沿着树边有一条路径可以到达目标字符,
如果当前匹配的字符是一个单词的结尾,我们可以沿着当前字符的fail指针,一直遍历到根,
如果这些节点末尾有标记(标记代表节点是一个单词末尾),遍历到的都是可以匹配上的节点。
统计完毕后标记。此时沿该路径走向下一个节点继续匹配,目标指针移向下个字符。
(2)当前字符不匹配,则去当前节点失败指针所指向的字符继续匹配,
匹配过程随着指针指向root结束。重复这2个过程中的任意一个,直到模式串走到结尾为止。
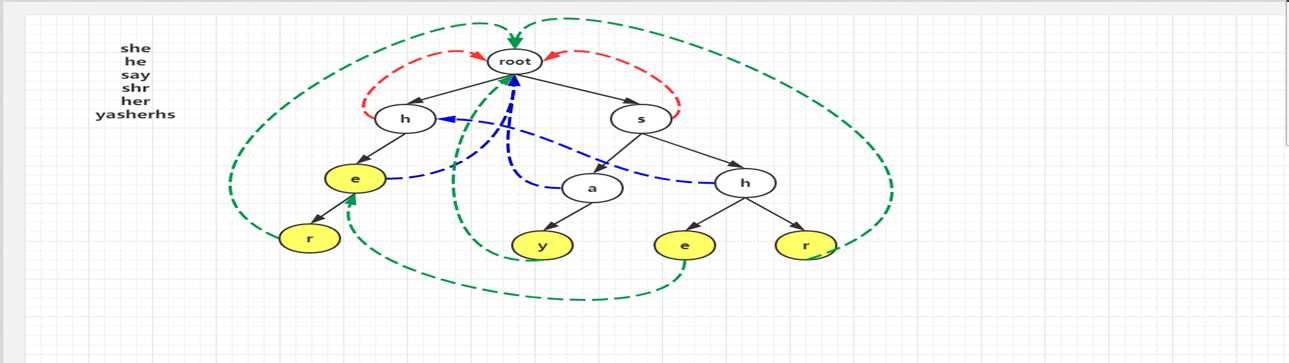
对照上图,看一下模式匹配这个详细的流程,其中模式串为 yasherhs(某文章)。
对于i=0,1,Trie 中没有对应的路径,故不做任何操作;
i=2,3,4时,指针p走到左下节点e。因为节点e的 count 信息为1,所以cnt+1,
(到达某一个单词的末尾,该信息用bool tail [ ] 记录,单词数++)。
并且将节点e的 count 值设置为-1,表示改单词已经出现过了,防止重复计数,
最后 temp 指向e节点的失败指针所指向的节点继续查找,
以此类推,最后 temp 指向 root,退出 while 循环,这个过程中 count 增加了2。
表示找到了2个单词she和he。当i=5时,程序进入第5行,p指向其失败指针的节点,
也就是右边那个e节点,随后在第6行指向r节点,r节点的 count 值为1,
从而count+1,循环直到 temp 指向 root 为止。最后i=6,7时,找不到任何匹配,结束。
struct node{ node *next[26]; node *fail; int sum; };
void Insert(char *s){ node *p = root; for(int i = 0; s[i]; i++){ int x = s[i] - ‘a‘; if(p->next[x] == NULL){ newnode=(struct node *)malloc(sizeof(struct node)); for(int j=0;j<26;j++) newnode->next[j] = 0; newnode->sum = 0;newnode->fail = 0; p->next[x]=newnode; } p = p->next[x]; } p->sum++; }
非指针方式实现建树:
//trie字典树: int tot=1,trie[maxn][26]; bool tail[maxn]; //串尾元素标记 void make_trie(char* s){ //insert int len=strlen(s),p=1; //p从根节点开始 for(int i=0;i<len;i++){ int c=s[i]-‘A‘; //按照具体情况转为数字 if(!trie[p][c]) trie[p][c]=++tot; //tot用于节点编号 p=trie[p][c]; } tail[p]=true; //标记串尾元素 }
fail指针的实现:(用nextt数组代替)
//fail指针:(此处可以构建nextt数组代替) int nextt[maxn],que[maxn]; void bfs(){ for(int i=0;i<26;i++) trie[0][i]=1; //↑↑↑初始化:0的所有转移边都设为根节点为1 que[1]=1; nextt[1]=0; //que为广搜队列 for(int q1=1,q2=1;q1<=q2;q1++){ //q1,q2相当于head,tail int p=que[q1]; //上方的层序数 for(int i=0;i<26;i++){ //一层遍历所有字母 if(!trie[p][i]) trie[p][i]=trie[nextt[p]][i]; //↑↑↑若不存在trie[p][i],则沿p的前缀指针走到第一个满足存在的字符i转移边 //则会得到结点v=nextt[p],对应值就是trie[nextt[p]][i] else{ que[++q2]=trie[p][i]; //trie[p][i]存在,存入队尾 xtt[p]; nextt[trie[p][i]]=trie[v][i]; } } } }
文本串的匹配:
//匹配是否存在: int find1(){ int p=1; for(int i=1;i<=m;i++){ p=trie[p][a[i]]; //向下层寻找匹配字符 if(tail[p]) return 0; //匹配到返回0,否则返回1 } return 1; }
//文章匹配单词数: void find2(char *s){ int p=1,len=strlen(s),c,k; for(int i=0;i<len;i++){ c=s[i]-‘a‘; k=trie[p][c];//p为层数(节点编号) while(k>1){ //可以匹配的到 && 不是根节点 ans+=tail[k]; //如果到达一处单词结尾,ans+=1 tail[k]=0; //防止重复计数 k=nextt[k]; //返回上层的该元素出现位置,重新找 } p=trie[p][c]; //向下层寻找匹配字符编号 } return; }
(1)【关键字搜索】hdu 2222

#include <cmath> #include <iostream> #include <cstdio> #include <string> #include <cstring> #include <vector> #include <algorithm> #include <stack> #include <queue> using namespace std; typedef long long ll; typedef unsigned long long ull; /*【关键字搜索】hdu 2222 寻找有多少个单词在文章中出现。 */ // AC自动机模板题 const int maxn=5e5+5; //trie字典树: int ans,tot=1,trie[maxn][30]; int tail[maxn]; //串尾元素标记:0为未出现,1为已出现 void make_trie(char* s){ //insert int len=strlen(s),p=1; //p从根节点开始 for(int i=0;i<len;i++){ int c=s[i]-‘a‘; //按照具体情况转为数字 if(!trie[p][c]){ trie[p][c]=++tot; //tot用于节点编号 // memset(trie[tot],0,sizeof(trie[tot])); //写不写无所谓 } p=trie[p][c]; } tail[p]++; //标记串尾元素 return; } //fail指针:(此处可以构建nextt数组代替) int nextt[maxn],que[maxn]; void bfs(){ for(int i=0;i<26;i++) trie[0][i]=1; //↑↑↑初始化:0的所有转移边都设为根节点为1 que[1]=1; nextt[1]=0; //que为广搜队列 for(int q1=1,q2=1;q1<=q2;q1++){ //q1,q2相当于head,tail int p=que[q1]; //上方的层序数 for(int i=0;i<26;i++){ //一层遍历所有字母 if(!trie[p][i]) trie[p][i]=trie[nextt[p]][i]; //↑↑↑若不存在trie[p][i],则沿p的前缀指针走到第一个满足存在的字符i转移边 //则会得到结点v=nextt[p],对应值就是trie[nextt[p]][i] else{ que[++q2]=trie[p][i]; //trie[p][i]存在,存入队尾 int v=nextt[p]; nextt[trie[p][i]]=trie[v][i]; } } } } //文章匹配单词数: void find2(char *s){ int p=1,len=strlen(s),c,k; for(int i=0;i<len;i++){ c=s[i]-‘a‘; k=trie[p][c];//p为层数(节点编号) while(k>1){ //可以匹配的到 && 不是根节点 ans+=tail[k]; //如果到达一处单词结尾,ans+=此处结尾的单词数 tail[k]=0; //防止重复计数 k=nextt[k]; //返回上层的该元素出现位置,重新找 } p=trie[p][c]; //向下层寻找匹配字符编号 } return; } int main(){ int t,n; scanf("%d",&t); char s[maxn<<1]; //两倍maxn while(t--){ ans=0; tot=1; memset(tail,0,sizeof(tail)); for(int i=0;i<26;i++) //初始化根节点和第一层的结点 trie[0][i]=1,trie[1][i]=0; scanf("%d",&n); for(int i=1;i<=n;i++){ scanf("%s",s); make_trie(s); } bfs(); //建立nextt数组 scanf("%s",s); //文章 find2(s); printf("%d\n",ans); } return 0; }
(2)【单词】 bzoj 3172
#include <cmath> #include <iostream> #include <cstdio> #include <string> #include <cstring> #include <vector> #include <algorithm> #include <stack> #include <queue> using namespace std; typedef long long ll; typedef unsigned long long ull; /*【单词】 bzoj 3172 一个论文,求每个单词分别在论文中出现多少次。 */ const int maxn=1000010; struct node{ int fail,ch[26],sum; }p[maxn]; int n,m,tot; int Q[maxn],ans[maxn],pos[maxn]; char ss[maxn]; queue<int> q; int main(){ scanf("%d",&n); int k,u,t; tot=1; for(int i=1;i<=n;i++){ scanf("%s",ss); u=1; k=strlen(ss); for(int j=0;j<k;j++){ //trie树 if(!p[u].ch[ss[j]-‘a‘]) p[u].ch[ss[j]-‘a‘]=++tot; u=p[u].ch[ss[j]-‘a‘]; p[u].sum++; } pos[i]=u; //每个单词末尾到达的位置 } q.push(1); //宽搜求fail while(!q.empty()){ u=q.front(),q.pop(); Q[++Q[0]]=u; for(i=0;i<26;i++){ if(!p[u].ch[i]) continue; //此处没有 q.push(p[u].ch[i]); if(u==1){ p[p[u].ch[i]].fail=1; continue; } t=p[u].fail; while(!p[t].ch[i]&&t) t=p[t].fail; if(t) p[p[u].ch[i]].fail=p[t].ch[i]; else p[p[u].ch[i]].fail=1; } } for(int i=tot;i>=2;i--) p[p[Q[i]].fail].sum+=p[Q[i]].sum; for(int i=1;i<=n;i++) printf("%d\n",p[pos[i]].sum); return 0; }
(3)【玄武密码】bzoj4327 (目测没有问题,但运行错误orz)
#include <cmath> #include <iostream> #include <cstdio> #include <string> #include <cstring> #include <vector> #include <algorithm> #include <stack> #include <queue> using namespace std; typedef long long ll; typedef unsigned long long ull; /*【玄武密码】bzoj4327 对于每一段文字,求其前缀在母串上的最大匹配长度。 */ const int maxn=10000010; int tot=1,m,n; char s[maxn],ch[109]; int trie[maxn][4],l[maxn],fa[maxn]; int pos[maxn],point[maxn]; int nextt[maxn],que[maxn]; int cal(char x){ if (x==‘E‘) return 0; if (x==‘S‘) return 1; if (x==‘W‘) return 2; if (x==‘N‘) return 3; } //trie字典树: void make_trie(int x){ //insert l[x]=strlen(ch); int p=1; for(int i=0;i<l[x];i++){ int u=cal(ch[i]); //结点对应值 if(!trie[p][u]){ trie[p][u]=++tot; fa[trie[p][u]]=p; } p=trie[p][u]; } point[x]=p; //记录这一组的末尾位置 } //fail指针:(此处可以构建nextt数组代替) void bfs(){ for(int i=0;i<26;i++) trie[0][i]=1; //↑↑↑初始化:0的所有转移边都设为根节点为1 que[1]=1; nextt[1]=0; //que为广搜队列 for(int q1=1,q2=1;q1<=q2;q1++){ //q1,q2相当于head,tail int p=que[q1]; //上方的层序数 for(int i=0;i<26;i++){ //一层遍历所有字母 if(!trie[p][i]) trie[p][i]=trie[nextt[p]][i]; //↑↑↑若不存在trie[p][i],则沿p的前缀指针走到第一个满足存在的字符i转移边 //则会得到结点v=nextt[p],对应值就是trie[nextt[p]][i] else{ que[++q2]=trie[p][i]; //trie[p][i]存在,存入队尾 int v=nextt[p]; nextt[trie[p][i]]=trie[v][i]; } } } } void pre(){ int p=1; for(int i=0;i<n;i++){ int u=cal(s[i]); p=trie[p][u]; for(int j=p;j;j=nextt[j]){ if(pos[j]) break; //已经操作过 else pos[j]=1; } } } int getans(int x){ int ans=l[x]; //最大化 for(int i=point[x];i;i=fa[i]){ if(pos[i]) return ans; ans--; //↑↑↑找出到达的最深层位置 } return 0; } int main(){ scanf("%d%d",&n,&m); scanf("%s",s); //文章 for(int i=1;i<=m;i++){ scanf("%s",ch); make_trie(i); } for(int i=0;i<4;i++) trie[0][i]=1; bfs(); pre(); for(int i=1;i<=m;i++) printf("%d\n",getans(i)); return 0; }
(4) bzoj 3940 / 1195 / 2938 / 1030
——时间划过风的轨迹,那个少年,还在等你。
标签:算法 并且 转移 strlen tor == 最大 路径 pac
原文地址:https://www.cnblogs.com/FloraLOVERyuuji/p/9366176.html
