标签:ali one rop ace 效果图 tle sem 逻辑回归 gaussian
https://www.cnblogs.com/hhh5460/p/5132203.html
这几天在看 sklearn 的文档,发现他的分类器有很多,这里做一些简略的记录。
大致可以将这些分类器分成两类: 1)单一分类器,2)集成分类器
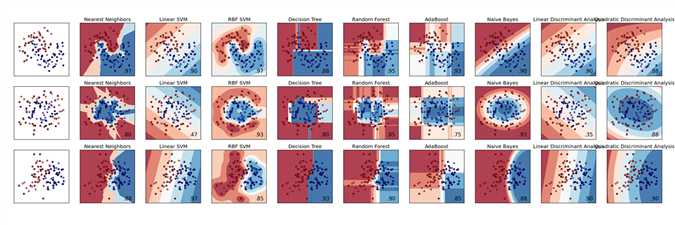
下面这个例子对一些单一分类器效果做了比较
下图是效果图:
集成分类器有四种:Bagging, Voting, GridSearch, PipeLine。最后一个PipeLine其实是管道技术
from sklearn.ensemble import BaggingClassifier from sklearn.neighbors import KNeighborsClassifier meta_clf = KNeighborsClassifier() bg_clf = BaggingClassifier(meta_clf, max_samples=0.5, max_features=0.5)

from sklearn import datasets
from sklearn import cross_validation
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
eclf = VotingClassifier(estimators=[(‘lr‘, clf1), (‘rf‘, clf2), (‘gnb‘, clf3)], voting=‘hard‘, weights=[2,1,2])
for clf, label in zip([clf1, clf2, clf3, eclf], [‘Logistic Regression‘, ‘Random Forest‘, ‘naive Bayes‘, ‘Ensemble‘]):
scores = cross_validation.cross_val_score(clf, X, y, cv=5, scoring=‘accuracy‘)
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
import numpy as np
from sklearn.datasets import load_digits
from sklearn.ensemble import RandomForestClassifier
from sklearn.grid_search import GridSearchCV
from sklearn.grid_search import RandomizedSearchCV
# 生成数据
digits = load_digits()
X, y = digits.data, digits.target
# 元分类器
meta_clf = RandomForestClassifier(n_estimators=20)
# =================================================================
# 设置参数
param_dist = {"max_depth": [3, None],
"max_features": sp_randint(1, 11),
"min_samples_split": sp_randint(1, 11),
"min_samples_leaf": sp_randint(1, 11),
"bootstrap": [True, False],
"criterion": ["gini", "entropy"]}
# 运行随机搜索 RandomizedSearch
n_iter_search = 20
rs_clf = RandomizedSearchCV(meta_clf, param_distributions=param_dist,
n_iter=n_iter_search)
start = time()
rs_clf.fit(X, y)
print("RandomizedSearchCV took %.2f seconds for %d candidates"
" parameter settings." % ((time() - start), n_iter_search))
print(rs_clf.grid_scores_)
# =================================================================
# 设置参数
param_grid = {"max_depth": [3, None],
"max_features": [1, 3, 10],
"min_samples_split": [1, 3, 10],
"min_samples_leaf": [1, 3, 10],
"bootstrap": [True, False],
"criterion": ["gini", "entropy"]}
# 运行网格搜索 GridSearch
gs_clf = GridSearchCV(meta_clf, param_grid=param_grid)
start = time()
gs_clf.fit(X, y)
print("GridSearchCV took %.2f seconds for %d candidate parameter settings."
% (time() - start, len(gs_clf.grid_scores_)))
print(gs_clf.grid_scores_)
第一个例子
from sklearn import svm from sklearn.datasets import samples_generator from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_regression from sklearn.pipeline import Pipeline # 生成数据 X, y = samples_generator.make_classification(n_informative=5, n_redundant=0, random_state=42) # 定义Pipeline,先方差分析,再SVM anova_filter = SelectKBest(f_regression, k=5) clf = svm.SVC(kernel=‘linear‘) pipe = Pipeline([(‘anova‘, anova_filter), (‘svc‘, clf)]) # 设置anova的参数k=10,svc的参数C=0.1(用双下划线"__"连接!) pipe.set_params(anova__k=10, svc__C=.1) pipe.fit(X, y) prediction = pipe.predict(X) pipe.score(X, y) # 得到 anova_filter 选出来的特征 s = pipe.named_steps[‘anova‘].get_support() print(s)
第二个例子
import numpy as np from sklearn import linear_model, decomposition, datasets from sklearn.pipeline import Pipeline from sklearn.grid_search import GridSearchCV digits = datasets.load_digits() X_digits = digits.data y_digits = digits.target # 定义管道,先降维(pca),再逻辑回归 pca = decomposition.PCA() logistic = linear_model.LogisticRegression() pipe = Pipeline(steps=[(‘pca‘, pca), (‘logistic‘, logistic)]) # 把管道再作为grid_search的estimator n_components = [20, 40, 64] Cs = np.logspace(-4, 4, 3) estimator = GridSearchCV(pipe, dict(pca__n_components=n_components, logistic__C=Cs)) estimator.fit(X_digits, y_digits)
标签:ali one rop ace 效果图 tle sem 逻辑回归 gaussian
原文地址:https://www.cnblogs.com/jukan/p/9390988.html