标签:概率 core int imp line .com 优化 文档 情况

LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class=‘ovr‘, n_jobs=1, penalty=‘l2‘, random_state=None, solver=‘liblinear‘, tol=0.0001, verbose=0, warm_start=False)
# LogisticRegression() 实例对象,包含了很多参数;
不懂的要学会 看文档、看文档、看文档:help(算法、实例对象);
C=1.0:正则化的超参数,默认为 1.0;
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets iris = datasets.load_iris() # [:, :2]:所有行,0、1 列,不包含 2 列; X = iris.data[:,:2] y = iris.target from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666) from sklearn.linear_model import LogisticRegression log_reg = LogisticRegression() log_reg.fit(X_train, y_train) log_reg.score(X_test, y_test) # 准确率:0.6578947368421053
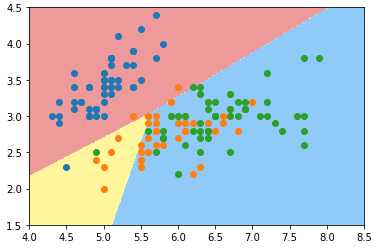
def plot_decision_boundary(model, axis): x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1), np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1) ) X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new) zz = y_predict.reshape(x0.shape) from matplotlib.colors import ListedColormap custom_cmap = ListedColormap([‘#EF9A9A‘,‘#FFF59D‘,‘#90CAF9‘]) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap) plot_decision_boundary(log_reg, axis=[4, 8.5, 1.5, 4.5]) # 可视化时只能在同一个二维平面内体现两种特征; plt.scatter(X[y==0, 0], X[y==0, 1]) plt.scatter(X[y==1, 0], X[y==1, 1]) plt.scatter(X[y==2, 0], X[y==2, 1]) plt.show()
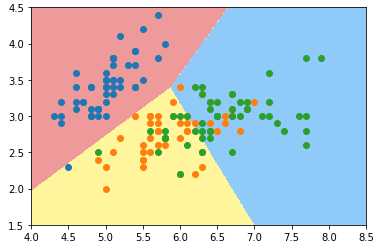
log_reg2 = LogisticRegression(multi_class=‘multinomial‘, solver=‘newton-cg‘) # ‘multinomial‘:指 OvO 方法; log_reg2.fit(X_train, y_train) log_reg2.score(X_test, y_test) # 准确率:0.7894736842105263 plot_decision_boundary(log_reg2, axis=[4, 8.5, 1.5, 4.5]) plt.scatter(X[y==0, 0], X[y==0, 1]) plt.scatter(X[y==1, 0], X[y==1, 1]) plt.scatter(X[y==2, 0], X[y==2, 1]) plt.show()
X = iris.data y = iris.target X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666) log_reg_ovr = LogisticRegression() log_reg_ovr.fit(X_train, y_train) log_reg_ovr.score(X_test, y_test) # 准确率:0.9473684210526315
log_reg_ovo = LogisticRegression(multi_class=‘multinomial‘, solver=‘newton-cg‘) log_reg_ovo.fit(X_train, y_train) log_reg_ovo.score(X_test, y_test) # 准确率:1.0
四、
标签:概率 core int imp line .com 优化 文档 情况
原文地址:https://www.cnblogs.com/volcao/p/9389921.html