标签:.data download module may 点击 names color www 表示
一、elastic search的安装与配置
1、安装Java 并且配置JAVA_HOME环境变量。
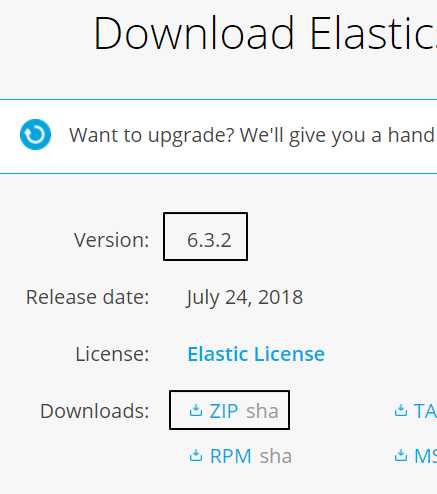
2、下载elasticsearch,下载地址:https://www.elastic.co/downloads/elasticsearch。博主下载时最新版为6.3.2,下面所有都是基于6.3.2进行的测试。选择下载zip文件,这样解压即可使用。
3.解压后修改配置文件。进入到elasticsearch所在目录下面的config下面,修改elasticsearch.yml文件,修改内容如下:
(1)、在文件结尾加入如下代码(key和值之间必须要有 空格)
http.cors.enabled: true http.cors.allow-origin: "*" node.master: true
(2)、在文件中找到network.host,将其值改为 127.0.0.1或者本机ip。
(3)、取消 http.port 、cluster.name 、node.name 三个值前面的注释(去掉 #)。
# ======================== Elasticsearch Configuration ========================= # # NOTE: Elasticsearch comes with reasonable defaults for most settings. # Before you set out to tweak and tune the configuration, make sure you # understand what are you trying to accomplish and the consequences. # # The primary way of configuring a node is via this file. This template lists # the most important settings you may want to configure for a production cluster. # # Please consult the documentation for further information on configuration options: # https://www.elastic.co/guide/en/elasticsearch/reference/index.html # # ---------------------------------- Cluster ----------------------------------- # # Use a descriptive name for your cluster: # cluster.name: my-application # # ------------------------------------ Node ------------------------------------ # # Use a descriptive name for the node: # node.name: node-1 # # Add custom attributes to the node: # #node.attr.rack: r1 # # ----------------------------------- Paths ------------------------------------ # # Path to directory where to store the data (separate multiple locations by comma): # #path.data: /path/to/data # # Path to log files: # #path.logs: /path/to/logs # # ----------------------------------- Memory ----------------------------------- # # Lock the memory on startup: # #bootstrap.memory_lock: true # # Make sure that the heap size is set to about half the memory available # on the system and that the owner of the process is allowed to use this # limit. # # Elasticsearch performs poorly when the system is swapping the memory. # # ---------------------------------- Network ----------------------------------- # # Set the bind address to a specific IP (IPv4 or IPv6): # network.host: 127.0.0.1 # # Set a custom port for HTTP: # http.port: 9200 # # For more information, consult the network module documentation. # # --------------------------------- Discovery ---------------------------------- # # Pass an initial list of hosts to perform discovery when new node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] # #discovery.zen.ping.unicast.hosts: ["host1", "host2"] # # Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1): # #discovery.zen.minimum_master_nodes: # # For more information, consult the zen discovery module documentation. # # ---------------------------------- Gateway ----------------------------------- # # Block initial recovery after a full cluster restart until N nodes are started: # #gateway.recover_after_nodes: 3 # # For more information, consult the gateway module documentation. # # ---------------------------------- Various ----------------------------------- # # Require explicit names when deleting indices: # #action.destructive_requires_name: true http.cors.enabled: true http.cors.allow-origin: "*" node.master: true
4、将elasticsearch复制一份,修改elasticsearch.yml文件内容。
# ======================== Elasticsearch Configuration ========================= # # NOTE: Elasticsearch comes with reasonable defaults for most settings. # Before you set out to tweak and tune the configuration, make sure you # understand what are you trying to accomplish and the consequences. # # The primary way of configuring a node is via this file. This template lists # the most important settings you may want to configure for a production cluster. # # Please consult the documentation for further information on configuration options: # https://www.elastic.co/guide/en/elasticsearch/reference/index.html # # ---------------------------------- Cluster ----------------------------------- # # Use a descriptive name for your cluster: # cluster.name: my-application # # ------------------------------------ Node ------------------------------------ # # Use a descriptive name for the node: # node.name: node-2 # # Add custom attributes to the node: # node.attr.rack: r1 # # ----------------------------------- Paths ------------------------------------ # # Path to directory where to store the data (separate multiple locations by comma): # path.data: /path/to/data # # Path to log files: # path.logs: /path/to/logs # # ----------------------------------- Memory ----------------------------------- # # Lock the memory on startup: # #bootstrap.memory_lock: true # # Make sure that the heap size is set to about half the memory available # on the system and that the owner of the process is allowed to use this # limit. # # Elasticsearch performs poorly when the system is swapping the memory. # # ---------------------------------- Network ----------------------------------- # # Set the bind address to a specific IP (IPv4 or IPv6): # network.host: 0.0.0.0 # # Set a custom port for HTTP: # http.port: 8200 # # For more information, consult the network module documentation. # # --------------------------------- Discovery ---------------------------------- # # Pass an initial list of hosts to perform discovery when new node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] # discovery.zen.ping.unicast.hosts: ["127.0.0.1"] # # Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1): # #discovery.zen.minimum_master_nodes: # # For more information, consult the zen discovery module documentation. # # ---------------------------------- Gateway ----------------------------------- # # Block initial recovery after a full cluster restart until N nodes are started: # #gateway.recover_after_nodes: 3 # # For more information, consult the gateway module documentation. # # ---------------------------------- Various ----------------------------------- # # Require explicit names when deleting indices: # #action.destructive_requires_name: true http.cors.enabled: true http.cors.allow-origin: "*" node.data: true
5.安装elasticsearch-head插件,用于可视化。
(1)、安装node
从地址:https://nodejs.org/en/download/ 下载相应系统的msi,双击安装。
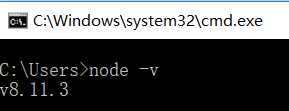
(2)、安装完成后在cmd里面执行node -v可以查看版本号,确认是否安装成功。
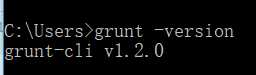
(3)、在cmd里面执行 npm install -g grunt-cli 安装grunt,安装完成后执行grunt -version查询版本号,确定是否成功。
(4)、下载elasticsearch-head插件,在https://github.com/mobz/elasticsearch-head中下载head插件,选择下载zip。
(5)、将其解压到elasticsearch的安装目录下面
(6)、进入elasticsearch-head插件目录里面,修改Gruntfile.js文件,在对应的地方加上 hostname:‘*‘。
connect: {
server: {
options: {
hostname:‘*‘,
port: 9100,
base: ‘.‘,
keepalive: true
}
}
}
6、测试安装是否成功。
(1)、进入elasticsearch目录的bin目录下面,点击elasticearch.bat文件,进行启动。
(2)、和第一步一样启动复制出来的另一个elasticsearch。
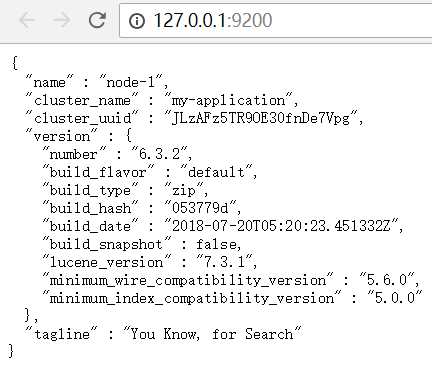
(3)、启动完成后在浏览器访问 http://127.0.0.1:9200,如果输出一下json串表示启动成功。
(4)、cmd进入elasticsearch-head插件的目录下面,执行以下命令 grunt server,显示如下这表示运行成功。

(5)、在浏览器访问 http:127.0.0.1:9100,就可以进行可视化查看。
标签:.data download module may 点击 names color www 表示
原文地址:https://www.cnblogs.com/jack1995/p/9370770.html