标签:存在 比较 中序 后序 空间 最大值 示例 text deque
1. 树到二叉树的转换思考:通用树结构的实现太过复杂(树中每个结点都可以有任意多的孩子,具有多种形态),工程中很少会用到如此复杂的树是否可以简化呢?
思路:减少树结点中孩子的数量。但这样树是否还能通用呢?
双亲孩子表示法: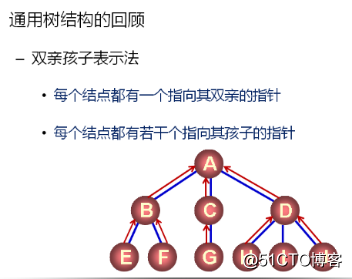
孩子兄弟表示法: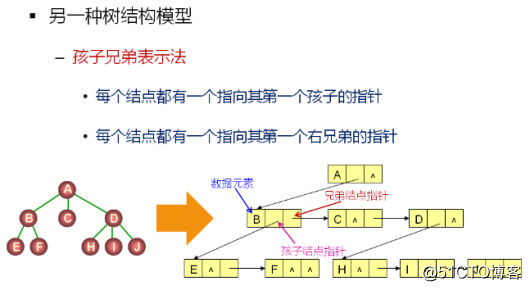
孩子兄弟表示法的特点:
1.能够表示任意的树形结构
2.每个结点包含一个数据成员和两个指针成员
3.孩子结点指针和兄弟结点指针构成“树杈”
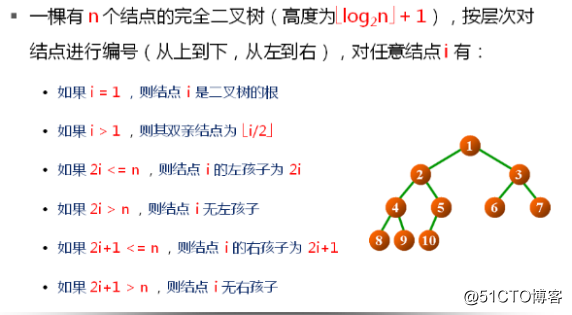
二叉树是由n(n>=0)个节点组成的有限集合,该集合或者为空,或者是由一个根结点加上两颗分别称为左子树和右子树的、互不相交的二叉树组成。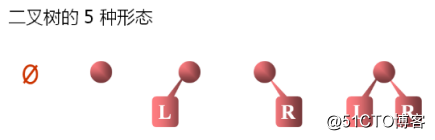
满二叉树:
如果二叉树中所有分支结点的度数都为2,且叶子结点都在同一层次上,则称这类二叉树为满二叉树。
完全二叉树:
如果一棵具有N个结点高度为K的二叉树,它的每一个结点与高度为K的满二叉树中编号1~n的结点一一对应,则称这颗二叉树为完全二叉树。(从上到下,从左到右编号)。
完全二叉树的特性:
同样结点的二叉树,完全二叉树的高度最小;完全二叉树的叶结点一定出现在最下面两层。
1.最底层的叶结点一定出现在左边;
2.倒数第二层的叶结点一定出现在右边;
3.完全二叉树中度数为1的结点只有左孩子。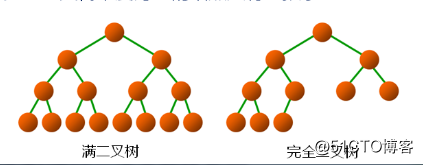
总结:
1.通用树结构采用了双亲结点表示法进行描述;
2.孩子兄弟表示法也有能力描述任意类型的树结构;
3.孩子兄弟表示法能够将通用树转化为二叉树(最多有两个孩子);
1.在二叉树的第i层最多有2^(i-1)个结点(i>=1);
2.高度为K的二叉树最多有2^k - 1个结点(K>=0);
3.对于任何一颗二叉树,如果其叶结点有n0个,度为2的非叶结点有n2个,则有n0 = n2 + 1;
推导证明:
n1 + 2n2 = n-1 ==> n1 + 2n2 = n0 + n1 + n2 - 1 ==> n0 = n2 + 1
4.具有n个结点的完全二叉树的告诉为【log2N】 + 1 (【x】表示不大于x的最大整数)
5.
目标:完成二叉树和二叉树结点的存储设计;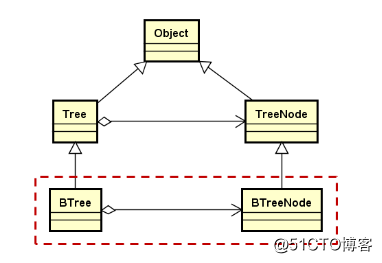
设计要点:
1.BTree为二叉树,每个结点最多只有两个后继结点;
2.BTreeNode只包含4个固有的公有成员:(数据成员、指向左孩子和右孩子的指针、指向父节点的指针)
BTreeNode的设计
直接继承自抽象树结点,使用工厂模式(标识使用的堆空间,方便使用智能指针进行释放)。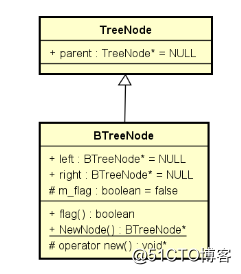
template < typename T >
class BTreeNode : public TreeNode<T>
{
public:
BTreeNode<T>* left;
BTreeNode<T>* right;
static BTreeNode<T>* NewNode()
{
BTreeNode<T>* ret = new BTreeNode<T>();
if(ret != NULL)
{
ret->m_flag = true; //在堆空间中申请了结点,则将该标识置为true
}
return ret;
}
~BTreeNode(){}
};BTree的设计
继承自抽象树结构,并组合使用BTreeNode.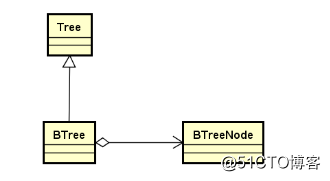
template < typename T >
class BTree : public Tree<T>
{
};二叉树的实现架构:

1.基于数据元素值的查找:
BTreeNode<T>* find(const T& value) const
virtual BTreeNode<T>* find(BTreeNode<T>* node, const T& value) const
{
BTreeNode<T>* ret = NULL;
if(node != NULL) // 判断是否为空树
{
if(node->value == value) //比较根结点
{
ret = node;
}
else
{
if(ret == NULL)
{
//递归查找左子树
ret = find(node->m_left, value);
}
if(ret == NULL)
{
//递归查找右子树
ret = find(node->m_right, value);
}
}
}
return ret;
}
BTreeNode<T>* find(const T& value) const
{
return find(root(), value);
}2.基于结点的查找:
BTreeNode<T> find(TreeNode<T> node) const
virtual BTreeNode<T>* find(BTreeNode<T>* node, BTreeNode<T>* obj) const
{
BTreeNode<T>* ret = NULL;
if(node != NULL) // 判断是否为空树
{
if(node == obj) //比较根结点
{
ret = node;
}
else
{
if(ret == NULL)
{
//递归查找左子树
ret = find(node->m_left, obj);
}
if(ret == NULL)
{
//递归查找右子树
ret = find(node->m_right, obj);
}
}
}
return ret;
}
BTreeNode<T>* find(TreeNode<T>* node) const
{
return find(root(), dynamic_cast<BTreeNode<T>*>(node));
}思考:是否能在二叉树的任意结点处插入子结点?
因为二叉树的定义中,每个结点最多只能有两个子结点,所以必然不能在任意结点处插入,因此需要制定新的数据元素(新结点)的插入位置。
二叉树结点的位置定义:
enum BTreeNodePos
{
ANY,
LEFT,
RIGHT
};

1.定义功能函数,指定位置的结点插入:virtual bool insert(BTreeNode<T>* newnode, BTreeNode<T>* node, BTNodePos pos)
virtual bool insert(BTreeNode<T>* n, BTreeNode<T>* np, BTreeNodePos pos)
{
bool ret = true;
//指定的插入位置为ANY(没有指定插入位置)
if(pos == ANY)
{
if(np->m_left == NULL) // 左子树结点为空,插入到左子树
{
np->m_left = n;
}
else if(np->m_right == NULL) // ...
{
np->m_right = n;
}
else
{
ret = false;
}
}
// 指定插入到左孩子结点
if(pos == LEFT)
{
if(np->m_left == NULL)
{
np->m_left = n;
}
else
{
ret = false;
}
}
// 指定插入到右孩子结点
if(pos == RIGHT)
{
if(np->m_right == NULL)
{
np->m_right = n;
}
else
{
ret = false;
}
}
return ret;
}2.插入新结点
bool insert(TreeNode<T>* node, BTreeNodePos pos)
bool insert(TreeNode<T>* node)
//插入结点,并指定位置
bool insert(TreeNode<T>* node, BTreeNodePos pos)
{
bool ret = true;
if(node != NULL)
{
if(root() == NULL) //判断根结点处是否可以插入
{
node->m_parent = NULL;
this->m_root = node;
}
else
{
BTreeNode<T>* np = find(node->m_parent); //查找父节点是否存在
if(np != NULL)
{
// 调用二叉树插入操作功能函数
ret = insert(dynamic_cast<BTreeNode<T>*>(node), np, pos);
}
else
{
THROW_EXCEPTION(InvaildParameterException, "invalid parent tree node...");
}
}
}
else
{
THROW_EXCEPTION(InvaildParameterException, "param con‘t be NULL...");
}
return ret;
}
//插入结点,无位置要求
bool insert(TreeNode<T>* node)
{
return insert(node, ANY);
}3.插入数据元素
bool insert(const T& value,TreeNode<T>* parent, BTreeNodePos pos)
bool insert(const T& value,TreeNode<T>* parent)
//插入数据元素,指定位置
bool insert(const T& value,TreeNode<T>* parent, BTreeNodePos pos)
{
bool ret = true;
BTreeNode<T>* node = BTreeNode<T>::NewNode();
if(node != NULL)
{
node->value = value;
node->m_parent = parent;
insert(node, pos);
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "no memory to create new tree node...");
}
return ret;
}
bool insert(const T& value,TreeNode<T>* parent)
{
return insert(value, parent, ANY);
}测试技巧:从叶结点到根结点为线性数据结构,可以使用链表的遍历方式。
总结:
1.二叉树的插入操作需要指明插入的位置;
2.插入操作必须正确处理指向父节点的指针
3.插入数据元素时需要从堆空间中创建结点,让数据元素插入失败时,需要释放结点空间。

1.删除操作功能定义
void remove(BTreeNode<T> node, BTree<T>& ret)
将node为根结点的子树从原来的二叉树中删除,ret作为子树返回(ret指向堆空间中的二叉树对象)
virtual void remove(BTreeNode<T>* node, BTree<T>*& ret)
{
ret = new BTree();
if(ret != NULL)
{
if(root() == node)
{
this->m_root = NULL;
}
else
{
BTreeNode<T>* np = dynamic_cast<BTreeNode<T>*>(node->m_parent);
if(np->m_left == node)
{
np->m_left = NULL;
}
else if(np->m_right == node)
{
np->m_right = NULL;
}
node->m_parent = NULL;
}
ret->m_root = node;
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "no memory to create new tree...");
}
}
2.基于数据元素的删除
SharedPointer< Tree<T> > remove(const T& value)
SharedPointer< Tree<T> > remove(const T& value)
{
BTree<T>* ret = NULL;
BTreeNode<T>* node = find(value);
if(node != NULL)
{
remove(node, ret);
m_queue.clear();
}
return ret;
}3.基于结点的删除
SharedPointer< Tree<T> > remove(TreeNode<T>* node)
SharedPointer< Tree<T> > remove(TreeNode<T>* node)
{
BTree<T>* ret = NULL;
node = find(node);
if(node != NULL)
{
remove(dynamic_cast<BTreeNode<T>*>(node), ret);
m_queue.clear();
}
return ret;
}
测试技巧:直接打印已经删除的子树。
总结:
删除操作将目标界定啊所在的子树移除,必须完善处理父子结点的关系
void clear() // 将二叉树中的所有节点清除(释放堆中的结点)
1.清除操作功能定义
free(node) // 清除node为根结点的二叉树,释放二叉树中的每个结点
// 清空树的功能函数定义
void free(BTreeNode<T>* node)
{
if(node != NULL)
{
free(node->m_left);
free(node->m_right);
//cout << node->value << endl;
if(node->flag())
{
delete node;
}
}
}
void clear()
{
free(root());
this->m_root = NULL;
}测试技巧:可以在free函数中打印删除的每一个结点
总结:
清除操作用于销毁树中的每个结点,销毁时要判断是否释放对应的内存空间(工厂模式)。

定义功能函数:cout(node) // 在node为根结点的二叉树中递归统计结点数目
// 获取树的结点个数,递归实现
int count(BTreeNode<T>* node) const
{
int ret = 0;
if(node != NULL)
{
// 左子树的结点个数 + 右子树的结点个数 + 1(根结点)
ret = count(node->m_left) + count(node->m_right) + 1;
}
return ret;
}
int count() const
{
return count(root());
}定义功能函数:height(node) // 递归获取node为根结点的二叉树的高度
// 获取树的结点个数,递归实现
int height(BTreeNode<T>* node) const
{
int ret = 0;
if(node != NULL)
{
int hl = height(node->m_left);
int hr = height(node->m_right);
// 左右子树高度的最大值 + 1(根结点)
ret = ((hl > hr) ? hl : hr) + 1;
}
return ret;
}
int height() const
{
return height(root());
}定义功能函数:degree(node) // 获取node为根结点的二叉树的度数
// 获取二叉树的度,递归实现
int degree(BTreeNode<T>* node) const
{
int ret = 0;
if(node != NULL)
{
/*
// 普通思路
int dl = degree(node->m_left); // 左子树的度
int dr = degree(node->m_right); // 右子树的度
ret = !!node->m_left + !!node->m_right; //根结点的度
if(dl > ret)
{
ret = dl;
}
else if(dr > ret)
{
ret = dr;
}
*/
/*
* 优化效率,二叉树的最大度数为2,如果ret已经为2,则不需要继续遍历
ret = !!node->m_left + !!node->m_right; //根结点的度
if(ret < 2)
{
int dl = degree(node->m_left); // 左子树的度
if(dl > ret)
{
ret = dl;
}
}
if(ret < 2)
{
int dr = degree(node->m_right); // 左子树的度
if(dr > ret)
{
ret = dr;
}
}
*/
// 优化冗余代码
ret = !!node->m_left + !!node->m_right; //根结点的度
BTreeNode<T>* child[] = {node->m_left, node->m_right};
for(int i=0; i<2 && ret<2; i++)
{
int d = degree(child[i]);
if(d > ret)
{
ret = d;
}
}
}
return ret;
}
int degree() const
{
return degree(root());
}二叉树的遍历是指从根结点出发,按照某种次序依次访问二叉树中的所有节点,使得每个结点被访问一次。
思考:通用树结构的层次遍历算法是否可以用在二叉树结构上?如果可以需要做什么改动?
不同之处在于二叉树最多只有两个孩子。
设计思路:
在树中定义一个新游标(BTreeNode<T>*),遍历开始将游标指向根结点(root()),获取游标指向的数据元素,通过结点中的child成员移动游标;
提供一组遍历相关的函数,按层次访问树中的数据元素。
层次遍历算法:
原料:class LinkQueue<T>; 游标:LinkQueue<T>::front();
思想:
end() 判断队列是否为空
bool begin()
{
bool ret = (root() != NULL);
if(ret)
{
m_queue.clear();
m_queue.enqueue(root()); //把根结点压入队里
}
return ret;
}
bool end()
{
return (m_queue.length() == 0);
}
bool next()
{
bool ret = (m_queue.length() > 0);
if(ret)
{
BTreeNode<T>* node = m_queue.front();
m_queue.dequeue();
// 二叉树的左右孩子入队列
if(node->m_left != NULL)
{
m_queue.enqueue(node->m_left);
}
if(node->m_right != NULL)
{
m_queue.enqueue(node->m_right);
}
}
return ret;
}
// 获取游标所执行的元素
T current()
{
if(!end())
{
return m_queue.front()->value;
}
else
{
THROW_EXCEPTION(InvalidOperationException, "invalid operation ...");
}
}使用示例:
for(bt.begin(); !bt.end(); bt.next())
{
cout << bt.current() << " ";
}
问题:二叉树是否只有一种遍历方式(层次遍历)?
典型的二叉树遍历方式:
这里的先序、后序、中序指的的根结点的访问次序
1.先序遍历(Pre-Order Traversal)
// 先序遍历
void PreOrderTraversal(BTreeNode<T>* node, LinkQueue<BTreeNode<T>*>& queue)
{
if(node != NULL)
{
queue.enqueue(node);
PreOrderTraversal(node->m_left, queue);
PreOrderTraversal(node->m_right, queue);
}
}2.中序遍历(In-Order TRaversal)
// 中序遍历
void InOrderTraversal(BTreeNode<T>* node, LinkQueue<BTreeNode<T>*>& queue)
{
if(node != NULL)
{
InOrderTraversal(node->m_left, queue);
queue.enqueue(node);
InOrderTraversal(node->m_right, queue);
}
}3.后续遍历(Post-Order Traversal)
// 后序遍历
void PostOrderTraversal(BTreeNode<T>* node, LinkQueue<BTreeNode<T>*>& queue)
{
if(node != NULL)
{
PostOrderTraversal(node->m_left, queue);
PostOrderTraversal(node->m_right, queue);
queue.enqueue(node);
}
}4.层次遍历(LevelOrder- Traversal)
// 层次遍历
void LevelOrderTraversal(BTreeNode<T>* node,LinkQueue<BTreeNode<T>*>& queue)
{
if(node != NULL)
{
LinkQueue<BTreeNode<T>*> tmp; // 定义辅助队列
tmp.enqueue(node); // 根结点入队列
while(tmp.length()>0) // end
{
BTreeNode<T>* n = tmp.front();
if(n->m_left != NULL)
{
tmp.enqueue(n->m_left);
}
if(n->m_right != NULL)
{
tmp.enqueue(n->m_right);
}
tmp.dequeue(); //队头元素出队列,并存入输出队列
queue.enqueue(n);
}
}
}思考:是否可以将二叉树的典型遍历方式算法集成到BTree中,如果可以,代码需要做怎样的改动?
设计要点:
1.不能与层次遍历函数冲突,必须设计新的函数接口
2.算法执行完成后,能够方便的获得遍历结果,遍历结果能反映结点访问的先后次序
函数接口设计:
SharedPoiner<Array<T>> traversal(BTTraversal order)
1.根据参数order选择执行遍历算法(先序、中序、后序)
2.返回值为堆中的数组对象(生命周期由智能指针管理)
3.数据元素的次序反映遍历的先后次序
void traversal(BTTraversal order,LinkQueue<BTreeNode<T>*>& queue)
{
switch (order)
{
case PreOrder:
PreOrderTraversal(root(),queue);
break;
case InOrder:
InOrderTraversal(root(),queue);
break;
case PostOrder:
PostOrderTraversal(root(),queue);
break;
case LevelOrder:
LevelOrderTraversal(root(),queue);
break;
default:
THROW_EXCEPTION(InvaildParameterException,"Parameter order is invalid ...");
break;
}
}
SharedPointer<Array<T>> traversal(BTTraversal order)
{
DynamicArray<T>* ret = NULL;
LinkQueue<BTreeNode<T>*> queue; //保存执行二叉树结点的指针
traversal(order, queue);
ret = new DynamicArray<T>(queue.length());
if(ret != NULL)
{
for(int i=0; i<ret->length(); i++,queue.dequeue())
{
//cout << queue.front()->value << endl;
ret->set(i, queue.front()->value);
}
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "no memory to create dynamic array...");
}
return ret;
}典型遍历示例:
SharedPointer<Array<int>> sp = NULL;
sp = bt.traversal(PostOder);
for(int i=0; i<(*sp).length(); i++)
{
cout << (*sp)[i] << " ";
}总结:
1.二叉树的典型遍历都是以递归方式进行的;
2.BTree以不同的函数接口支持典型遍历,防止与层次遍历冲突;
克隆当前树的一份拷贝,返回值为堆空间中的一颗新树(与当前树相等)。
SharedPointer<BTree<T>> clone() const
功能函数定义:clone(node)
递归克隆node为根结点的二叉树(数据元素在对应位置相等)
BTreeNode<T>* clone(BTreeNode<T>* node) const
{
BTreeNode<T>* ret = NULL;
if(node != NULL)
{
ret = BTreeNode<T>::NewNode();
if(ret != NULL)
{
ret->value = node->value; // 克隆根结点
ret->m_left = clone(node->m_left); //递归克隆左子树
ret->m_right = clone(node->m_right); //递归克隆右子树
//连接父子关系
if(ret->m_left != NULL)
{
ret->m_left->m_parent = ret;
}
if(ret->m_right != NULL)
{
ret->m_right->m_parent = ret;
}
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "no memory to create new tree node...");
}
}
return ret;
}
SharedPointer<BTree<T>> clone() const
{
BTree<T>* ret = new BTree();
if(ret != NULL)
{
ret->m_root = clone(root());
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "no memory to create new tree...");
}
return ret;
}判断两颗二叉树中的数据元素是否对应相等:
bool operater == (const BTree<T>& btree)
bool operater == (const BTree<T>& btree)
功能函数定义:equal(lh, rh)
递归判断lh为根结点的二叉树和rh为根结点的二叉树是否相等。
bool equal(BTreeNode<T>* lh, BTreeNode<T>* rh)
{
bool ret = true;
if(lh == rh) // 自比较或者两棵树都为空
{
ret = true;
}
else if((lh != NULL) && (rh != NULL)) //参与比较的两棵树都不为空
{
// 递归比较根结点、左子树、右子树
ret = ((lh->value == rh->value) && (equal(lh->m_left, rh->m_left)) && equal(lh->m_right, rh->m_right));
}
else // 两棵树中有一颗为空
{
ret = false;
}
return ret;
}
bool operator == (const BTree<T>& btree)
{
return equal(root(), btree.root());
}
bool operator != (const BTree<T>& btree)
{
return !(*this == btree);
}将当前二叉树与参数btree中的数据元素在对应的位置处相加,返回值(相加的结果)为堆空间中的一颗新二叉树。
SharedPointer<BTree<T>> add(const BTree<T>& btree) const
二叉树相加操作功能函数定义:add(lh, rh),将lh为根节点的二叉树与rh为根结点的二叉树相加。
BTreeNode<T>* add(BTreeNode<T>* lh, BTreeNode<T>* rh) const
{
BTreeNode<T>* ret = NULL;
if((lh != NULL) && (rh == NULL)) // 二叉树lh不为空
{
ret = clone(lh);
}
if((lh == NULL) && (rh != NULL)) // 二叉树rh不为空
{
ret = clone(rh);
}
if((lh != NULL) && (rh != NULL)) // 二叉树都不为空
{
ret = BTreeNode<T>::NewNode();
if(ret != NULL)
{
ret->value = lh->value + rh->value; // 根结点相加
ret->m_left = add(lh->m_left, rh->m_left); // 左子树递归相加
ret->m_right = add(lh->m_right, rh->m_right); // 右子树递归相加
//连接父子关系
if(ret->m_left != NULL)
{
ret->m_left->m_parent = ret;
}
if(ret->m_right != NULL)
{
ret->m_right->m_parent = ret;
}
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "no memory to create new tree node...");
}
}
return ret;
}
SharedPointer<BTree<T>> add(const BTree<T>& btree) const
{
BTree<T>* ret = new BTree();
if(ret != NULL)
{
ret->m_root = add(root(), btree.root());
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "no memory to create new node...");
}
return ret;
}1.什么是线索化二叉树?
将二叉树转换为双向链表的过程(非线性-->线性)的过程称为线索化。
能够反映某种二叉树的遍历次序(结点的先后访问次序)
技巧:利用结点的right指针指向遍历中的后继结点,left指针指向前驱结点。
为什么要要进行线索化?
二叉树的遍历操作都采用递归进行(比较低效),如果需要经常遍历,将二叉树进行线索化后作为双向链表存在,后续直接访问双向链表将提高效率。
2.如何对二叉树进行线索化?
使用某种遍历算法对二叉树进行遍历,在遍历的同时将遍历顺序存储到队列,然后使用left和right指针连接队列中的结点。
3.目标
新增共有函数BTreeNode<T>* thread(BTTraversal order)
4.层次遍历实现
(1)将根结点压入队列
(2)访问队头元素指向的二叉树结点
(3)队头元素弹出,将队头元素的孩子压入队列
(4)判断队列是否为空(非空:执行2,空:结束)

// 层次遍历
void LevelOrderTraversal(BTreeNode<T>* node,LinkQueue<BTreeNode<T>*>& queue)
{
if(node != NULL)
{
LinkQueue<BTreeNode<T>*> tmp; // 定义辅助队列
tmp.enqueue(node); // 根结点入队列
while(tmp.length()>0) // end
{
BTreeNode<T>* n = tmp.front();
if(n->m_left != NULL)
{
tmp.enqueue(n->m_left);
}
if(n->m_right != NULL)
{
tmp.enqueue(n->m_right);
}
tmp.dequeue(); //队头元素出队列,并存入输出队列
queue.enqueue(n);
}
}
}5.线索化实现
函数接口:BTreeNode<T>* thread(BTTraversal order)
(1)根据参数order选择线索化的次序(先序、中序、后续、层次)
(2)连接线索化后的结点;
(3)返回线索化后指向链表首节点的指针,并将对应的二叉树变为空树
6.队列中结点的连接
slider的right指针指向新的队列头部元素,队头元素的left指针指向slider,slider记录队头元素,队头元素出队列。
void traversal(BTTraversal order,LinkQueue<BTreeNode<T>*>& queue)
{
switch (order)
{
case PreOrder:
PreOrderTraversal(root(),queue);
break;
case InOrder:
InOrderTraversal(root(),queue);
break;
case PostOrder:
PostOrderTraversal(root(),queue);
break;
case LevelOrder:
LevelOrderTraversal(root(),queue);
break;
default:
THROW_EXCEPTION(InvaildParameterException,"Parameter order is invalid ...");
break;
}
}
BTreeNode<T>* connect(LinkQueue<BTreeNode<T>*>& queue)
{
BTreeNode<T>* ret = NULL;
if(queue.length() > 0)
{
//返回队列的队头元素指向的结点作为双向链表的首结点
ret = queue.front();
//创建一个游标结点,指向队列队头
BTreeNode<T>* slider = queue.front();
//将队头元素出队
queue.dequeue();
//双向链表的首结点的前驱设置为空
ret->m_left = NULL;
while(queue.length() > 0)
{
//当前游标结点的后继指向队头元素
slider->m_right = queue.front();
//当前队头元素的前驱指向当前游标结点
queue.front()->m_left = slider;
//将当前游标结点移动到队头元素
slider = queue.front();
//将当前队头元素出队,继续处理新的队头元素
queue.dequeue();
}
//双向链表的尾结点的后继为空
slider->m_right = NULL;
}
return ret;
}
BTreeNode<T>* thread(BTTraversal order)
{
BTreeNode<T>* ret = NULL;
LinkQueue<BTreeNode<T>*> queue;
traversal(order, queue); //遍历二叉树,并按遍历次序将结点保存到队列
ret = connect(queue); //连接队列中的结点成为双向链表
this->m_root = NULL; //将二叉树的根节点置空
m_queue.clear(); //将游标遍历的辅助队列清空
//返回双向链表的首结点
return ret;
}总结:
1.线索化是将二叉树转化为双向链表的过程,线索华后结点间的先后次序符合某种遍历次序;
2.线索化将破坏原二叉树间的父子关系,同时线索化后二叉树将不再管理结点中的生命周期(二叉树已经不存在,只有双向链表)。
要求:编写一个函数用于删除二叉树中的所欲单度结点,结点删除后,其唯一的子结点代替它的位置
定义功能函数:delOdde(node) // 递归删除node为根结点的二叉树中的单度结点
定义功能函数:delOdde(node) // 递归删除node为根结点的二叉树中的单度结点,其中node为结点指针的引用
要求:编写一个函数用于中序线索化二叉树,不能使用其他的数据结构。
在中序遍历的同时进行线索化
思路:使用辅助指针,在中序遍历时指向当前结点的前驱结点,访问当前结点时,连接与前驱结点的先后次序。
定义功能函数:inOrderThread(node,pre),其中node为根结点,也是中序遍历访问的结点,pre为中序遍历时的前驱结点指针。
中序遍历的结点正好是结点的水平次序
思路:
1.使用辅助指针,指向转换后双向链表的头节点和尾节点;
2.根结点与左右子树转为的双向链表连接,称为完整双向链表。
定义功能函数:inOrderThread(node, head, tail):
Node为根结点,也是中序遍历的访问结点,head转后成功后指向双向链表的首节点,tail转换成功后指向双向链表的尾节点。
标签:存在 比较 中序 后序 空间 最大值 示例 text deque
原文地址:http://blog.51cto.com/11134889/2151760