标签:nbsp 创建 ssh tst x86_64 href active pacemaker mem
参考文档:
# 在全部控制与计算节点设置epel与ceph yum源(base yum源已更新),以controller01节点为例;
# epel:http://mirrors.aliyun.com/repo/
[root@controller01 ~]# wget -O /etc/yum.repos.d/epel-7.repo http://mirrors.aliyun.com/repo/epel-7.repo
# ceph:http://mirrors.aliyun.com/ceph/
# 编辑ceph.repo文件,使用luminous版本
[root@controller01 ~]# vim /etc/yum.repos.d/ceph.repo
[ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/x86_64/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=http://mirrors.aliyun.com/ceph/keys/release.asc
[ceph-noarch]
name=cephnoarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/noarch/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=http://mirrors.aliyun.com/ceph/keys/release.asc
[ceph-source]
name=ceph-source
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/SRPMS/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=http://mirrors.aliyun.com/ceph/keys/release.asc
# 重新加载yum源
[root@controller01 ~]# yum clean all
[root@controller01 ~]# yum makecache
# 查看yum源
[root@controller01 ~]# yum repolist
基础环境,如hosts,时间同步ntp,开放端口iptables等相关操作,请见:https://www.cnblogs.com/netonline/p/9180299.html
# 创建ceph-deploy用户,官方文档不建议在生产环境中使用root用户进行部署;
# 新用户名不能是"ceph",其已保留给ceph服务守护进程使用;
# 新用户需具备无密码使用sudo的权限,因ceph在安装过程中不支持输入密码;
# 新用户需要在全部控制与存储(这里即计算)节点创建,以controller01节点为例
[root@controller01 ~]# useradd -d /home/ceph -m cephde
[root@controller01 ~]# passwd cephde
New password: storage_pass
Retype new password: storage_pass
# 修改visudo文件,使cephde用户在sudo列表中;
# 在92行" root ALL=(ALL) ALL"下新增一行:" cephde ALL=(ALL) ALL"
[root@controller01 ~]# visudo
93 cephde ALL=(ALL) ALL
# 设置cephde用户具备无密码sudo(root)权限;
# 切换到cephde用户下操作
[root@controller01 ~]# su - cephde
[cephde@controller01 ~]$ echo "cephde ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephde
[sudo] password for cephde:storage_pass
[cephde@controller01 ~]$ sudo chmod 0440 /etc/sudoers.d/cephde
# ceph-deploy不支持密码输入,需要在管理控制节点生产ssh秘钥,并将公钥分发到各ceph节点;
# 在用户cephde下生成秘钥,不能使用sudo或root用户;
# 默认在用户目录下生成~/.ssh目录,含生成的秘钥对;
# "Enter passphrase"时,回车,口令为空;
# 另外3个控制节点均设置为ceph管理节点,应该使3各控制管理节点都可以ssh免密登陆到其他所有控制与存储节点
[root@controller01 ~]# su - cephde
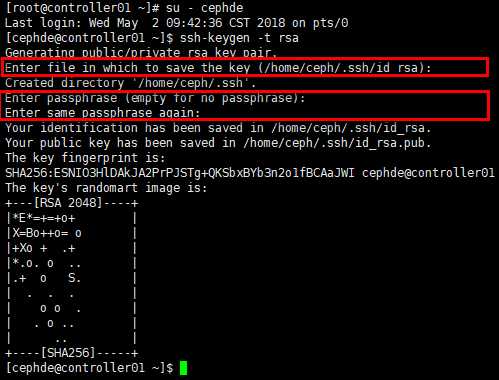
[cephde@controller01 ~]$ ssh-keygen -t rsa
Enter file in which to save the key (/home/ceph/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
# 前提是各控制与存储节点已生成相关用户;
# 初次连接其他节点时需要确认;
# 首次分发公钥需要密码;
# 分发成功后,在~/.ssh/下生成known_hosts文件,记录相关登陆信息;
# 以controller01节点免密登陆controller02节点为例;另外3个控制节点均设置为ceph管理节点,应该使3各控制管理节点都可以ssh免密登陆到其他所有控制与存储节点
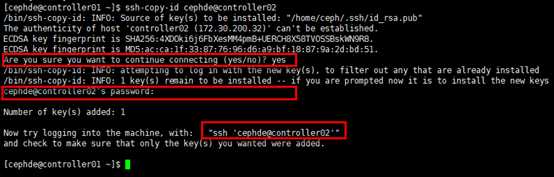
[cephde@controller01 ~]$ ssh-copy-id cephde@controller02
Are you sure you want to continue connecting (yes/no)? yes
cephde@controller02‘s password:
# 在root账号主目录下,生成~/.ssh/config文件,这样在控制管理节点上执行"ceph-deploy"时可不切换用户或指定"--username {username}";
[root@controller01 ~]# cat ~/.ssh/config
# ceph-deploy
Host controller02
Hostname controller02
User cephde
Host controller03
Hostname controller03
User cephde
Host compute01
Hostname compute01
User cephde
Host compute02
Hostname compute02
User cephde
Host compute03
Hostname compute03
User cephde
# 在规划的全部控制管理节点安装ceph-deploy工具,以controller01节点为例
[root@controller01 ~]# yum install ceph-deploy -y
# 在cephde账户下操作,切忌使用sudo操作;
# 在管理节点上生成一个目录用于存放集群相关配置文件;
[root@controller01 ~]# su - cephde
[cephde@controller01 ~]$ mkdir cephcluster
# 后续ceph-deploy相关操作全部在所创建的目录执行;
# 将规划中的MON(monitor)节点纳入集群,即创建集群
[cephde@controller01 ~]$ cd ~/cephcluster/
[cephde@controller01 cephcluster]$ ceph-deploy new controller01 controller02 controller03
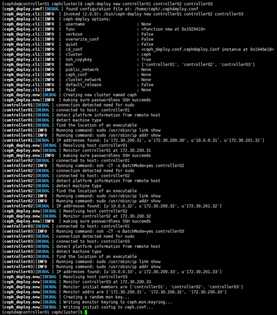
# 生成集群后在集群目录下生成3个文件,其中ceph.conf即是配置文件;
# 默认可不修改,为使服务按规划启动,可做适当修改;
# 以下红色粗体部分是在默认生成的conf文件上新增的配置
[cephde@controller01 cephcluster]$ cat ceph.conf
[global]
fsid = 9b606fef-1cde-4d4c-b269-90079d1d45dd
mon_initial_members = controller01, controller02, controller03
mon_host = 172.30.200.31,172.30.200.32,172.30.200.33
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
# public network:前端mon网络,client访问网络;确保public network与mon_host在相同网段,否则初始化时可能会有错误;
# cluster network:后端osd心跳,数据/流复制恢复等网络
public network = 172.30.200.0/24
cluster network = 10.0.0.0/24
# 默认的副本数为3,实验环境变更为2
osd pool default size = 2
# 默认保护机制不允许删除pool,根据情况设置
mon_allow_pool_delete = true
# 在全部控制管理与存储节点安装ceph;
# 理论上在控制节点的ceph集群目录使用ceph-deploy可统一安装,命令:ceph-deploy install controller01 controller02 controller03 compute01 compute02 compute03;
# 但由于网速原因大概率会失败,可在各存储节点独立安装ceph与ceph-radosgw,以controller01节点为例
[root@controller01 ~]# yum install -y ceph ceph-radosgw
# 查看版本
[root@controller01 ~]# ceph -v

# 在控制管理节点初始化monitor
[cephde@controller01 cephcluster]$ ceph-deploy mon create-initial
# 初始化完成后,在集群目录下新增多个秘钥文件
[cephde@controller01 cephcluster]$ ls -l
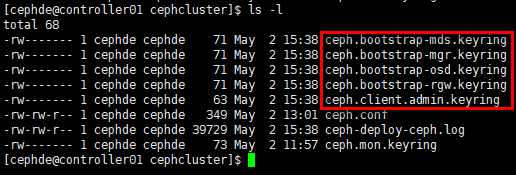
# 查看状态
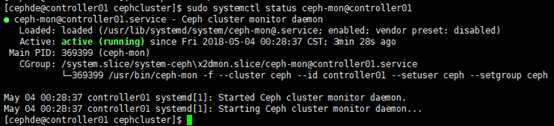
[cephde@controller01 cephcluster]$ sudo systemctl status ceph-mon@controller01
# 分发ceph配置文件与秘钥到其他控制管理节点与存储节点;
# 注意分发节点本身也需要包含在内,默认没有秘钥文件,需要分发;
# 如果被分发节点已经配置文件(统一变更配置文件场景),可以使用如下命令:
ceph-deploy --overwrite-conf admin xxx
# 分发的配置文件与秘钥在各节点/etc/ceph/目录
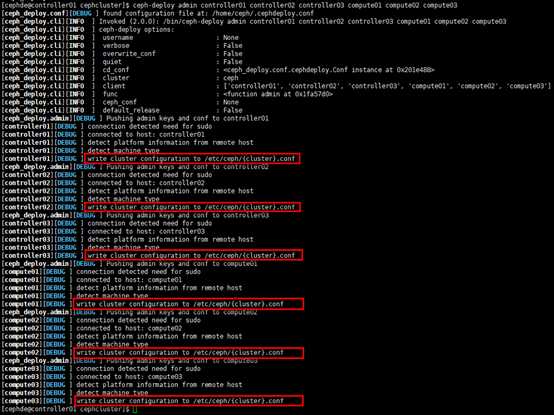
[cephde@controller01 cephcluster]$ ceph-deploy admin controller01 controller02 controller03 compute01 compute02 compute03
# luminous版本必须安装mgr(dashboard)
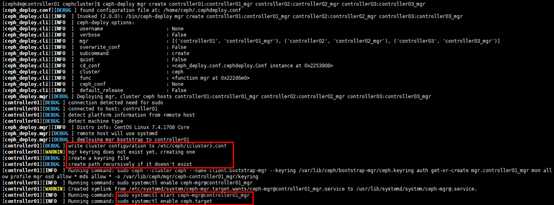
[cephde@controller01 cephcluster]$ ceph-deploy mgr create controller01:controller01_mgr controller02:controller02_mgr controller03:controller03_mgr
# 查看状态;
[cephde@controller01 cephcluster]$ systemctl status ceph-mgr@controller01_mgr

[cephde@controller01 cephcluster]$ sudo netstat -tunlp | grep mgr

# 可查看mgr默认开启的服务:(sudo) ceph mgr module ls;
# 默认dashboard服务在可开启列表中,但并未启动,需要手工开启
[cephde@controller01 cephcluster]$ sudo ceph mgr module enable dashboard
# dashboard服务已开启,默认监听全部地址的tcp7000端口;
# 如果需要设置dashboard的监听地址与端口,如下:
# 设置监听地址:(sudo) ceph config-key put mgr/dashboard/server_addr x.x.x.x
# 设置监听端口:(sudo) ceph config-key put mgr/dashboard/server_port x
[cephde@controller01 cephcluster]$ sudo netstat -tunlp | grep mgr

web登陆:http://172.30.200.31:7000/
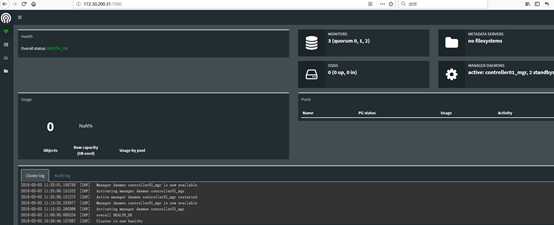
# 查看monitor状态
[cephde@controller01 cephcluster]$ sudo ceph mon stat

# 查看ceph状态:ceph health (detail),ceph -s,ceph -w等;
# 状态显示mgr处于active-standby模式
[cephde@controller01 cephcluster]$ sudo ceph -s
de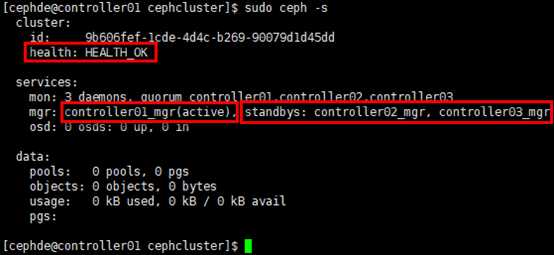
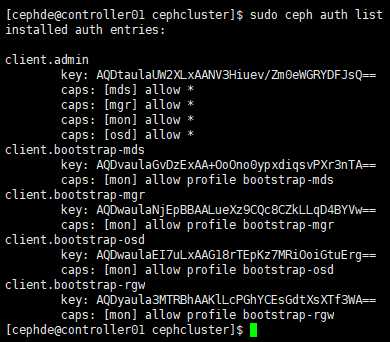
# 可在各节点查看认证信息等
[cephde@controller01 cephcluster]$ sudo ceph auth list
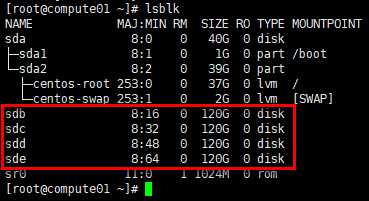
# osd位于存储节点,可查看存储节点磁盘状况,以compute01节点为例
[root@compute01 ~]# lsblk
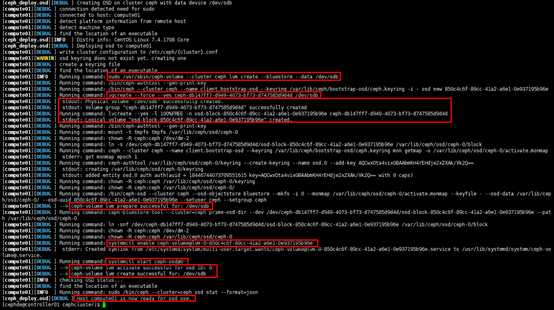
# 实际创建osd时,可通过管理节点使用ceph-deploy创建;
# 本例中有3个osd节点,每个osd节点可运行4个osd进程(在6800~7300端口范围内,每进程监听1个本地端口)
[cephde@controller01 cephcluster]$ ceph-deploy osd create compute01 --data /dev/sdb
[cephde@controller01 cephcluster]$ ceph-deploy osd create compute01 --data /dev/sdc
[cephde@controller01 cephcluster]$ ceph-deploy osd create compute01 --data /dev/sdd
[cephde@controller01 cephcluster]$ ceph-deploy osd create compute01 --data /dev/sde
[cephde@controller01 cephcluster]$ ceph-deploy osd create compute02 --data /dev/sdb
[cephde@controller01 cephcluster]$ ceph-deploy osd create compute02 --data /dev/sdc
[cephde@controller01 cephcluster]$ ceph-deploy osd create compute02 --data /dev/sdd
[cephde@controller01 cephcluster]$ ceph-deploy osd create compute02 --data /dev/sde
[cephde@controller01 cephcluster]$ ceph-deploy osd create compute03 --data /dev/sdb
[cephde@controller01 cephcluster]$ ceph-deploy osd create compute03 --data /dev/sdc
[cephde@controller01 cephcluster]$ ceph-deploy osd create compute03 --data /dev/sdd
[cephde@controller01 cephcluster]$ ceph-deploy osd create compute03 --data /dev/sde
# 在管理节点查看
[cephde@controller01 cephcluster]$ ceph-deploy osd list compute01
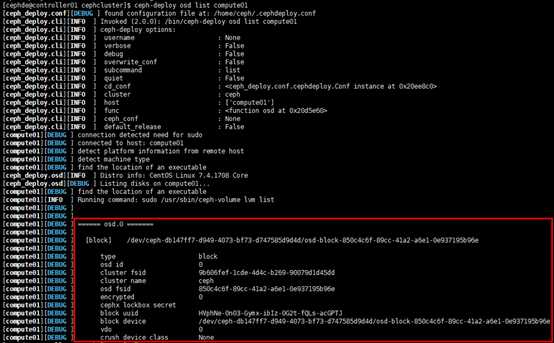
# 在管理节点查看osd状态等
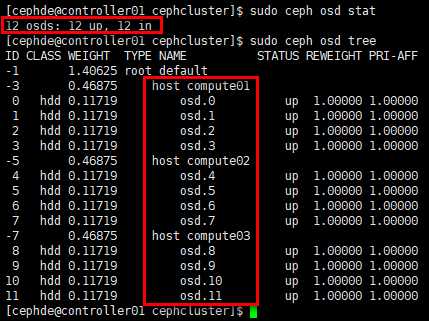
[cephde@controller01 cephcluster]$ sudo ceph osd stat
[cephde@controller01 cephcluster]$ sudo ceph osd tree
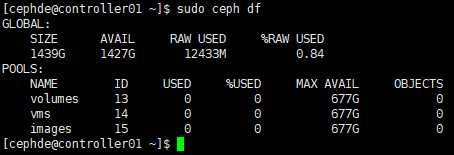
# 在管理节点查看容量及使用情况
[cephde@controller01 cephcluster]$ sudo ceph df
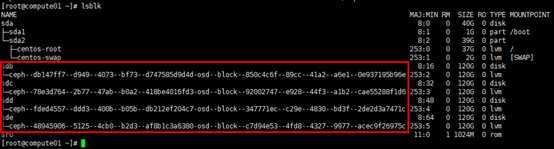
# 在osd节点查看
[root@compute01 ~]# lsblk
# ceph-osd进程,根据启动顺序,每个osd进程有特定的序号
[root@compute01 ~]# systemctl status ceph-osd@0
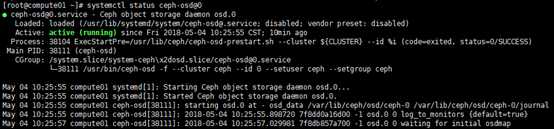
# osd进程端口号;
# 或:ps aux | grep osd | grep -v grep
[root@compute01 ~]# netstat -tunlp | grep osd
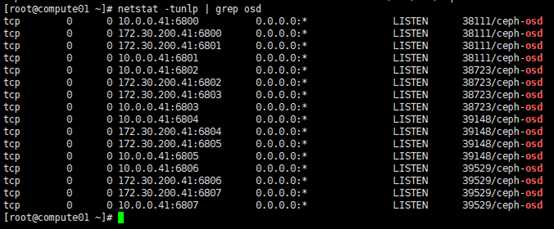
或登陆mgr_dashboard:http://172.30.200.31:7000
高可用OpenStack(Queen版)集群-13.分布式存储Ceph
标签:nbsp 创建 ssh tst x86_64 href active pacemaker mem
原文地址:https://www.cnblogs.com/netonline/p/9367802.html