标签:交流 var app 手机 电脑 sdc src rmi store
不多说,直接上干货!
前期博客

核心安装包(Core Tarball)
该安装包包含核心的SDC软件,使该软件具有最小的软件连接器集合,当然你可以手动下载额外的节点(Stage)
① 通过Streamsets的UI进行安装,UI上点击的位置为:在该软件界面的右边(图标是一个礼物盒子。。。)。
② 也可以通过使用CLI进行安装,安装过程如下所示:
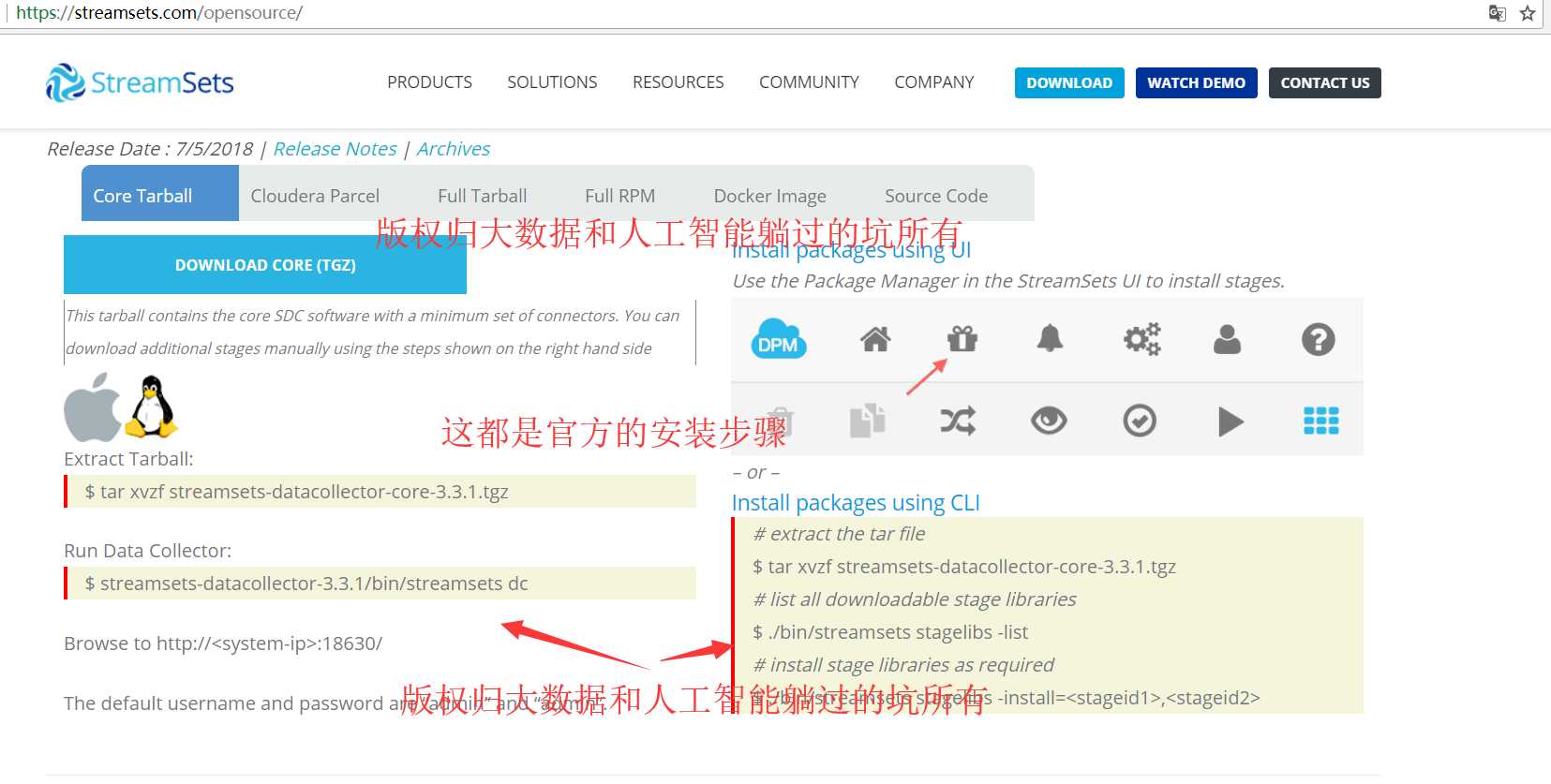
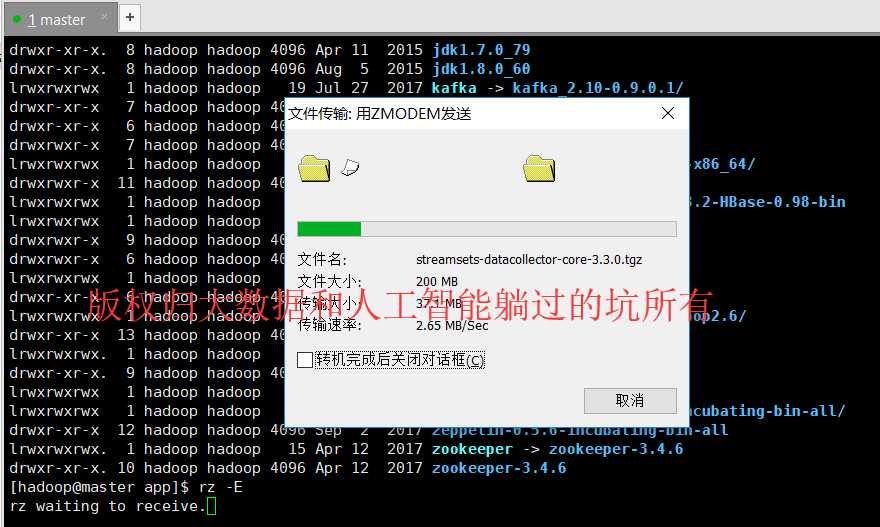
第一步、下载该【核心安装包】,比如版本为:streamsets-datacollector-core-3.3.0.tgz

第二步、解压该安装包
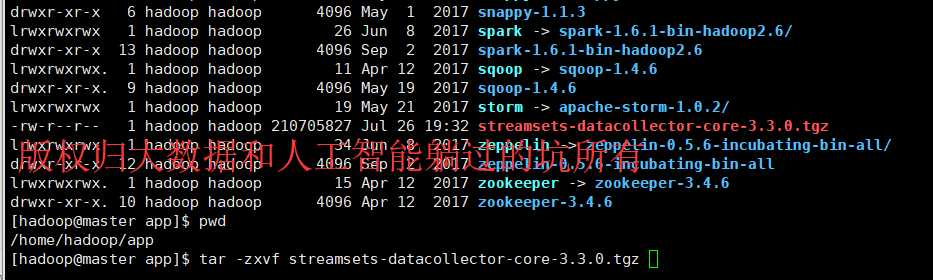
[hadoop@master app]$ tar -zxvf streamsets-datacollector-core-3.3.0.tgz

[hadoop@master streamsets-datacollector-3.3.0]$ ./bin/streamsets dc Java 1.8 detected; adding $SDC_JAVA8_OPTS of "-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -Djdk.nio.maxCachedBufferSize=262144" to $SDC_JAVA_OPTS Configuration of maximum open file limit is too low: 1024 (expected at least 32768). Please consult https://goo.gl/LgvGFl [hadoop@master streamsets-datacollector-3.3.0]$
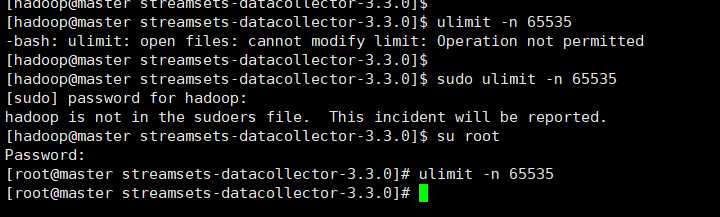
注:在这个启动的过程中会出现启动报错的情况,错误提示是:最大的文件数为1024,而streamsets需要更大的文件数,因此就要必要的设置一下环境了。
设置方式有两种:
(1)修改配置文件,然后重启centos永久生效,
(2)通过一个命令进行生效:
ulimit -n 65535 Browse to http://<system-ip>:18630/ The default username and password are “admin” and “admin”.

[hadoop@master streamsets-datacollector-3.3.0]$ pwd /home/hadoop/app/streamsets-datacollector-3.3.0 [hadoop@master streamsets-datacollector-3.3.0]$ ./bin/streamsets dc Java 1.8 detected; adding $SDC_JAVA8_OPTS of "-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -Djdk.nio.maxCachedBufferSize=262144" to $SDC_JAVA_OPTS Logging initialized @6514ms to org.eclipse.jetty.util.log.Slf4jLog Running on URI : ‘http://master:18630‘
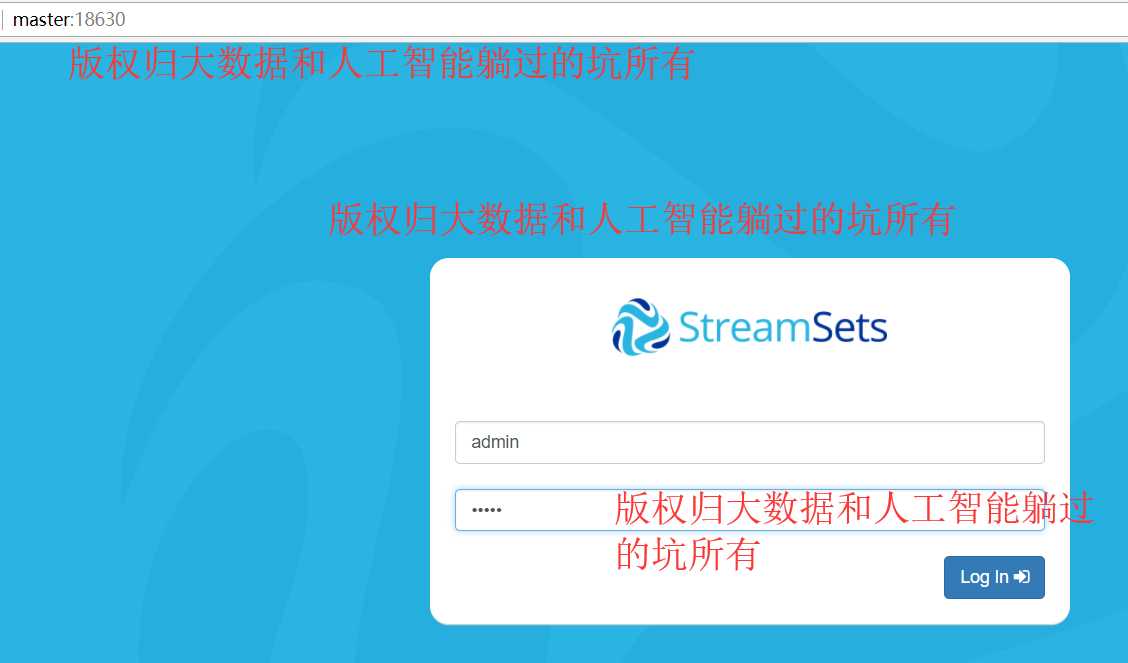
通过这种方式:你就可以看到正真的streamsets真面目了。。。。后面我们看看他真面目里面的一些细节。。。。这个工具主要进行数据移动及数据清洗有很大的帮助。
或者

[hadoop@master streamsets-datacollector-3.3.0]$ pwd /home/hadoop/app/streamsets-datacollector-3.3.0 [hadoop@master streamsets-datacollector-3.3.0]$ nohup /home/hadoop/app/streamsets-datacollector-3.3.0/bin/streamsets dc & [1] 2881 [hadoop@master streamsets-da
也许,你在启动过程中,会出现
安装成功的后续步骤(建议去做):
1、添加sdc用户的进程操作文件描述符的并行度
[root@master streamsets-datacollector-3.3.0]# vim /etc/security/limits.conf
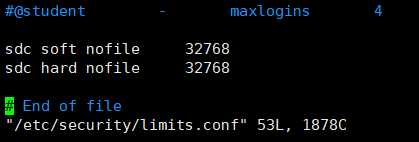
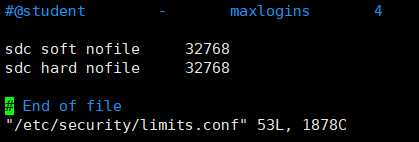
sdc soft nofile 32768 sdc hard nofile 32768
2、vim /etc/profile
[root@master streamsets-datacollector-3.3.0]# vim /etc/profile
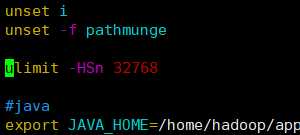
[root@master streamsets-datacollector-3.3.0]# source /etc/profile
3、创建文件目录,用于放日志信息
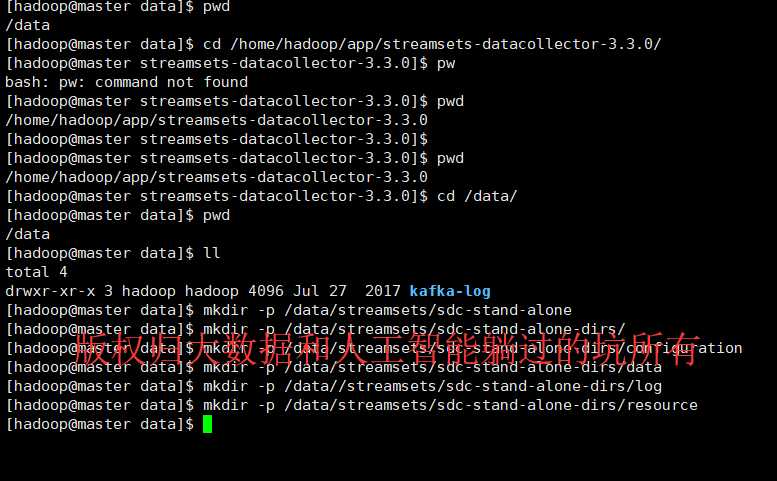
[root@master data]# su hadoop [hadoop@master data]$ pwd /data [hadoop@master data]$ cd /home/hadoop/app/streamsets-datacollector-3.3.0/ [hadoop@master streamsets-datacollector-3.3.0]$ pw bash: pw: command not found [hadoop@master streamsets-datacollector-3.3.0]$ pwd /home/hadoop/app/streamsets-datacollector-3.3.0 [hadoop@master streamsets-datacollector-3.3.0]$ [hadoop@master streamsets-datacollector-3.3.0]$ pwd /home/hadoop/app/streamsets-datacollector-3.3.0 [hadoop@master streamsets-datacollector-3.3.0]$ cd /data/ [hadoop@master data]$ pwd /data [hadoop@master data]$ ll total 4 drwxr-xr-x 3 hadoop hadoop 4096 Jul 27 2017 kafka-log [hadoop@master data]$ mkdir -p /data/streamsets/sdc-stand-alone [hadoop@master data]$ mkdir -p /data/streamsets/sdc-stand-alone-dirs/ [hadoop@master data]$ mkdir -p /data/streamsets/sdc-stand-alone-dirs/configuration [hadoop@master data]$ mkdir -p /data/streamsets/sdc-stand-alone-dirs/data [hadoop@master data]$ mkdir -p /data/streamsets/sdc-stand-alone-dirs/log [hadoop@master data]$ mkdir -p /data/streamsets/sdc-stand-alone-dirs/resource [hadoop@master data]$
修改配置文件
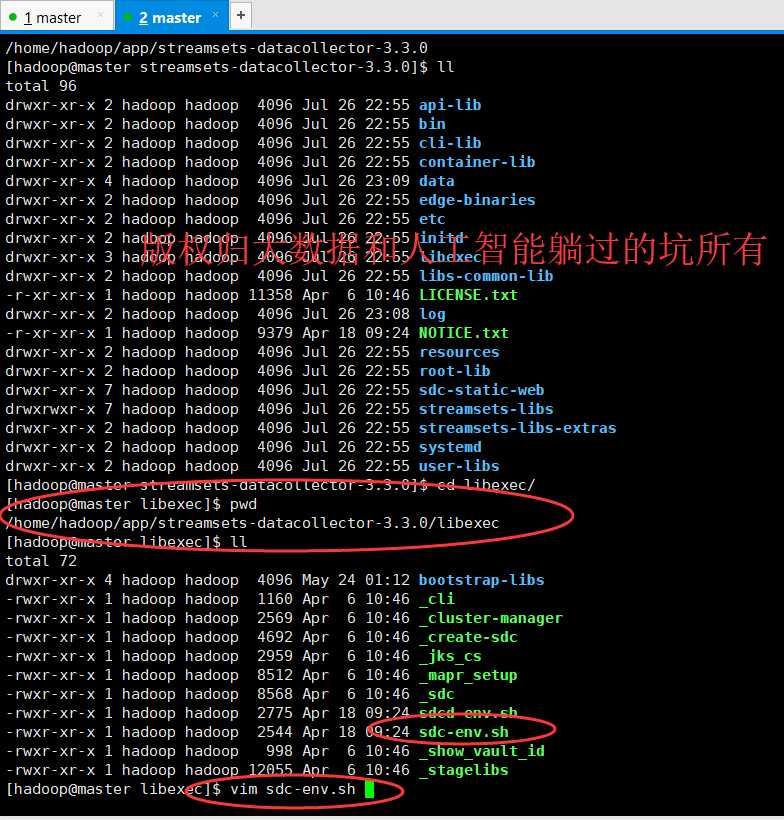
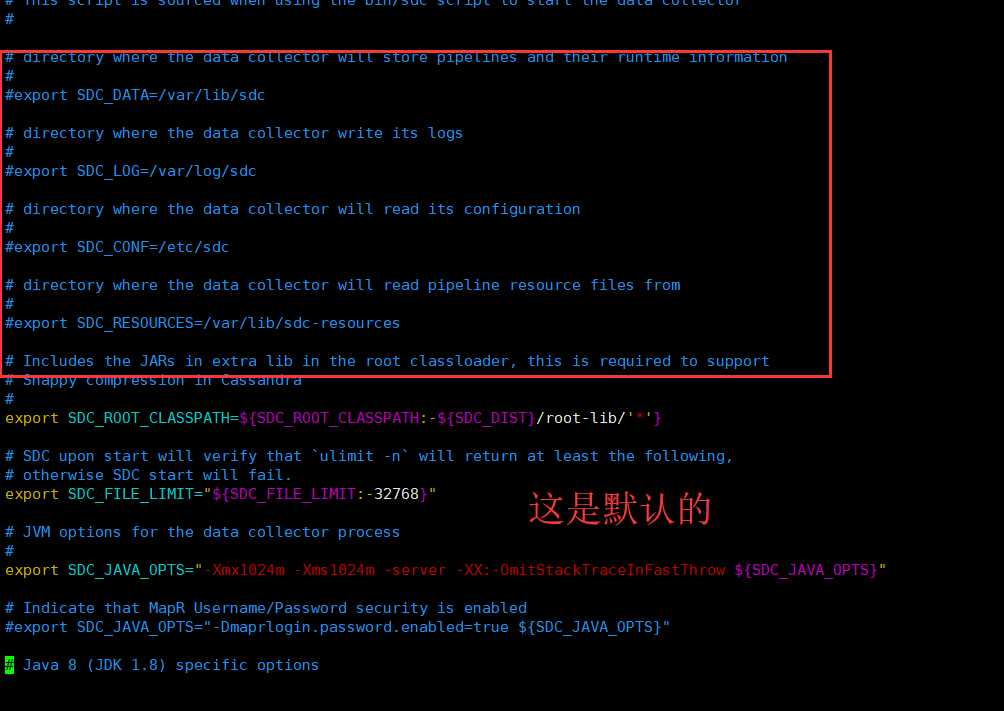
# directory where the data collector will store pipelines and their runtime information # #export SDC_DATA=/var/lib/sdc # directory where the data collector write its logs # #export SDC_LOG=/var/log/sdc # directory where the data collector will read its configuration # #export SDC_CONF=/etc/sdc # directory where the data collector will read pipeline resource files from # #export SDC_RESOURCES=/var/lib/sdc-resources
改为
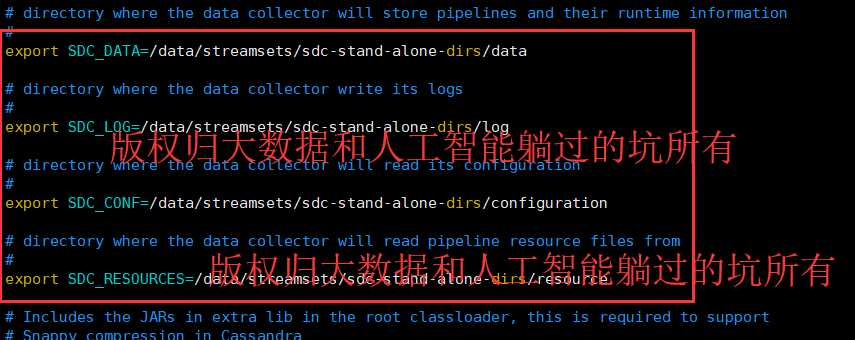
# directory where the data collector will store pipelines and their runtime information # export SDC_DATA=/data/streamsets/sdc-stand-alone-dirs/data # directory where the data collector write its logs # export SDC_LOG=/data/streamsets/sdc-stand-alone-dirs/log # directory where the data collector will read its configuration # export SDC_CONF=/data/streamsets/sdc-stand-alone-dirs/configuration # directory where the data collector will read pipeline resource files from # export SDC_RESOURCES=/data/streamsets/sdc-stand-alone-dirs/resource
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)


StreamSets学习系列之StreamSets的Core Tarball方式安装(图文详解)
标签:交流 var app 手机 电脑 sdc src rmi store
原文地址:https://www.cnblogs.com/zlslch/p/9375053.html