标签:价值 世界 等等 单机 绿色 分布式 容器 ado cpu
More Applications in Less Machines你办得到吗?

互联网应用和现代数据中心
云计算已经火了很多年了,早已开始惠及我们每一个人。今天火热的大数据、机器学习、人工智能、以及我们看到的像淘宝、天猫、优酷等大规模的互联网应用都是运行在云上的。而支撑云的,是大型云计算服务商部署在世界各地的多个数据中心,每个数据中心都有大量的物理服务器。为了有效的管理这些服务器,我们需要集群资源管理系统(Cluster Resource Management System),后面简称资源管理系统。资源管理系统的价值,用一句话说,是Datacenter as a Computer,像管理和使用一个台电脑一样简单地管理和使用数据中心。
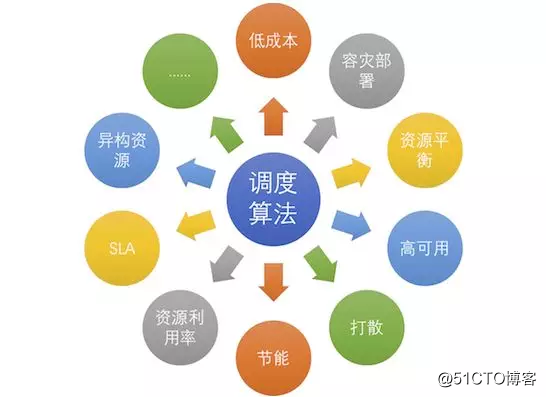
资源管理系统作为将数据中心资源向上抽象的关键一层,需要全面的能力。从保障应用的稳定性、性能(保证SLA,Service Level Agreement)到全面提高数据中心运行的效率,节约能源等等,今天这篇文章,我们重点讲一讲调度算法在资源管理中的作用。
调度算法的价值
调度算法在是整个资源管理系统中的一个重要组成部分,简单的说,调度算法的作用是决定一个计算任务需要放在集群中的哪台机器上面。
在容器化的今天,集群中调度器的调度对象很可能是一个容器实例,Docker或者是PouchContainer。为容器选择合适的宿主机显然是一个值得考虑的问题,这里我们说一说调度算法能够帮助我们实现的价值,这些价值可以从单个容器、到应用、再到数据中心,这三个不同的层面展示出来。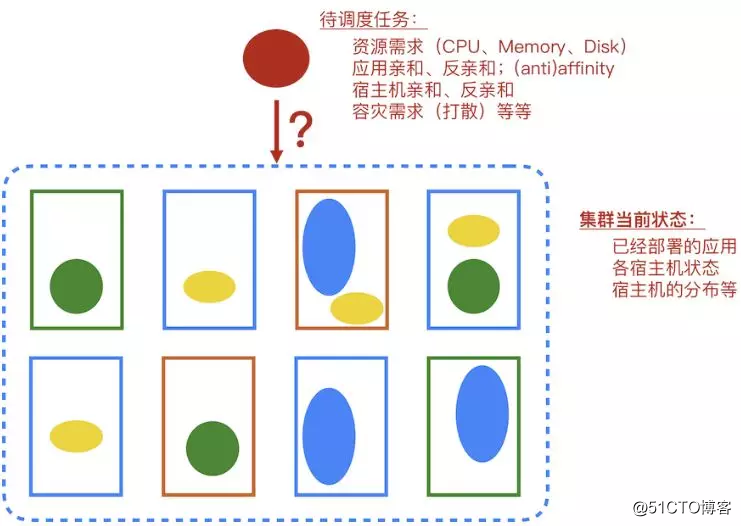
单个容器层面
满足容器运行的资源需求:确保每个容器在运行的时候拥有足够的资源,CPU、Memory、Disk、网络带宽等等。除了用数量衡量的资源,很多容器在运行的时候还需要一些特殊的资源,例如特定的操作系统版本、特定的硬件等等。
让容器在更“舒适”的环境下运行:容器之间可能发生资源的抢占现象,例如两个对Memory消耗很大的容器部署在同一台机器上,很容易造成Memory资源的吃紧。虽然我们可以通过容器和内核提供的资源隔离技术降低这种影响,但是最好的办法还是在一开始不让这种“容易吵架的人做邻居”。
应用层面
每个应用在提供服务的时候往往是多个容器实例同时支持的,调度器需要考虑应用的需求。
应用的高可用:分布式环境下宿主机失败或者单个容器的失败是正常现象,因此我们要保证每个应用同时有多个实例在运行,这样即使有一个实例挂了,整个应用不会受很大影响。
应用的容灾:容灾其实也经常和高可用放在一起,如果一个应用有多个应用实例,但是都部署在一个机房,如果机房断电,那么应用也就不能提供服务了,没有高可用了。解决这个问题需要的容灾部署,也就不同维度的打散。调度算法需要尽量让同一个应用的不同实例部署在不同的宿主机、不同的机架、不同的机房、不同的数据中心、不同的城市、甚至是不同的国家;这种容灾甚至可以体现在更高一层,几个重要应用之间的所有实例,也要尽量打散。
很多应用因为其提供服务特性往往需要调度器做更多的事情,例如:按照一定的顺序调度实例、将计算任务调度到离数据最近的地方,等等,这里不一一列举了。
数据中心层面
降低数据中心的成本:合理的调度能够节省数据中心大量的成本,如果用装箱问题来表示,就是用更少的服务器装下了更多的应用。服务器数目的减少不仅仅是采购成本的下降,服务器的占地、用电、冷却等都是一笔很大的开销,合理的资源调度能够为数据中心节省大量成本。
除了以上这些内容,实际中调度算法要考虑的内容还有很多,例如公平性的问题、应用间的干扰问题、不同应用间资源共享(互相借用)的问题、单机资源的调配问题(超线程、内存带框等)等等。例如,实际管理阿里巴巴集团在线服的资源管理系统Sigma的调度规则,就十分复杂。
为了让更多的学生、研究者能够接触到我们的调度问题,并鼓励他们与我们一起应对挑战,我们举办了“阿里巴巴全球调度算法挑战赛”。这个算法大赛是怎么回事儿呢?让我们介绍一下。
首届阿里全球调度算法大赛
大家可以想象下,阿里巴巴拥有如此大规模的数据中心,1%的资源利用率的提升都将为阿里巴巴自身和整个社会带来可观的能源节约让用户享受更加绿色的计算资源。所以最近我们发起了首届阿里全球调度算法大赛,初赛赛题来自我们生产环境中的一个真实的场景,简化了一些约束条件,方便一些对这个领域刚刚开始了解的同学找到一个求解的方法,但是即使对于在该领域有一定经验的同学、工程师、研究者们,我们也相信这份题目能够让你花费一些精力才能得到一个优化的解。
在这次算法大赛中,我们提供了大约6K个宿主机,68K个实例(其中一部分已经部署,一部分尚未部署),约束类型主要有3类:资源约束、重要应用高可用约束和应用间反亲和约束。
资源约束
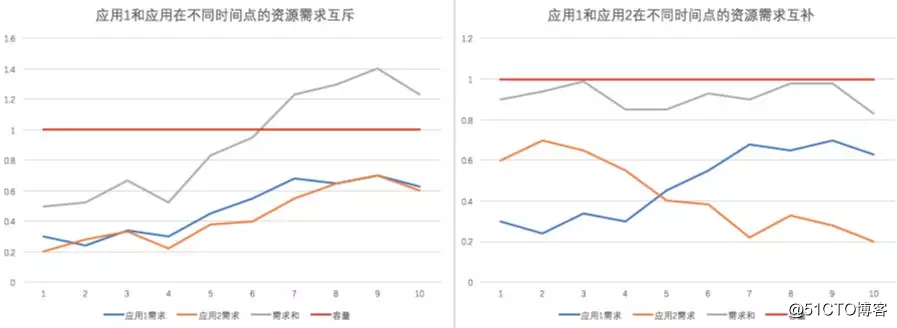
资源约束是最容易理解的,每个属于不同应用的实例都有不同的计算资源要求。我们本次比赛的一个重要特点是,CPU和Mem的数量约束是以时间曲线的形式给出的。每个应用的对应资源需求的时间曲线是我们通过对该应用下多个实例(一个应用由很多实例组成)的24小时的历史数据进行观察并整理得到的需求曲线,描述了每个应用下面的实例在一天当中每个采样点需要的对应资源的数量。映射的场景是我们假定各个应用的实例的资源需求的有着24小时的变化周期(即98个点的变化周期),第二天、第三天甚至再往后,应用的实例还是按照这个需求长时间存在。注意,这里提到的应用是长应用(Long Running Service),没有特殊原因是不会下线的(例如淘宝网),这种长应用与一些分布式计算中的有限持续时间计算任务是不一样。
这样的时间曲线比普通的标量规定的资源需求具有更多的优化空间,但也带来了更多的复杂度。下面这个图是两个应用在不同时间点的资源需求对于满足机器容量的互斥(左)与互补(右)的例子。
重要应用高可用约束
除了CPU、Mem、Disk这样计算资源的约束,我们还有三类名为P、M、PM的约束,这个约束名字大家可能会觉得有些奇怪,但这是我们通过调度来保障重要应用高可用的重要约束。我们把一些重要应用标记为P类、M类、或者PM类,通过限制每台机器上可以承载的P、M、PM类型应用实例的上限来保证在机器发生故障的时候(宕机、断网等),重要应用受到的影响最小。
应用间反亲和约束
在上述两种约束之外,我们提供第三种的约束类型是应用之间的反亲和,以<App_1, App_2, k>的形式给出,其语义是:如果一台机器上已经部署了一个App_1的实例,那么这台机器上最多可以部署k个来自App_2的实例。这种约束在实际中的意义是什么呢?这些约束使我们通过观测和经验,确定这两个应用间可能存在干扰因素,如果有超过一定数量的两类应用的实例部署在一起,会影响彼此的性能,因此,在进行调度决策的时候尽量不让这种互相干扰的应用的实例出现“扎堆”的现象。
优化的目标
我们的优化目标是在维持每台机器的资源使用率在一定水平的基础上(具体数字不透露,你好好看一下题目的描述,相信你可以判断出来的),尽量减少使用的机器的数目(即实际部署了容器的机器的数目)。为什么这样设计呢?较少机器的数目很容易想到是节省成本,而维持机器的资源利用率在一定水平,而不是100%,在实际生产中是很有意义的。因为每个应用都会有一定的、不可准确预计的负载增加,因此,我们需要在每台机器上流出一定的“余量”来应对每个实例可能突然需要的计算资源。
这些余量的资源在平时也可以为我们所用,但这并在不在我们初赛的考察范围内。也许复赛中我们会涉及到这些内容。另外,有经验的朋友可能会发现我们这里没有对应用的迁移做出限制,没错,我们这样做的目的是为了降低初赛的难度。实际生产中,应用的迁移,尤其我们这次考虑的在线应用的迁移是一件颇有代价的事情,你能否在设计算法的时候考虑一下应用迁移的代价呢?
我们诚挚的邀请所有对资源调度、运筹优化、资源管理、算法有兴趣的同学、学者来参加我们的大赛,奖金丰厚而且有前往美国参加Hackathon的机会!
标签:价值 世界 等等 单机 绿色 分布式 容器 ado cpu
原文地址:http://blog.51cto.com/13778063/2152120