标签:cin 模拟 遇到 tin 译文 erase region poi 方案
为了准备一个独特的颁奖典礼,组织者在会场的一片矩形区域(可看做是平面直角坐标系的第一象限)铺上一些矩形地毯。一共有 nn 张地毯,编号从 11 到 nn 。现在将这些地毯按照编号从小到大的顺序平行于坐标轴先后铺设,后铺的地毯覆盖在前面已经铺好的地毯之上。
地毯铺设完成后,组织者想知道覆盖地面某个点的最上面的那张地毯的编号。注意:在矩形地毯边界和四个顶点上的点也算被地毯覆盖。
输入格式:
输入共 n+2n+2 行
第一行,一个整数 nn ,表示总共有 nn 张地毯
接下来的 nn 行中,第 i+1i+1 行表示编号 ii 的地毯的信息,包含四个正整数 a ,b ,g ,ka,b,g,k ,每两个整数之间用一个空格隔开,分别表示铺设地毯的左下角的坐标 (a,b)(a,b) 以及地毯在 xx 轴和 yy 轴方向的长度
第 n+2n+2 行包含两个正整数 xx 和 yy ,表示所求的地面的点的坐标 (x,y)(x,y)
输出格式:
输出共 11 行,一个整数,表示所求的地毯的编号;若此处没有被地毯覆盖则输出 -1?1
【样例解释1】
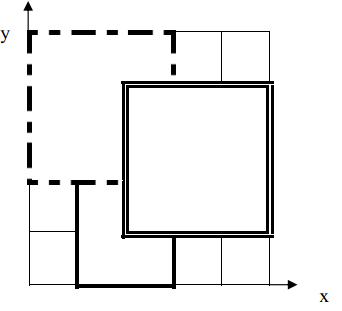
如下图, 11 号地毯用实线表示, 22 号地毯用虚线表示, 33 号用双实线表示,覆盖点 (2,2)(2,2) 的最上面一张地毯是 33号地毯。
【数据范围】
对于30% 的数据,有 n ≤2n≤2 ;
对于50% 的数据, 0 ≤a, b, g, k≤1000≤a,b,g,k≤100 ;
对于100%的数据,有 0 ≤n ≤10,0000≤n≤10,000 , 0≤a, b, g, k ≤100,0000≤a,b,g,k≤100,000 。
noip2011提高组day1第1题
1 #include<bits/stdc++.h> 2 using namespace std; 3 struct p{ 4 int a,b,g,k; 5 }point[100005]; 6 int n; 7 int main(){ 8 scanf("%d",&n); 9 for(int i=0;i<n;i++){ 10 scanf("%d%d%d%d",&point[i].a,&point[i].b,&point[i].g,&point[i].k); 11 } 12 int x,y; 13 scanf("%d%d",&x,&y); 14 for(int i=n-1;i>=0;i--){ 15 if(x>=point[i].a&&x<=point[i].a+point[i].g&&y>=point[i].b&&y<=point[i].b+point[i].k){ 16 printf("%d\n",i+1); 17 return 0; 18 } 19 } 20 printf("-1\n"); 21 }
一元 nn 次多项式可用如下的表达式表示:
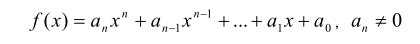
其中, a_i,x_iai?,xi? 称为 ii 次项, a_iai? 称为 ii 次项的系数。给出一个一元多项式各项的次数和系数,请按照如下规定的格式要求输出该多项式:
多项式中自变量为 xx ,从左到右按照次数递减顺序给出多项式。
多项式中只包含系数不为 00 的项。
如果多项式 nn 次项系数为正,则多项式开头不出现“ ++ ”号,如果多项式 nn 次项系
数为负,则多项式以“ -? ”号开头。
4. 对于不是最高次的项,以“ ++ ”号或者“ -? ”号连接此项与前一项,分别表示此项
系数为正或者系数为负。紧跟一个正整数,表示此项系数的绝对值(如果一个高于 00 次的项,
其系数的绝对值为 11 ,则无需输出 11 )。如果 xx 的指数大于 11 ,则接下来紧跟的指数部分的形
式为“ x^bxb ”,其中 bb 为 xx 的指数;如果 xx 的指数为 11 ,则接下来紧跟的指数部分形式为“ xx ”;
如果 xx 的指数为 00 ,则仅需输出系数即可。
5. 多项式中,多项式的开头、结尾不含多余的空格。
输入格式:
输入共有 22 行
第一行 11 个整数, nn ,表示一元多项式的次数。
第二行有 n+1n+1 个整数,其中第 ii 个整数表示第 n-i+1n?i+1 次项的系数,每两个整数之间用空格隔开。
输出格式:
输出共 11 行,按题目所述格式输出多项式。
NOIP 2009 普及组 第一题
对于100%数据, 0 \le n \le 1000≤n≤100 , -100 \le?100≤ 系数 \le 100≤100
1 #include<bits/stdc++.h> 2 using namespace std; 3 int main(){ 4 int n,a; 5 cin>>n; 6 for(int i=n;i>=0;i--){ 7 cin>>a; 8 if(a){ 9 if(i!=n&&a>0)cout<<"+"; 10 if(abs(a)>1||i==0)cout<<a; 11 if(a==-1&&i)cout<<"-"; 12 if(i>1)cout<<"x^"<<i; 13 if(i==1)cout<<"x"; 14 } 15 } 16 }
小晨的电脑上安装了一个机器翻译软件,他经常用这个软件来翻译英语文章。
这个翻译软件的原理很简单,它只是从头到尾,依次将每个英文单词用对应的中文含义来替换。对于每个英文单词,软件会先在内存中查找这个单词的中文含义,如果内存中有,软件就会用它进行翻译;如果内存中没有,软件就会在外存中的词典内查找,查出单词的中文含义然后翻译,并将这个单词和译义放入内存,以备后续的查找和翻译。
假设内存中有 MM 个单元,每单元能存放一个单词和译义。每当软件将一个新单词存入内存前,如果当前内存中已存入的单词数不超过 M-1M?1 ,软件会将新单词存入一个未使用的内存单元;若内存中已存入 MM 个单词,软件会清空最早进入内存的那个单词,腾出单元来,存放新单词。
假设一篇英语文章的长度为 NN 个单词。给定这篇待译文章,翻译软件需要去外存查找多少次词典?假设在翻译开始前,内存中没有任何单词。
输入格式:
共 22 行。每行中两个数之间用一个空格隔开。
第一行为两个正整数 M,NM,N ,代表内存容量和文章的长度。
第二行为 NN 个非负整数,按照文章的顺序,每个数(大小不超过 10001000 )代表一个英文单词。文章中两个单词是同一个单词,当且仅当它们对应的非负整数相同。
输出格式:
一个整数,为软件需要查词典的次数。
每个测试点 1s1s
对于 10\%10% 的数据有 M=1,N≤5M=1,N≤5 。
对于 100\%100% 的数据有 0≤M≤100,0≤N≤10000≤M≤100,0≤N≤1000 。
整个查字典过程如下:每行表示一个单词的翻译,冒号前为本次翻译后的内存状况:
空:内存初始状态为空。
1. 11 :查找单词1并调入内存。
2. 1 212 :查找单词 22 并调入内存。
3. 1 212 :在内存中找到单词 11 。
4. 1 2 5125 :查找单词 55 并调入内存。
5. 2 5 4254 :查找单词 44 并调入内存替代单词 11 。
6. 2 5 4254 :在内存中找到单词 44 。
7. 5 4 1541 :查找单词1并调入内存替代单词 22 。
共计查了 55 次词典。
1 #include<bits/stdc++.h> 2 using namespace std; 3 set<int> s; 4 queue<int> q; 5 int n,m,sum; 6 int main(){ 7 scanf("%d%d",&m,&n); 8 int sum=0; 9 for(int i=0;i<n;i++){ 10 int a; 11 scanf("%d",&a); 12 if(s.find(a)!=s.end()) continue; 13 if(q.size()<m){ 14 q.push(a); 15 s.insert(a); 16 sum++; 17 } 18 else{ 19 int t=q.front(); 20 s.erase(t); 21 q.pop(); 22 s.insert(a); 23 q.push(a); 24 sum++; 25 } 26 } 27 printf("%d\n",sum); 28 }
上课的时候总会有一些同学和前后左右的人交头接耳,这是令小学班主任十分头疼的一件事情。不过,班主任小雪发现了一些有趣的现象,当同学们的座次确定下来之后,只有有限的D对同学上课时会交头接耳。
同学们在教室中坐成了 MM 行 NN 列,坐在第i行第j列的同学的位置是 (i,j)(i,j) ,为了方便同学们进出,在教室中设置了 KK 条横向的通道, LL 条纵向的通道。
于是,聪明的小雪想到了一个办法,或许可以减少上课时学生交头接耳的问题:她打算重新摆放桌椅,改变同学们桌椅间通道的位置,因为如果一条通道隔开了 22 个会交头接耳的同学,那么他们就不会交头接耳了。
请你帮忙给小雪编写一个程序,给出最好的通道划分方案。在该方案下,上课时交头接耳的学生的对数最少。
输入格式:
第一行,有 55 个用空格隔开的整数,分别是 M,N,K,L,D(2 \le N,M \le 1000,0 \le K<M,0 \le L<N,D \le 2000)M,N,K,L,D(2≤N,M≤1000,0≤K<M,0≤L<N,D≤2000)
接下来的 DD 行,每行有 44 个用空格隔开的整数。第 ii 行的 44 个整数 X_i,Y_i,P_i,Q_iXi?,Yi?,Pi?,Qi? ,表示坐在位置 (X_i,Y_i)(Xi?,Yi?) 与 (P_i,Q_i)(Pi?,Qi?) 的两个同学会交头接耳(输入保证他们前后相邻或者左右相邻)。
输入数据保证最优方案的唯一性。
输出格式:
共两行。
第一行包含 KK 个整数 a_1,a_2,…,a_Ka1?,a2?,…,aK? ,表示第 a_1a1? 行和 a_1+1a1?+1 行之间、第 a-2a?2 行和 a_2+1a2?+1 行之间、…、第 a_KaK? 行和第 a_K+1aK?+1 行之间要开辟通道,其中 a_i< a_i+1ai?<ai?+1 ,每两个整数之间用空格隔开(行尾没有空格)。
第二行包含 LL 个整数 b_1,b_2,…,b_Lb1?,b2?,…,bL? ,表示第 b_1b1? 列和 b_1+1b1?+1 列之间、第 b_2b2? 列和 b_2+1b2?+1 列之间、…、第 b_LbL? 列和第 b_L+1bL?+1 列之间要开辟通道,其中 b_i< b_i+1bi?<bi?+1 ,每两个整数之间用空格隔开(列尾没有空格)。
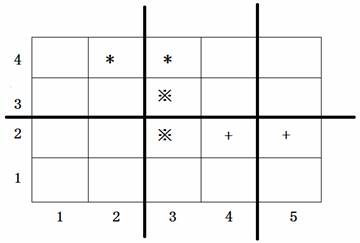
上图中用符号*、※、+标出了 33 对会交头接耳的学生的位置,图中 33 条粗线的位置表示通道,图示的通道划分方案是唯一的最佳方案。
2008年普及组第二题
1 #include<iostream> 2 #include<cstdio> 3 #include<cstring> 4 #include<algorithm> 5 #include<cmath> 6 using namespace std; 7 int m,n,k,l,d; 8 int x[1005],y[1005]; 9 int c[1005],o[1005]; 10 int main() { 11 scanf("%d%d%d%d%d",&m,&n,&k,&l,&d); 12 for(int i=1;i<=d;i++) { 13 int xi,yi,pi,qi; 14 scanf("%d%d%d%d",&xi,&yi,&pi,&qi); 15 if(xi==pi) 16 x[min(yi,qi)]++; 17 else 18 y[min(xi,pi)]++; 19 } 20 for(int i=1;i<=k;i++){ 21 int maxn=-1; 22 int p; 23 for(int j=1;j<m;j++){ 24 if(y[j]>maxn){ 25 maxn=y[j]; 26 p=j; 27 } 28 } 29 y[p]=0; 30 c[p]++; 31 } 32 for(int i=1;i<=l;i++){ 33 int maxn=-1; 34 int p; 35 for(int j=1;j<n;j++){ 36 if(x[j]>maxn){ 37 maxn=x[j]; 38 p=j; 39 } 40 } 41 x[p]=0; 42 o[p]++; 43 } 44 for(int i=0;i<1005;i++) 45 { 46 if(c[i]) 47 printf("%d ",i); 48 } 49 printf("\n"); 50 for(int i=0;i<1005;i++) 51 { 52 if(o[i]) 53 printf("%d ",i); 54 } 55 return 0; 56 }
石头剪刀布是常见的猜拳游戏:石头胜剪刀,剪刀胜布,布胜石头。如果两个人出拳一 样,则不分胜负。在《生活大爆炸》第二季第8集中出现了一种石头剪刀布的升级版游戏。
升级版游戏在传统的石头剪刀布游戏的基础上,增加了两个新手势:
斯波克:《星际迷航》主角之一。
蜥蜴人:《星际迷航》中的反面角色。
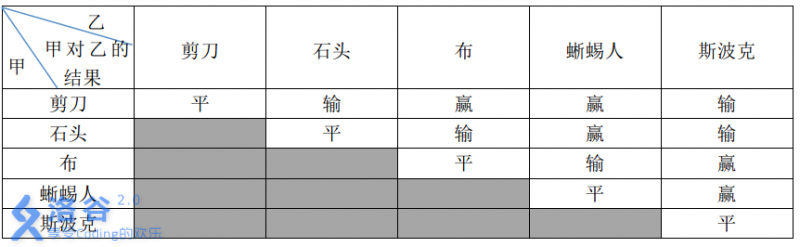
这五种手势的胜负关系如表一所示,表中列出的是甲对乙的游戏结果。
现在,小 A和小 B尝试玩这种升级版的猜拳游戏。已知他们的出拳都是有周期性规律的,但周期长度不一定相等。例如:如果小A以“石头-布-石头-剪刀-蜥蜴人-斯波克”长度为 66 的周期出拳,那么他的出拳序列就是“石头-布-石头-剪刀-蜥蜴人-斯波克-石头-布-石头-剪刀-蜥蜴人-斯波克-......”,而如果小B以“剪刀-石头-布-斯波克-蜥蜴人”长度为 55的周期出拳,那么他出拳的序列就是“剪刀-石头-布-斯波克-蜥蜴人-剪刀-石头-布-斯波克-蜥蜴人-......”
已知小 A和小 B 一共进行 NN 次猜拳。每一次赢的人得 11 分,输的得 00 分;平局两人都得 00 分。现请你统计 NN次猜拳结束之后两人的得分。
输入格式:
第一行包含三个整数: N,N_A,N_BN,NA?,NB? ,分别表示共进行 NN 次猜拳、小 A出拳的周期长度,小 B 出拳的周期长度。数与数之间以一个空格分隔。
第二行包含 N_ANA? 个整数,表示小 A出拳的规律,第三行包含 N_BNB? 个整数,表示小 B 出拳的规律。其中, 00 表示“剪刀”, 11 表示“石头”, 22 表示“布”, 33 表示“蜥蜴人”, 44 表示“斯波克”。数与数之间以一个空格分隔。
输出格式:
输出一行,包含两个整数,以一个空格分隔,分别表示小 A、小 B的得分。
对于 100\%100% 的数据, 0 < N \leq 200, 0 < N_A \leq 200, 0 < N_B \leq 2000<N≤200,0<NA?≤200,0<NB?≤200 。
1 #include<bits/stdc++.h> 2 using namespace std; 3 int n1,n2,n; 4 int a[1000],b[1000]; 5 int mp[5][5]={ 6 0,-1,1,1,-1, 7 1,0,-1,1,-1, 8 -1,1,0,-1,1, 9 -1,-1,1,0,1, 10 1,1,-1,-1,0 11 }; 12 int main(){ 13 scanf("%d%d%d",&n,&n1,&n2); 14 for(int i=0;i<n1;i++){ 15 scanf("%d",&a[i]); 16 } 17 for(int i=0;i<n2;i++){ 18 scanf("%d",&b[i]); 19 } 20 int i=0,j=0; 21 int sum=0,sum1=0; 22 while(n--){ 23 if(mp[a[i]][b[j]]==1){ 24 sum++; 25 } 26 else if(mp[a[i]][b[j]]==-1){ 27 sum1++; 28 } 29 i++,j++; 30 i%=n1,j%=n2; 31 } 32 printf("%d %d\n",sum,sum1); 33 }
小南有一套可爱的玩具小人, 它们各有不同的职业。
有一天, 这些玩具小人把小南的眼镜藏了起来。 小南发现玩具小人们围成了一个圈,它们有的面朝圈内,有的面朝圈外。如下图:
这时 singersinger 告诉小南一个谜題: “眼镜藏在我左数第3个玩具小人的右数第 11 个玩具小人的左数第 22 个玩具小人那里。 ”
小南发现, 这个谜题中玩具小人的朝向非常关键, 因为朝内和朝外的玩具小人的左右方向是相反的: 面朝圈内的玩具小人, 它的左边是顺时针方向, 右边是逆时针方向; 而面向圈外的玩具小人, 它的左边是逆时针方向, 右边是顺时针方向。
小南一边艰难地辨认着玩具小人, 一边数着:
singersinger 朝内, 左数第 33 个是 archerarcher 。
archerarcher 朝外,右数第 11 个是 thinkerthinker 。
thinkerthinker 朝外, 左数第 22 个是 writewrite r。
所以眼镜藏在 writerwriter 这里!
虽然成功找回了眼镜, 但小南并没有放心。 如果下次有更多的玩具小人藏他的眼镜, 或是谜題的长度更长, 他可能就无法找到眼镜了 。 所以小南希望你写程序帮他解决类似的谜題。 这样的谜題具体可以描述为:
有 nn 个玩具小人围成一圈, 已知它们的职业和朝向。现在第 11 个玩具小人告诉小南一个包含 mm 条指令的谜題, 其中第 zz 条指令形如“左数/右数第 ss ,个玩具小人”。 你需要输出依次数完这些指令后,到达的玩具小人的职业。
输入格式:
输入的第一行包含两个正整数 n,mn,m ,表示玩具小人的个数和指令的条数。
接下来 nn 行,每行包含一个整数和一个字符串,以逆时针为顺序给出每个玩具小人的朝向和职业。其中 00 表示朝向圈内, 11 表示朝向圈外。 保证不会出现其他的数。字符串长度不超过 1010 且仅由小写字母构成,字符串不为空,并且字符串两两不同。整数和字符串之间用一个空格隔开。
接下来 mm 行,其中第 ii 行包含两个整数 a_i,s_iai?,si? ,表示第 ii 条指令。若 a_i=0ai?=0 ,表示向左数 s_isi? 个人;若 a_i=1ai?=1,表示向右数 s_isi? 个人。 保证 a_iai? 不会出现其他的数, 1 \le s_i < n1≤si?<n 。
输出格式:
输出一个字符串,表示从第一个读入的小人开始,依次数完 mm 条指令后到达的小人的职业。
7 3 0 singer 0 reader 0 mengbier 1 thinker 1 archer 0 writer 1 mogician 0 3 1 1 0 2
writer
10 10 1 C 0 r 0 P 1 d 1 e 1 m 1 t 1 y 1 u 0 V 1 7 1 1 1 4 0 5 0 3 0 1 1 6 1 2 0 8 0 4
y
【样例1说明】
这组数据就是【题目描述】 中提到的例子。
【子任务】
子任务会给出部分测试数据的特点。 如果你在解决题目中遇到了困难, 可以尝试只解决一部分测试数据。
每个测试点的数据规模及特点如下表:
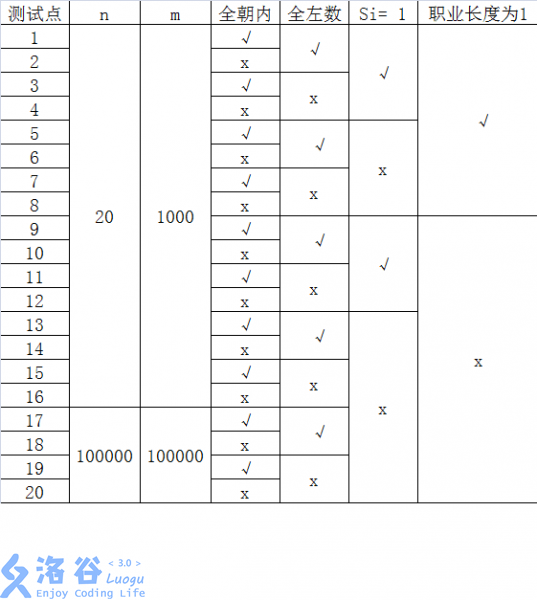
其中一些简写的列意义如下:
? 全朝内: 若为“√”, 表示该测试点保证所有的玩具小人都朝向圈内;
全左数:若为“√”,表示该测试点保证所有的指令都向左数,即对任意的
1≤z≤m, a_i=01≤z≤m,ai?=0 ;
s= 1s=1 :若为“√”,表示该测试点保证所有的指令都只数1个,即对任意的
1≤z≤m,s_i=11≤z≤m,si?=1 ;
职业长度为 11 :若为“√”,表示该测试点保证所有玩具小人的职业一定是一个
长度为 11 的字符串。
1 #include<bits/stdc++.h> 2 using namespace std; 3 struct p{ 4 int chao; 5 char s[1000]; 6 }point[100005]; 7 int n,m; 8 int main(){ 9 scanf("%d%d",&n,&m); 10 for(int i=0;i<n;i++){ 11 scanf("%d%s",&point[i].chao,point[i].s); 12 } 13 int k=0; 14 for(int i=0;i<m;i++){ 15 int a,b; 16 scanf("%d%d",&a,&b); 17 if(a){ 18 if(point[k].chao){ 19 b%=n; 20 k-=b; 21 if(k<0) k+=n; 22 } 23 else{ 24 b%=n; 25 k+=b; 26 k%=n; 27 } 28 } 29 else{ 30 if(point[k].chao){ 31 b%=n; 32 k+=b; 33 k%=n; 34 } 35 else{ 36 b%=n; 37 k-=b; 38 if(k<0) k+=n; 39 } 40 } 41 } 42 printf("%s\n",point[k].s); 43 }
标签:cin 模拟 遇到 tin 译文 erase region poi 方案
原文地址:https://www.cnblogs.com/dahaihaohan/p/9387989.html