标签:原来 例子 时钟周期 访问 是你 产生 完整性 实用 应用
以前同是DDR3的无知少年,由于项目需求、工作需要,有幸深入研究DDR3,中间也确实历经各种盲目阶段,查询资料、建立工程、调试错误等等,如今对此不敢说是精通,也只能说是基本入门,写此文章的目的也无非是想让那些和当初的我一样的初学者少走些弯路而已,也只当是抛砖引玉,也希望大神们能多多指教!提前谢过了,下面也为了不让大家看的那么无聊,也会适当换个方式,也望大家能给几分薄面,大神们多多指点,小菜鸟们就好好学习吧,毕竟也是手打的材料,下面入正题~
作为初学者,我认为最好能做到以下三个方面:材料准备与学习、工程建立与调试、日常总结与记录。
有些人会问谁都知道要学习资料,你也猜到了我要说手册,废话,傻子都知道没有手册搞不定的,当然是不只手册啦,如果你是第一次接触,最好下载几篇相关的学术论文,什么,不知去哪找?!不行就百度,我是在知乎上下的(本人西电,有没有师姐校友啊,嘿嘿,本校免费下),简单来说就是下载几篇相关论文,自己对相关的结构流程能有所了解,最好是你要调试啥就找相关的(我当时就傻x了,调DDR3,下了几篇DDR2当然可以借鉴,但心里受影响啊),当然还有最最重要的官方的datasheet,没有它,想搞定DDR3?洗洗睡吧~当然实验平台我就不说了,如果条件简陋,或者囊中羞涩,软仿也可以,怎么?瞧不起软仿?没钱想学习还不允许吗?我当初就硬着头皮软仿了一周,可坑爹的实验室有板子,我愣是不知道,后来才找老师拿了她,于是才上了她,好啦,扯远了,有板子,板子的原理图也要有吧,材料这些就可以了,至少你可以有事情干了!
再就是建立工程与工程调试,对于初学者网上都会说先看手册,建个example,跑一跑,了解下例程,对,这一步必须要做,而且要认真做!但是可能等最后你会发现,最终的结果可能并没有example那么复杂……,下面再细说,工程调试是一个很无聊但是很艰巨的过程,它的重要性,我在这就不说了,觉得不重要的又到睡觉的时候了。
最后就是日常总结和记录,像是日记,可并不是,这算是公开的,你师妹想看看?你不给?开玩笑,我一直认为这是个好习惯,日常犯的一些错误做好记录,总结原因和解决办法,这将会是一笔财富!当然可能没有过习惯的人,一开始不知该记录些啥,我一开始也是如此,我就想些啥就写啥,写着写着就知道了,现在不写都难受,这是病,不过不用治。简单来说一些实验现象,或者日常的仿真结果以及分析总结等,可以自己看,哪怕老板让你写报告你也有材料不是?抓紧拾起你的笔,敲起你的键盘,跟着我左手右手一个……
下面到了真刀真枪硬干的时候了,有本事你别跑!
先简单介绍下我的准备,而后简单介绍下DDR3的相关原理性知识,作为专业文档,这部分内容要有,而且必须有!我用的是X家的Virtex-6的FPGA,DDR3用的是美光的,论文下了几篇,名字我就不列了,自己查去,下面我简单介绍下DDR3,当然挑和工程相关的,别的自己去查资料。
算啦,贴张图,谁让我勤政爱民呢,重点的已经标出来了,自己动动手指就可以,文档里有的我就不多说了,自己看,介绍下别的几个关键词,很有用的!
DDR(Double Data Rate SDRAM),即双倍速率同步动态随机存储器,含义是数据会被时钟的上升沿和下降沿采样,相对于时钟上升沿采样,这种方法相当于把采样时钟频率提升了一倍。DDR3 SDRAM在降低系统功耗的同时很大程度上提高了系统性能,其理由“fly-by”和动态片上匹配技术对于信号完整性的改善效果明显。
组成DDR3的存储单元称为逻辑bank,在逻辑bank中,先指定一个行,再指定一个列,可以准确地定位到所需的存储位置,这是DDR3寻址的基本原理,目前,DDR3基本上是8bank设计。
这是一个与存储子系统相关的术语,并不针对存储芯片,在PC上的北桥芯片用于控制存储器与CPU之间的数据交换,为了高效传输数据,北桥芯片是存储器总线的数据位宽等同于CPU数据总线的位宽,这个位宽被称为物理Bank(又称为Rank),当前这个位宽基本为64bit,每个内存颗粒的位宽为8bit,为了满足Rank所需的64位宽,需要8颗内存颗粒并行组成。
在对DDR3的某一个bank内数据进行读/写访问前,首先必须将该bank中数据所在的行激活,一旦激活,则该行将保持激活状态直到发送预充电命令到DDR3。发送行激活命令式,bank地址与相应的行地址同时发出;行激活命令发送后,随后发送列地址寻址命令与具体的读/写操作命令,由于这两个命令也是同时发出的,所以一般都会以读/写命令来表示列寻址。从行有效到读/写命令发出之间的时间间隔被定义为tRCD,tRCD是DDR的一个重要时序参数,广义的tRCD以时钟周期为单位,如tRCD=3,就代表延迟周期为3个时钟周期。
DDR3执行bank的行激活命令后,可以发送读/写命令对该行进行读/写操作,在发送读/写命令时,引脚A10决定是否允许自动预充电操作,如果允许进行预充电,那么读/写命令结束时会自动对该行进行预充电,否则该行将一直保持激活状态控制逻辑可继续对该行进行读/写操作
DDR3采用数据掩码(DQM)技术,用于屏蔽不需要的数据。通过采用DQM,DDR3控制器能够以字节为操作单元指示I/O端口数据的有效性,当然在读取DDR3时,被掩码掩掉的数据仍然会从存储器中读出,只是在“掩码逻辑单元”处被屏蔽
数据读取完成之后,为了释放DDR3内读出放大器的空间,以供同位置bank内的其他行寻址及传输数据,DDR3芯片将执行预充电命令来关闭当前的工作行。预充电对航中所有的存储单元进行数据重新加载,并对行地址进行复位,其中A10决定是对某一个bank或所有bank进行预充电。预充电命令之后,要经过一段时间才允许发送行激活命令操作新的工作行,这个时间间隔称为tRP
DDR3需要不断进行刷新操作才能在存储单元中维持数据的有效存储。虽然预充电能够针对一个或所有bank中的工作进行刷新,但是预充电命令与操作相关,不能保证所有存储空间的遍历,同时其操作时间也不固定。而刷新操作则有固定的操作周期,一次对所有行进行操作,以维护存储单元中的所有数据。但是,与预充电不同,刷新操作的行是指所有bank中地址相同的行,而预充电中各bank中的工作行地址并不一定是相同的。
刷新操作分为两种:自动刷新与自刷新。对于自动刷新,在刷新过程中,所有bank都停止工作,而每次刷新结束后,DDR3才可以进入正常的工作状态,即在刷新期间,所有工作指令只能等待而无法执行。自刷新则主要用于休眠模式低功耗状态下的数据维护,此时不再以高系统时钟工作,而是根据内部的时钟进行刷新操作。
突发是指在同一行中相邻的存储单元连续进行数据访问,连续访问的时钟周期数就是突发长度,突发长度由模式寄存器MR0确定,可设置为固定模式:BC4或BL8模式,即在读/写操作室通过A12选择突发长度4或8。进行突发传输时,只要指定起始列地址与突发长度,DDR3就会依次地自动对后续相应数量的存储单元进行读/写访问,而不再需要DDR3控制器连续的提供列地址。在这种模式下,除了第一次数据的访问需要若干个周期外,后续的每次数据只需一个周期即可获得
模式寄存器用于设置DDR3 SDRAM的工作模式,目前支持4个模式寄存器,分别为MR0、MR1、MR2、MR3,其中MR0用于设置DDR3的基本工作模式,包括突发长度、突发类型、CAS延迟和DLL复位等。MR1用来存储DLL使能、输出驱动长度、Rtt_Nom、额外长度和写电平使能等。MR2用来存储控制更新的特性、Rtt_WR阻抗和CAS写长度。MR3用来控制MPR。
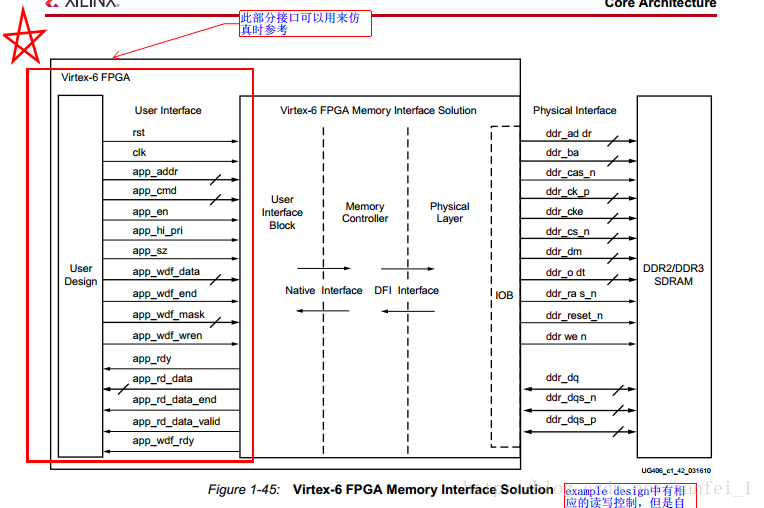
Xilinx公司提供的MIG工具适用于高速存储器接口的解决方案,MIG工具中的DDR3 SDRAM控制器设计运行用户在V6等器件中通过用户接口快速建立FPGA内部控制逻辑与外部存储器的访问连接,DDR3 SDRAM存储器接口包括用户接口模块、存储控制器、物理层模块、以及本地接口和物理层接口等。
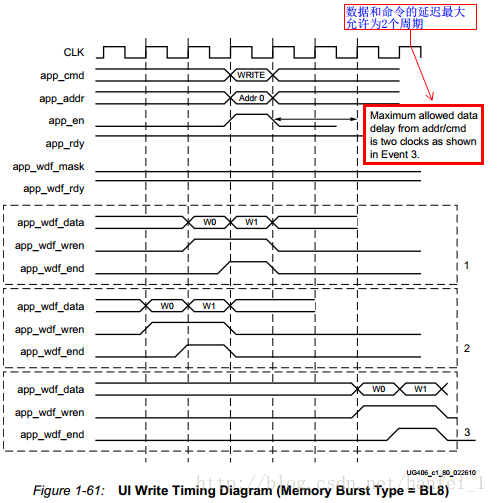
下面再重申下几个重要的内容,搞清以下几个:tRCD(RAS to CAS delay)、CL(CAS Latency,CAS潜伏期/RL,仅在读取时出现)、CWL(CAS Write Latency)、附加延时AL、BL(Burst Length,DDR3的预取为8bit,所以BL固定为8),BC(DDR3增加了一个4bit Burst Chop 突发突变)。
对与DDR3的工作流程资料里有,鉴于篇幅原因,就不提了,也该自己看看了。
首先,在CORE Generator中建立一个核。
如果你有参数那很好,按照你的参数建立,如果你没有芯片资料,但有前辈的测试工程,也可以,在工程目录下找到datasheet.txt的文件打开,里面有以前建立核的相关配置,当然你如果建立核之后,也会生成这样一个文件,配置也都在里面,如果你啥也没有,只想跑个仿真,也可以!那就一路默认,或者任意配置,反正又不犯法。
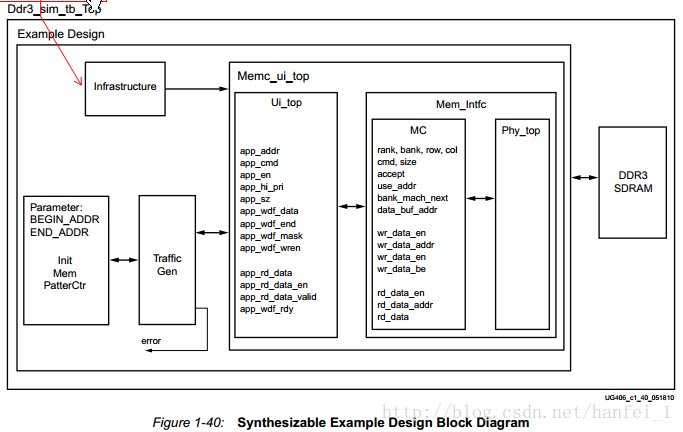
建好之后,任务就来了,如果你是一个老油条,就不用我多说了,如果你是新手你就按照手册中建立仿真的过程走一下?算了我告诉你吧,MIG工具最终的生成结果,存放在名为的文件夹中,< component name >文件夹中包含3个文件夹:docs:包含了设计中的相关文档。example_design:在仿真以及硬件测试中均可使用,除了控制器设计外,example_design还包含了可综合的测试文件,该测试文件可生成读写命令,并比较逻辑验证写入数据与读取数据的一致性。user_design:中仅包含控制设计,允许用户根据自身需求设计应用逻辑(测试文件)。
想直接分析,可以!把ipcore_dir\ddr3\example_design\rtl下的文件全部添加到你新建的工程中,还有ipcore_dir\ddr3\example_design\sim目录下的
当然,你如果习惯用modelsim,可以按照datasheet中的指示进行,我是有点懒,就直接添加了,下面可以简单配置下顶层参数,可以更快的仿真,将SIM_BYPASS_INIT_CAL设置为FAST,你点了运行了没?咋还不点?!让程序跑着,下面说下咱们的工程,example_design中有一个流量生成器,简单来说就是产生数据,以及最终接收数据给你的,这部分也是用户可以编辑删除修改的,也是和user_design的区别,user_design顾名思义,用户的设计,所以流量生成器当然是自己定义了,别的基本相同,对于 example_design仿真我就不具体分析了,自己看看就可以,我还是说些实用的吧!
example_design只是让你能对DDR3的工作有所了解,实际中的应用还是要利用user_design,并在此基础上进行修改,具体的修改等细节的工程问题,在总结中介绍,下面对example_design工程进行一些分析:
数据由流量产生器产生,经过用户接口部分,存储器控制部分,物理层部分传输给外部DDR3存储器,数据接收反之,具体每个文件是干啥的,看手册吧。反正我调程序是没改过Memc_ui_top里的程序,只是改过顶层的参数。
下面是user_design中的实现框图,我们要做的就是建立自己的user_design
你也许会说,一点根据都没有,怎么建?还是手册。
手册中还有几幅时序图,有BL=4的等等,具体信号的作用以及输入输出关系,因果关系我就不说了,手册中有信号线的说明,一看就懂,我们控制的也就是按照这些时序图来写,上面的指是一个例子,仅供参考。
最后这一部分就不像上两部分那么枯燥了,下面主要是我日常的总结,主要包括具体的工程实现与仿真分析,以及遇到的问题以及解决方案。此部分含金量很高,我尽量写的详细些,大家也认真体会一下。
参数设置:
输入时钟:125M(此时钟是外部芯片接的晶振时钟,内部使用需要进行倍频分频)
主时钟:400M(由输入时钟倍频得到)
突发长度:8(期间用过4,具体原因,下面再说)
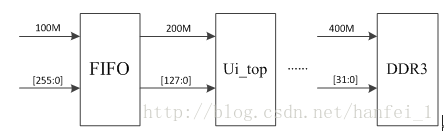
下面以一个框图说明位宽时钟关系
首先以发送数据为例,用户端数据首先经过FIFO缓存,解决跨时钟域的问题,FIFO的写入时钟为100M,数据位宽为256bit,FIFO的读取时钟为200M,位宽为128bit,主时钟为400M,用户时钟为此主时钟分频得到,可以验证数据量:200M*128bit = 400M*2*32bit(其中2为上下沿发送)。
接下来对工程进行简要描述:最一开始数据由一个流量产生器traffic_generator发出,首先对DDR3写数据,数据每加一,地址加8(突发长度为8,而且貌似规定地址必须加8,我试过4,不成),写数据地址加到4000时,写操作结束,开始读数据,同样是地址加8,当然读完4000为止。读写数据以及读写地址由于是跨时钟域处理,所以都需要经过FIFO(具体的设置我就不说了,基本设置),也就是4个FIFO,写数据FIFO,写地址FIFO,读数据FIFO,读地址FIFO,其中两个地址FIFO是可以IP核复用的,对于4个FIFO的读写将成为此次设计的重点以及难点,我也只能说下大体思路,其余的就靠大家自己摸索了。
首先对于写数据以及写地址FIFO的写使能,只要不满就可以写,而我们主要控制的就是何时读,以及如何读,主要通过状态机完成,写数据FIFO的读使能和用户接口的写使能(app_wdf_wren)可以认为同步,我们要控制产生的也即是这几个信号:app_wdf_wren,app_wdf_end,wr_dfifo_ren,wr_afifo_ren,决定这几个信号的输入信号:app_wdf_rdy,app_rdy,wrq(写请求,不空同时初始化完成就有写请求)。
首先对于读数据以及读地址FIFO的写使能,只要地址和数据有效就可以写,对于读数据的读使能,只要FIFO不空就出数据,而我们主要控制的是读地址FIFO的读使能,主要通过状态机完成,我们要控制产生的也即是这几个信号:app_en,rd_afifo_ren,决定这几个信号的输入信号:app_rdy ,rdq。
程序设计完成,最好对DDR3 IP核的参数进行下配置,以方便仿真,可以将SIM_BYPASS_INIT_CAL设置为FAST,可以跳过最一开始的初始化,节约仿真时间,将ORDERING设置为STRICT,中间数据不会进行重排序,便于查看中间的仿真结果。
下面就是综合、实现、生成bit文件,可以上板子了……
如果您没遇到问题,那你真是命好!
还是说说我这命不好的吧!
问题总结一:系统不能初始化
一般如果正常添加生成核后自带的user_design,能正常编译通过,不会存在不能初始化的问题!!!在此工程中,按照设置总结进行相应设置,进行仔细检查,利用chipscope进行信号抓取,可以一个触发信号一个触发信号的测试,而后分析原因,切不可贸然怀疑硬件的问题(前提是曾经成功过)
问题总结二:虽可以初始化,但是没有写入数据
此问题主要是出现在顶层例化中,初始化信号未进行模块的正确连接,主要还是不细心,仔细进行顶层检查,尤其是自己动手修改过的地方,一定要注意!
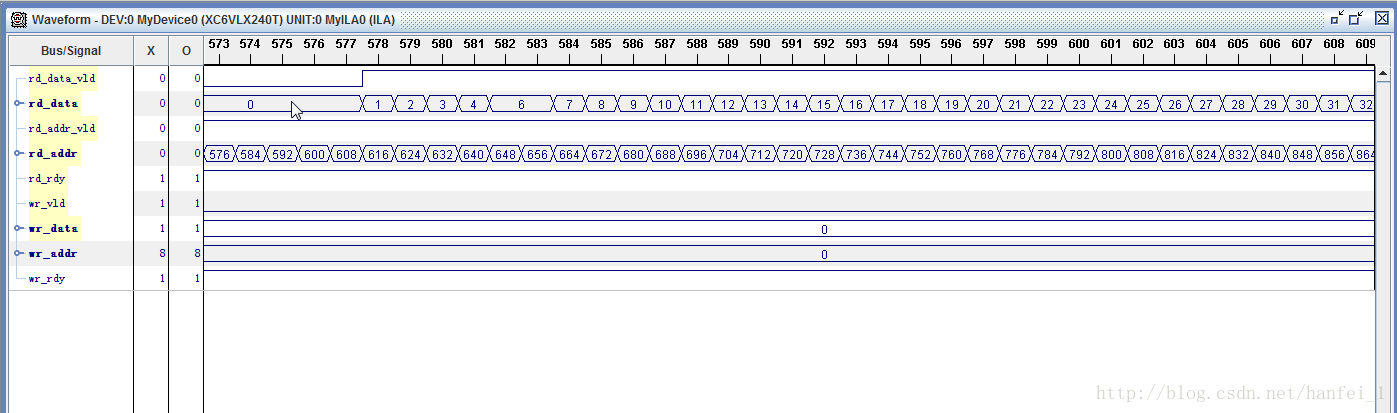
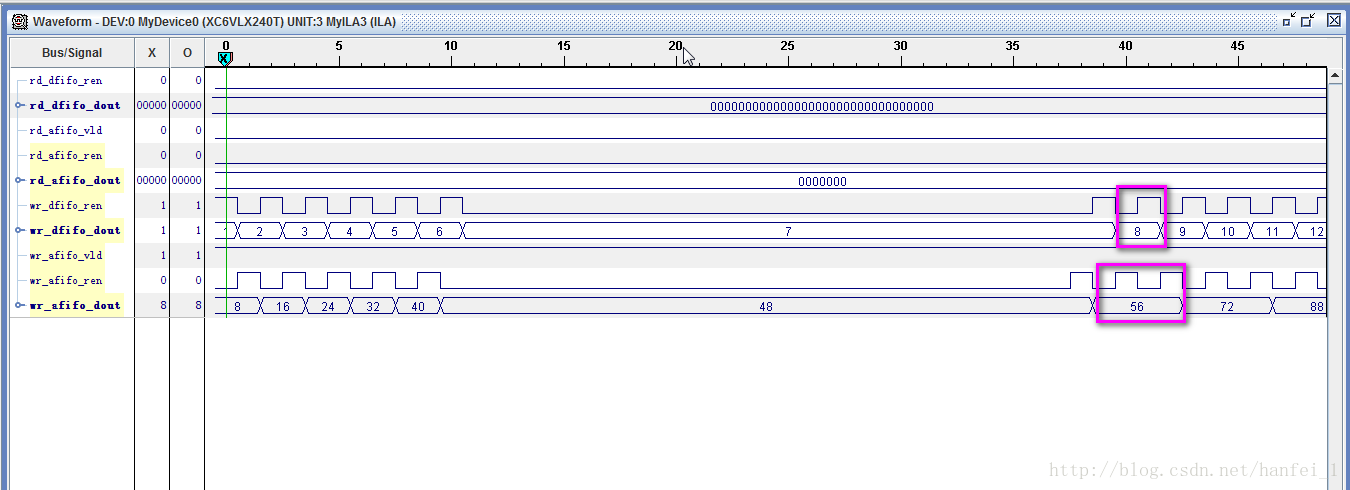
下面说一下神奇的现象:(写入数据开始设置为128,最终版为256,改为256可以避免很多问题,可以想想为什么?)
1、读写时钟改为200M(此时钟对应于写FIFO的时钟,也就是将上面的100M换为200M,ddr3核主时钟400M),突发长度8(可预知结果出现连续两个周期数据相同),写入数据位宽128,读取位宽128,抓取结果与预测结果相同
2、读写时钟改为100M,突发长度4(可预知结果不会出现连续两个周期数据相同),写入数据位宽128,读取位宽128,抓取结果与预测结果相同,看来如果不修改写入位宽时,突发长度改为4也是一种策略
下面对上面两种情况进行具体分析:
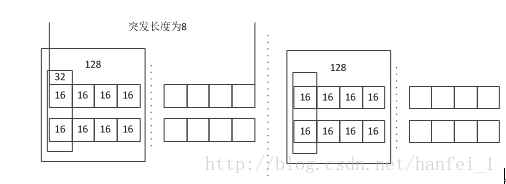
现象一:此平台选用的DDR3单片为16位,硬件设计时是将两片并联,见下图
由于写入的数据为128位,所以如上图,我们写入的只是一个大方框的数据,其实为何后面没有写入数据的部分又保留了前128位数据的值,这和写入数据的FIFO的写使能有关,下面再介绍(先知道此时突发长度为8时前128与后128都写入相同的数据),接着上面分析,而我们下面现象2时,我们将突发长度改为了4,就可以实现读出来的数据是一个地址对应一个数据,这是为啥?因为,我们虽然突发长度为4,但是我们程序中地址依旧加的是8,所以结果就是地址加8,我们写入4个地址的数据(读也一样),当然我们读的时候就像抽取一样,两个里抽一个(毕竟两个数据是一样的),那这样虽然输出的结果是一样的,也是正确的,但是这样就完了吗?再接着想,这样一来,我们就相当于浪费了一半的存储空间!!!!!!你写入了一半的废物数据,这样在实际中是不能容忍的!所以我们要做到的就是将128位数据挨个存储,不要有重复,避免浪费存储空间,虽然改突发长度可以得到正确结果,但是代价是显然的!
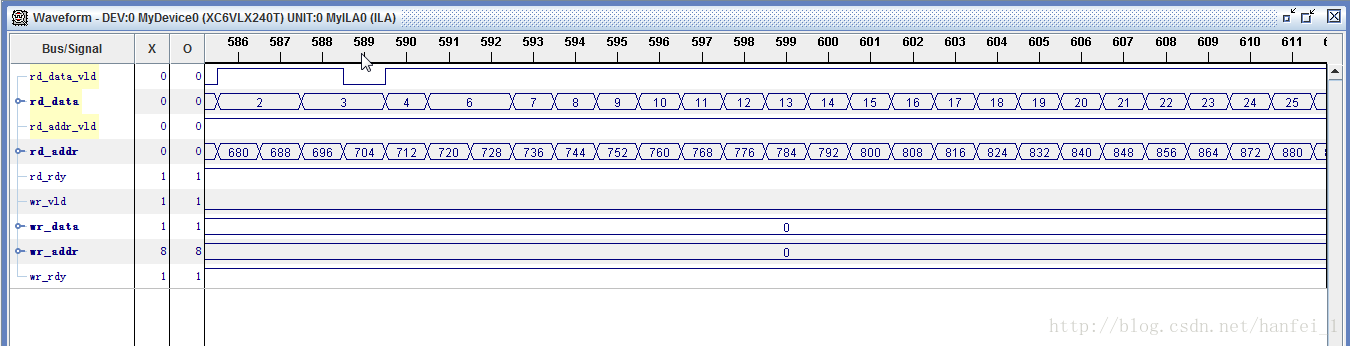
前面我提了一下,出现重复数据是因为写数据FIFO的读使能存在问题,下面着重解决,首先看两个图,上图是正确的软仿结果,下图是导致两个重复数据的错误结果。
正确的读使能应该一直为1,而下图中读使能呈脉冲式变化,在读使能为0时就导致数据保持了上一周期的数据,这便是根本原因,既然分析出原因就要修改程序了。
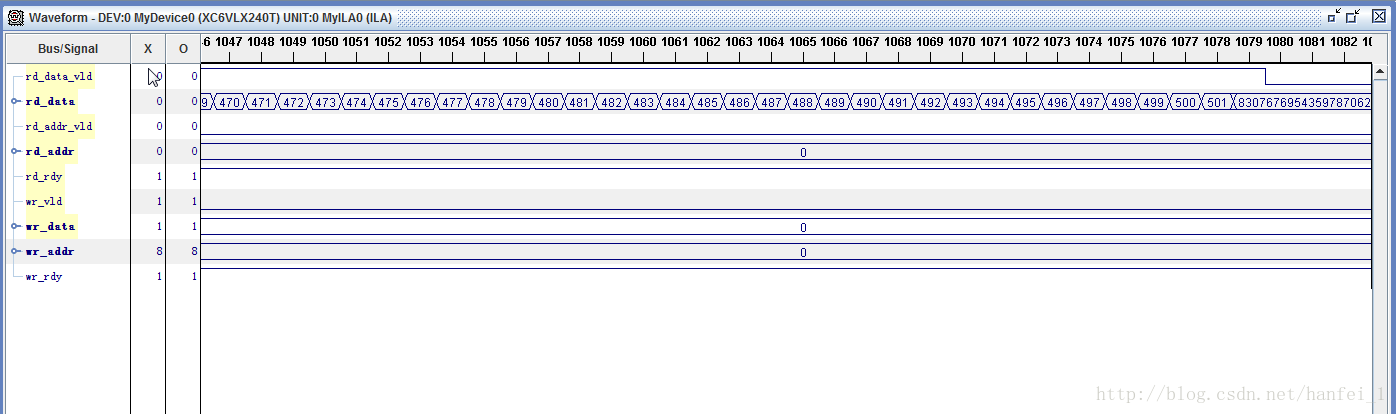
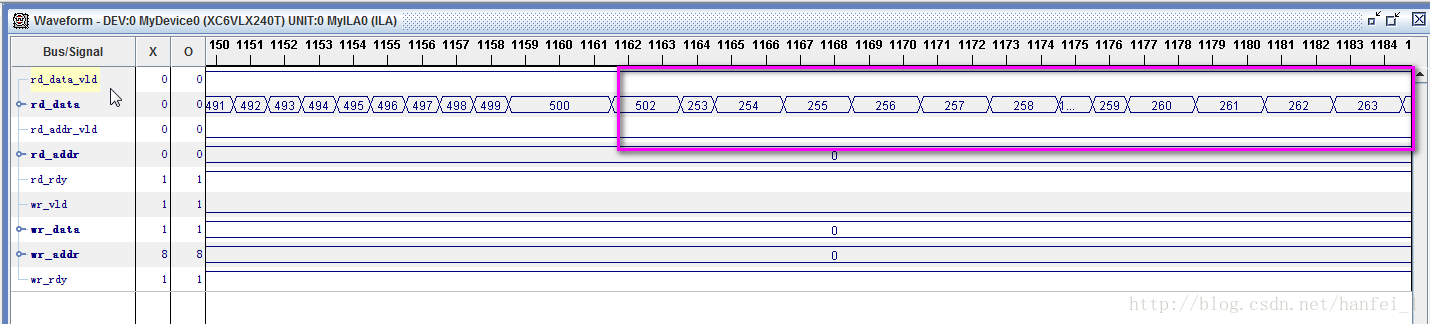
上面中为使app_wdf_wren和wr_dfifo_ren同步特意进行添加,如此解决了连续两个周期相同数据的问题。但是又出现问题了,给你张图看下
按道理说写到502就结束了,后面的哪里来的呢?
还记得我之前说过读数据的地址也是加到4000时结束读操作,程序中写的是数据每加一,地址加8,则默认的是8个地址对应一个数据,但是自己进行的是地址加8,对应写入的是2个数据,所以,对于写入数据来说,地址虽加到了4000多,但是实际中数据仅仅写到前2000个地址,而读数据时,却读出来的是4000个地址,但是只有前2000个地址数据是正确的,后面地址的数据还是保存的以前写入的错误数据(相邻两个周期数据相同),所以会出现上面的情况,所以将读地址改为原来的一半就可以了!
最后一个问题就是对于读写FIFO的时钟和位宽最好匹配下,差距不要过大,当然这要取决与你的程序。
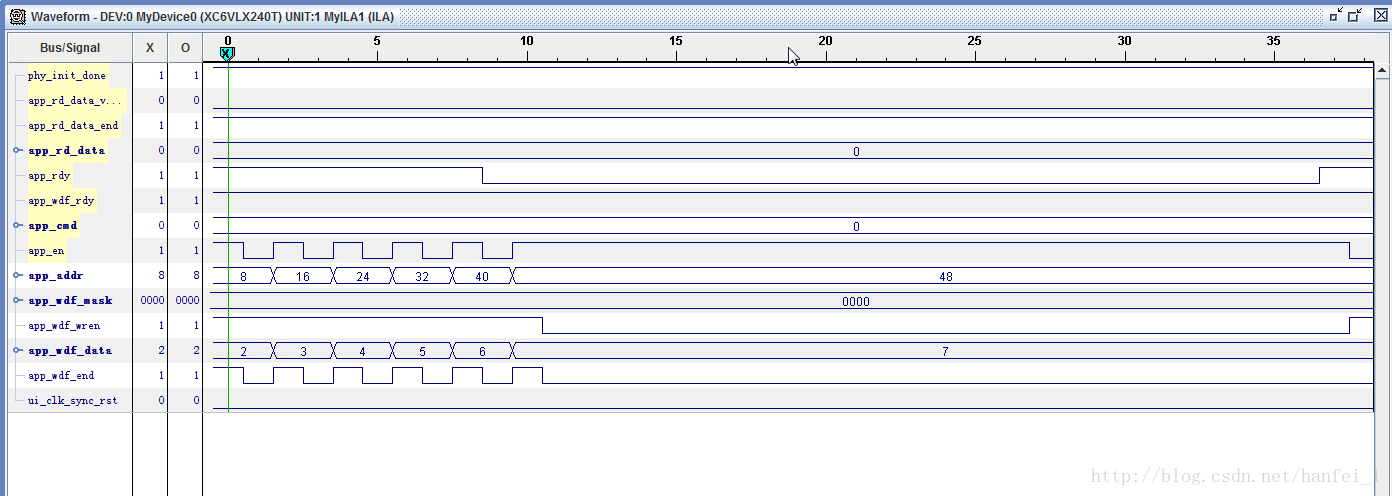
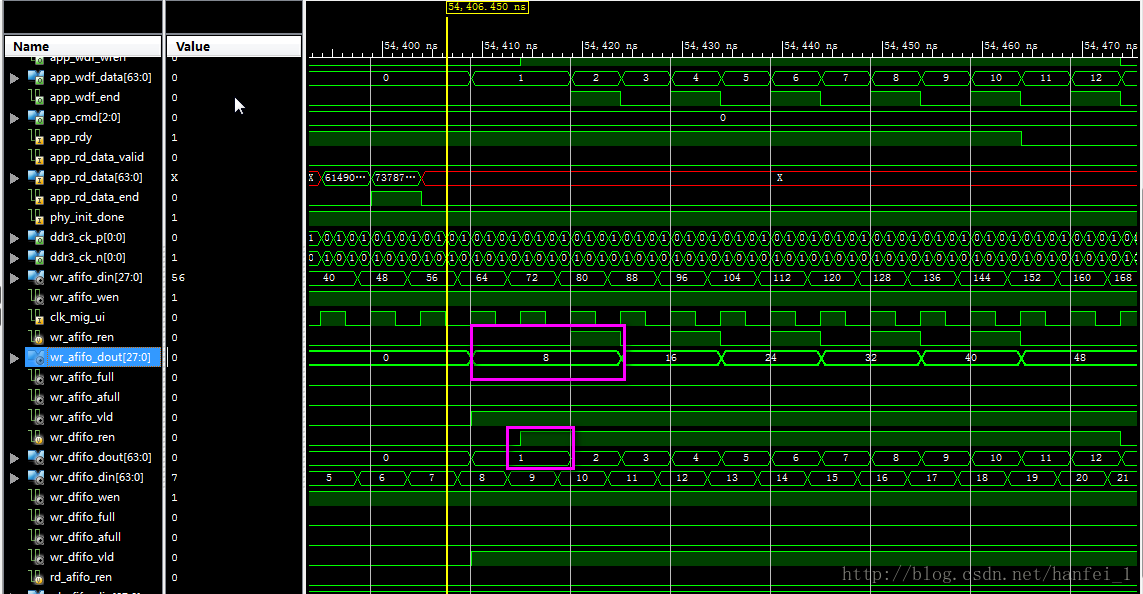
好啦,下面给你最一开始参数的仿真图。
将用户输入输出数据位宽256,写入时钟100M,app_wdf_data为128,突发长度为8,读出的数据满足要求,但是开头存在些许问题,但其余无问题,下面为仿真结果,开头数据存在些许问题,懒得调了,也就放在这了,数据往后打几拍应该可以解决问题,嘿嘿
好啦,打字好累啦,希望这篇文章能对初学者有所帮助,也希望大神们能多多批评指正,先谢过了,大家可以互相交流,觉得有用,大家就点个赞!我也正在调试一些接口,如果效果好,题主还会继续更新的,敬请期待!
标签:原来 例子 时钟周期 访问 是你 产生 完整性 实用 应用
原文地址:https://www.cnblogs.com/lionsde/p/9383365.html