标签:math类 cts 意思 问题 实现 har sem temp 通过
在前面几章,看了整个String类的源码,给每个方法都行写了注释,但是太过凌乱,今天我就把String类的方法整理归纳,然后再讲一下String类比较难以理解的部分
特此声明:本文篇幅较大,涵盖知识点较多,请耐着性子读下去,毕竟写文章不易,写知识性文章更加不易!
这是第一部分的内容,由于String的函数较多,我将他们分为四大类,分别是构造性函数、转换性函数、功能性函数以及私有函数
如果你仔细看源代码的话,会发现每个私有函数都会在代码中被频繁调用,String把这些被多次用到的重复代码进行封装,
private final char value[]; private int hash; // Default to 0 private static final long serialVersionUID = -6849794470754667710L; private static final ObjectStreamField[] serialPersistentFields = new ObjectStreamField[0];
首先是四个属性,最后两个是用来实现序列化和反序列化的,详细内容会单独讲解
第一个属性:char value[]就表明了String字符串的本质,char数组表明它是引用类型,final表明它是常量,所以他是一个在JVM线程共享区的方法区中的常量,
所以每当我们创建一个String对象时,都会在常量池中查找是否已经存在该常量,若存在就将该对象指向该常量,若不存在就先在常量池中创建该常量,然后再指向这个常量。
这里讲一下常量和变量:可能有的同学对常量的概念很模糊,只知道常量和变量是相对的,
变量:我们常说的局部变量和成员变量都是变量,变量分为基本类型和引用类型,基本类型就是那八大类型(boolean,byte,char,short,int,long,float,double)而引用类型分为三种,数组,类和接口
常量:常量分为俩种,字面值常量和自定义常量,比如说Math.min(2,3)其中的2和3就是直接传入的俩个常量,在Math类中public static final double PI = 3.14159265358979323846这么定义的PI就是自定义常量,
也就是我们通常意义上的常量,常量就是其值不可改变的,也就是用final修饰,比如说2就表示2,PI就表示3.14159265358979323846。static修饰词限定了该常量的值被类的对象所共享,可以通过类名直接调用,Math.PI。
第二个属性hash,这个属性会带你走进hashCode()方法的神秘世界,详情请参照hashCode()方法,这个hash属性是用来在一定程度上标识字符串唯一性的,你可以把它认为成一种ID,但是hash并不是地址值,详细去看一下hash表的数据结构,
这个hash只能称之为哈希码,绝对不是什么地址值,也就是说hashCode方法返回的是对象在内存中的地址的说法是错误的
private static void checkBounds(byte[] bytes, int offset, int length)
在String构造函数中用于检查边界,也就是检查传入的offset和length是否有问题
String(char[] value, boolean share)
打包私有构造函数,它为speed.this构造函数共享值数组,总是需要使用share == true来调用。需要单独的构造函数,因为我们已经有一个公共String(char [])构造函数,它可以复制给定的char[]。
不要纠结与这个Boolean类型的参数,它只是一个用来区别于String(char[])构造器的
private boolean nonSyncContentEquals(AbstractStringBuilder sb)
private static class CaseInsensitiveComparator implements Comparator<String>, java.io.Serializable {}
局部内部类,是String实现不区分大小写的equals方法的核心代码实现,详情在public boolean equalsIgnoreCase(String anotherString)中
private int indexOfSupplementary(int ch, int fromIndex)
private int lastIndexOfSupplementary(int ch, int fromIndex)
static int indexOf(char[] source, int sourceOffset, int sourceCount,String target, int fromIndex)
static int indexOf(char[] source, int sourceOffset, int sourceCount,char[] target, int targetOffset, int targetCount,int fromIndex)
static int lastIndexOf(char[] source, int sourceOffset, int sourceCount,String target, int fromIndex)
static int lastIndexOf(char[] source, int sourceOffset, int sourceCount,char[] target, int targetOffset, int targetCount,int fromIndex)
String的构造函数,还是很让人懵逼的,总的来说他们的具体功能是就是将String ,char[],byte[],StringBuilder StringBuffer 转换为String类型,后几个大家都容易理解,就是将其他类型装换为String类型,但是第一个呢,将String转换为String?这有什么用呢?且听我细细道来
我们先看源代码(由于我之前在String源码解析中已经发过了,这里就不重复发了),new String()只有一行this.value = "".value;,new String(String original)只有两行this.value = original.value;this.hash = original.hash;很简单的吧
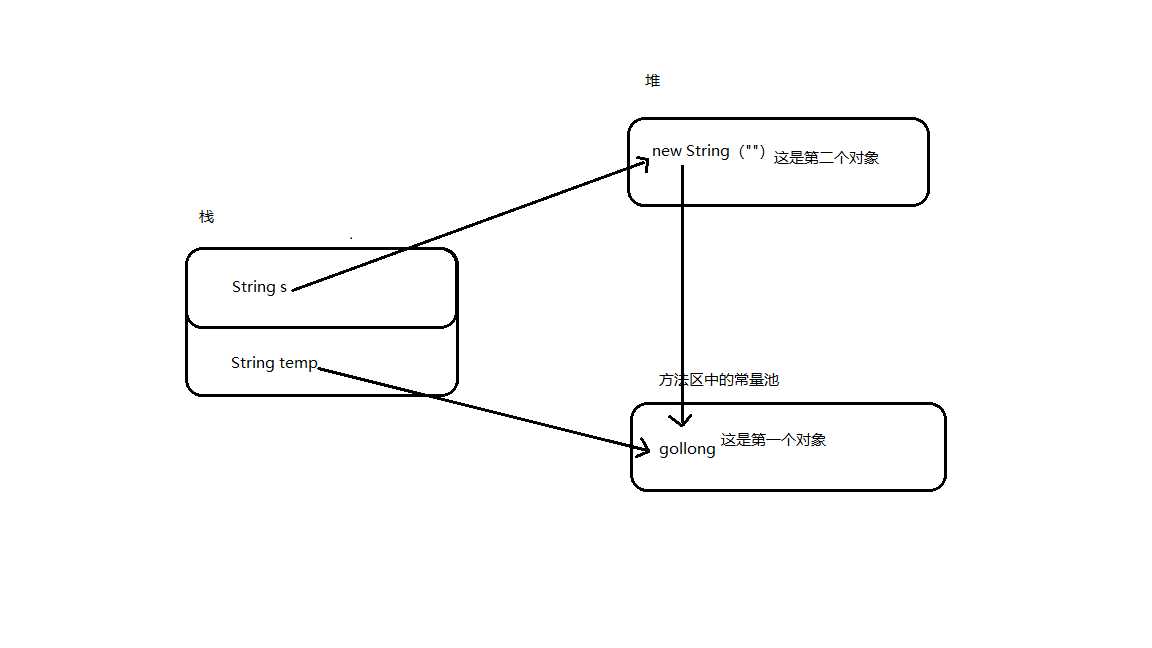
这就引出了一道经典的面试题:String s = new String("gollong")创建了几个对象?
首先你要明白什么创建对象,String s;并没有创建对象,只是声明一个引用,new String("gollong")才是真正的创建对象,然后String s = new String("gollong")完成引用的实例化。
其实你要明白这是调用的一个构造函数,传入的参数是String类型的,那么就很简单了,我们将这一行代码分解为如下两行
String temp = "gollong";
String s = new String(temp);
这就好理解了吧,首先会在常量池中创建一个“gollong”,这是第一个对象(当然是在常量池中本身没有这个对象的前提下),其次会在堆中创建第二个对象,因为new出来的对象肯定及一定在堆中,再把前一个对象当做实参传入到其中
我用一张概念图来解释这个问题:
public String() public String(String original) public String(char value[]) public String(char value[], int offset, int count) public String(int[] codePoints, int offset, int count)
看上去好像是将int数组转换为String,但是你去试试,输出的东西并不是简单的把每一个int值链接起来,这里面大有学问,我们都知道java是采用Unicode字符集的,那Unicode内是怎么表示的呢,
Unicode内部一共有三种长度的字符,分别占用一个字节、两个字节、四个字节,而这个int类型的数组就是指符合Unicode的四个字节长度的字符,在编码一章中再讲吧,太复杂了 @Deprecated public String(byte ascii[], int hibyte, int offset, int count) public String(byte ascii[], int hibyte)
已经过时的俩个方法,其意义是将byte数组转换为String对象,我们都知道byte类型只占用一个字节,而组成String的char类型却占有两个字节,这就涉及到互相转换时高8位的处理问题了
而对于不同的编码方式(请注意:在不详细区别编码和解码是,编码就是指编码和解码的统称),处理方式是不同的,所以这两个构造器可以让使用者指定高8位的内容,但是人为指定的往往是不正确的
所以标注为过时(请注意:过时并不意味着不能用,只是不推荐使用,因为它总有一 天会被淘汰的),才有了以下的六个指定编码方式的方法。
public String(byte bytes[], int offset, int length, String charsetName)throws UnsupportedEncodingException public String(byte bytes[], int offset, int length, Charset charset) public String(byte bytes[], String charsetName)throws UnsupportedEncodingException public String(byte bytes[], Charset charset) public String(byte bytes[], int offset, int length) public String(byte bytes[])
指定编码方式的将byte转换为char,其中可以通过两个方式指定,一种是传入编码的字符串表示,最经常使用的方法,另一种是传入Charset对象,毕竟能不造对象就不造,浪费空间 public String(StringBuffer buffer) public String(StringBuilder builder)
就是一些负责把其他类型的变量转换为String类型,或者把String转换为byte[],char[]
public static String format(String format, Object... args) public static String format(Locale l, String format, Object... args) public static String join(CharSequence delimiter, CharSequence... elements) public static String join(CharSequence delimiter,Iterable<? extends CharSequence> elements)
public static String valueOf(Object obj) public static String valueOf(char data[]) public static String valueOf(char data[], int offset, int count)
上面俩个内部调用的就是String的构造器new String(char data[])和new String(char data[],int offset,int count) public static String copyValueOf(char data[], int offset, int count) public static String copyValueOf(char data[]) public static String valueOf(boolean b) public static String valueOf(char c) public static String valueOf(int i) public static String valueOf(long l) public static String valueOf(float f) public static String valueOf(double d)
static修饰的类函数,可通过String.直接调用,返回一个String,类似于工具类的做法, 经常被用来将单个的各种类型转换为String,其实内部调用的就是八大数据类型的包装类的toString方法 public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) public void getBytes(int srcBegin, int srcEnd, byte dst[], int dstBegin) public byte[] getBytes(String charsetName)throws UnsupportedEncodingException public byte[] getBytes(Charset charset) public byte[] getBytes() public char[] toCharArray()
由于功能性函数很多,我把他们进行了详细的分类
继承自Object类的三个方法,都很重要
public boolean equals(Object anObject) public int hashCode() public String toString()
通过比较此字符串和指定的内容,返回一个boolean类型,一般用在if()和while()语句中,都是很常用的方法
public boolean isEmpty()
判断字符串是否为空,也及时判断char数组的长度是否为0 public boolean contentEquals(StringBuffer sb)
public boolean contentEquals(CharSequence cs)
判断内容是否相等,StringBuffer是什么我们都知道,CharSequence 是个什么呢?其实CharSequence 是字符序列接口,我们所接触到的像String,StringBuffer,StringBuider等都是它的实现类。大家既然都是字符串,哪来比较下内容也无可厚非嘛
public boolean equalsIgnoreCase(String anotherString)
忽略大小写的比较,核心调用的是regionMatches方法,而regionMathes是用来测试俩个字符串某些部分是否相等,而equals只能整个比较,这就是我们用它的原来,但是一般不怎么使用,都是用contains
public boolean regionMatches(int toffset, String other, int ooffset,int len)
public boolean regionMatches(boolean ignoreCase, int toffset,String other, int ooffset, int len)
判断字符串是否以指定字符串开始或结尾
public boolean startsWith(String prefix, int toffset)
public boolean startsWith(String prefix)
public boolean endsWith(String suffix)
判断字符串是否匹配指定的正则表达式
public boolean matches(String regex)
判断字符串是否包含指定的字符序列,注意传入的是CharSequence对象
public boolean contains(CharSequence s)
比较函数其实也是判断函数,只不过下面的三个函数返回值不是boolean类型的,我将他们单独罗列出来,其实我们一般不会手动调用这些函数的,数组工具类Arrays中有一个方法排序方法sort()
public static void sort(Object[] a):这是不指定排序方式(元素之间怎么比较)的方法,其实内部就是调用自然排序,也就是实现comparable接口实现的comparTo方法
public static <T> void sort(T[] a, Comparator<? super T> c):这是指定外部比较器的方法,这个比较器就是新建一个类实现Comparator接口重写compare方法的比较方式,要比较的类型当做泛型传递进去,
在String类中,写了一个成员内部类来实现这个比较器,在重写compare方法,得到的功能是忽略大小写的比较,在public int compareToIgnoreCase(String str)方法内得到体现,其实这个方法和public boolean equalsIgnoreCase(String anotherString)功能是一样的
public int compareTo(String anotherString) public static final Comparator<String> CASE_INSENSITIVE_ORDER = new CaseInsensitiveComparator(); public int compareToIgnoreCase(String str)
很常用的一些函数,具体作用是查询某个字符或字符串的位置
public int length()
返回字符串的长度,也就是value的长度 public char charAt(int index)
返回字符串中某个下标对应的字符,很实用的方法 public int codePointAt(int index)
还记得codePoint是什么吗?他为什么是int类型的呢?去上面看看就明白了。返回对应下标的Unicode codePoint public int codePointBefore(int index)
返回对应下标前一个的Unicode codePoint public int codePointCount(int beginIndex, int endIndex)
返回指定范围内Unicode codePoint的总数 public int offsetByCodePoints(int index, int codePointOffset)
返回此 String 中从给定的 index 处偏移 codePointOffset 个代码点的索引 public int indexOf(int ch) public int indexOf(int ch, int fromIndex) public int lastIndexOf(int ch) public int lastIndexOf(int ch, int fromIndex) public int indexOf(String str) public int indexOf(String str, int fromIndex) public int lastIndexOf(String str) public int lastIndexOf(String str, int fromIndex) public int indexOf(int ch) public int indexOf(int ch, int fromIndex) public int lastIndexOf(int ch) public int lastIndexOf(int ch, int fromIndex) public int indexOf(String str) public int indexOf(String str, int fromIndex) public int lastIndexOf(String str) public int lastIndexOf(String str, int fromIndex)
上面的indexOf方法都是返回指定字符或者字符串第一次出现的下标,lastIndexOf是返回指定字符或者字符串的最后一次出现的下标,fromIndex用于指定开始的位置,这里需要注意一点:
从我们的习惯出发,肯定是自左向右搜索,indexOf方法便是这样自左向右,fromIndex参数用于指定开始搜索的位置
而lastIndexOf却是自右向左搜索,找到的第一个便是我们要寻找的最后一个字符或字符串,所以fromIndex是指定开始搜索的位置,实际上就是我们习惯自左向右搜索方式的结束位置
平时我们获得字符串可以不是很满意,需要我们通过一些函数去掉里面的某些字符或者替换一些,再或者进行大小写转换,没错,下面的函数你都会用到。
public String substring(int beginIndex) public String substring(int beginIndex, int endIndex)
切片函数,说实话我学java到现在,不知道怎么叫这个函数,只时称呼他substring,这几天在看python,python里面是切片函数,听起来还不错就借用啦,哈哈,顾名思义,用一个字符串切出你想要的部分,说实话java中的切片函数远没有python中的好用,大家去看看python的就明白了 public CharSequence subSequence(int beginIndex, int endIndex)
也是切片,返回的是CharSequence接口对象,说实话返回的就是一个String对象(自己去看源码就知道了),其实就是一个向上转型(CharSequence s = new String())。 public String concat(String str)
类似于StringBUffer中的append函数,在字符串的结尾追加字符串,其内部调用的就是String(char[] ,boolean)构造器的,但是这种字符串追加的代价高昂,所以我们一般选择StringBuffer和StringBuilder public String replace(char oldChar, char newChar) public String replaceFirst(String regex, String replacement) public String replaceAll(String regex, String replacement) public String replace(CharSequence target, CharSequence replacement)
以上四个是替换函数,其中第一个只能替换字符串中的所有的指定字符,注意只能替换单个字符
而第四个函数重构此方法后参数就变为了CharSequence接口,现在对CharSequence很熟悉了吧,所以replace其实什么都可替换,只不过一般我们都是操作字符串String,所以经常使用的是第三个。而第二个仅仅替换找到的第一个指定字符串
public String[] split(String regex, int limit) public String[] split(String regex)
切割函数,根据指定的正则表达式切割字符串,返回结果是String数组,其中参数limit用于现代最终字符串数组的长度,前面都讲过了,不进行详细的讲解了 public String toLowerCase(Locale locale) public String toLowerCase() public String toUpperCase(Locale locale) public String toUpperCase()
将字符串中的字符全部转换为大写或者小写,其中locale用于指定本地规则 public String trim()
去除字符串两端的空格,很实用的小函数 public native String intern();
最后一个函数intern很有意思,作为一个native方法,很底层,但是我们依然可以通过一个例子来揭开它神秘的面纱,我们明天实战练习见!!!
写了一天,可能有些字打错了,或有些没讲清楚,望大家见谅☆ ̄(>。☆)。
标签:math类 cts 意思 问题 实现 har sem temp 通过
原文地址:https://www.cnblogs.com/gollong/p/9372868.html