标签:win 部分 redis持久化 子进程 统一 总结 规模 技术分享 多线程模型
最近在学习redis和kafka这两篇博客就分别做一下总结,方便自己以后学习。
redis是一个开源的、使用C语言编写的、支持网络交互的、可基于内存也可持久化的Key-Value数据库。
【redis数据结构 – 简介】
redis是一种高级的key:value存储系统,其中value支持五种数据类型:
1.字符串(strings)
2.字符串列表(lists)
3.字符串集合(sets)
4.有序字符串集合(sorted sets)
5.哈希(hashes)
而关于key,有几个点要提醒大家:
1.key不要太长,尽量不要超过1024字节,这不仅消耗内存,而且会降低查找的效率;
2.key也不要太短,太短的话,key的可读性会降低;
3.在一个项目中,key最好使用统一的命名模式,例如user:10000:passwd。
聊聊redis持久化 – 两种方式】
redis提供了两种持久化的方式,分别是RDB(Redis DataBase)和AOF(Append Only File)。
RDB,简而言之,就是在不同的时间点,将redis存储的数据生成快照并存储到磁盘等介质上;
AOF,则是换了一个角度来实现持久化,那就是将redis执行过的所有写指令记录下来,在下次redis重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。
其实RDB和AOF两种方式也可以同时使用,在这种情况下,如果redis重启的话,则会优先采用AOF方式来进行数据恢复,这是因为AOF方式的数据恢复完整度更高。
如果你没有数据持久化的需求,也完全可以关闭RDB和AOF方式,这样的话,redis将变成一个纯内存数据库,就像memcache一样。
【聊聊redis持久化 – RDB】
RDB方式,是将redis某一时刻的数据持久化到磁盘中,是一种快照式的持久化方法。
redis在进行数据持久化的过程中,会先将数据写入到一个临时文件中,待持久化过程都结束了,才会用这个临时文件替换上次持久化好的文件。正是这种特性,让我们可以随时来进行备份,因为快照文件总是完整可用的。
对于RDB方式,redis会单独创建(fork)一个子进程来进行持久化,而主进程是不会进行任何IO操作的,这样就确保了redis极高的性能。
如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
虽然RDB有不少优点,但它的缺点也是不容忽视的。如果你对数据的完整性非常敏感,那么RDB方式就不太适合你,因为即使你每5分钟都持久化一次,当redis故障时,仍然会有近5分钟的数据丢失。所以,redis还提供了另一种持久化方式,那就是AOF。
【聊聊redis持久化 – AOF】
AOF,英文是Append Only File,即只允许追加不允许改写的文件。
如前面介绍的,AOF方式是将执行过的写指令记录下来,在数据恢复时按照从前到后的顺序再将指令都执行一遍,就这么简单。
我们通过配置redis.conf中的appendonly yes就可以打开AOF功能。如果有写操作(如SET等),redis就会被追加到AOF文件的末尾。
默认的AOF持久化策略是每秒钟fsync一次(fsync是指把缓存中的写指令记录到磁盘中),因为在这种情况下,redis仍然可以保持很好的处理性能,即使redis故障,也只会丢失最近1秒钟的数据。
如果在追加日志时,恰好遇到磁盘空间满、inode满或断电等情况导致日志写入不完整,也没有关系,redis提供了redis-check-aof工具,可以用来进行日志修复。
因为采用了追加方式,如果不做任何处理的话,AOF文件会变得越来越大,为此,redis提供了AOF文件重写(rewrite)机制,即当AOF文件的大小超过所设定的阈值时,redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集。举个例子或许更形象,假如我们调用了100次INCR指令,在AOF文件中就要存储100条指令,但这明显是很低效的,完全可以把这100条指令合并成一条SET指令,这就是重写机制的原理。
在进行AOF重写时,仍然是采用先写临时文件,全部完成后再替换的流程,所以断电、磁盘满等问题都不会影响AOF文件的可用性,这点大家可以放心。
AOF方式的另一个好处,我们通过一个“场景再现”来说明。某同学在操作redis时,不小心执行了FLUSHALL,导致redis内存中的数据全部被清空了,这是很悲剧的事情。不过这也不是世界末日,只要redis配置了AOF持久化方式,且AOF文件还没有被重写(rewrite),我们就可以用最快的速度暂停redis并编辑AOF文件,将最后一行的FLUSHALL命令删除,然后重启redis,就可以恢复redis的所有数据到FLUSHALL之前的状态了。是不是很神奇,这就是AOF持久化方式的好处之一。但是如果AOF文件已经被重写了,那就无法通过这种方法来恢复数据了。
虽然优点多多,但AOF方式也同样存在缺陷,比如在同样数据规模的情况下,AOF文件要比RDB文件的体积大。而且,AOF方式的恢复速度也要慢于RDB方式。
如果你直接执行BGREWRITEAOF命令,那么redis会生成一个全新的AOF文件,其中便包括了可以恢复现有数据的最少的命令集。
如果运气比较差,AOF文件出现了被写坏的情况,也不必过分担忧,redis并不会贸然加载这个有问题的AOF文件,而是报错退出。这时可以通过以下步骤来修复出错的文件:
1.备份被写坏的AOF文件
2.运行redis-check-aof –fix进行修复
3.用diff -u来看下两个文件的差异,确认问题点
4.重启redis,加载修复后的AOF文件
【聊聊redis持久化 – AOF重写】
AOF重写的内部运行原理,我们有必要了解一下。
在重写即将开始之际,redis会创建(fork)一个“重写子进程”,这个子进程会首先读取现有的AOF文件,并将其包含的指令进行分析压缩并写入到一个临时文件中。
与此同时,主工作进程会将新接收到的写指令一边累积到内存缓冲区中,一边继续写入到原有的AOF文件中,这样做是保证原有的AOF文件的可用性,避免在重写过程中出现意外。
当“重写子进程”完成重写工作后,它会给父进程发一个信号,父进程收到信号后就会将内存中缓存的写指令追加到新AOF文件中。
当追加结束后,redis就会用新AOF文件来代替旧AOF文件,之后再有新的写指令,就都会追加到新的AOF文件中了。
【聊聊主从 – 用法】
像MySQL一样,redis是支持主从同步的,而且也支持一主多从以及多级从结构。
主从结构,一是为了纯粹的冗余备份,二是为了提升读性能,比如很消耗性能的SORT就可以由从服务器来承担。
redis的主从同步是异步进行的,这意味着主从同步不会影响主逻辑,也不会降低redis的处理性能。
主从架构中,可以考虑关闭主服务器的数据持久化功能,只让从服务器进行持久化,这样可以提高主服务器的处理性能。
在主从架构中,从服务器通常被设置为只读模式,这样可以避免从服务器的数据被误修改。但是从服务器仍然可以接受CONFIG等指令,所以还是不应该将从服务器直接暴露到不安全的网络环境中。如果必须如此,那可以考虑给重要指令进行重命名,来避免命令被外人误执行。
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路I/O复用模型,非阻塞IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
以上几点都比较好理解,下边我们针对多路 I/O 复用模型进行简单的探讨:
(1)多路 I/O 复用模型
多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈,主要由以上几点造就了 Redis 具有很高的吞吐量。
我们首先要明白,上边的种种分析,都是为了营造一个Redis很快的氛围!官方FAQ表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!)。

可以参考:https://redis.io/topics/faq
看到这里,你可能会气哭!本以为会有什么重大的技术要点才使得Redis使用单线程就可以这么快,没想到就是一句官方看似糊弄我们的回答!但是,我们已经可以很清楚的解释了为什么Redis这么快,并且正是由于在单线程模式的情况下已经很快了,就没有必要在使用多线程了!
但是,我们使用单线程的方式是无法发挥多核CPU 性能,不过我们可以通过在单机开多个Redis 实例来完善!
以下也是你应该知道的几种模型,祝你的面试一臂之力!
1、单进程多线程模型:MySQL、Memcached、Oracle(Windows版本);
2、多进程模型:Oracle(Linux版本);
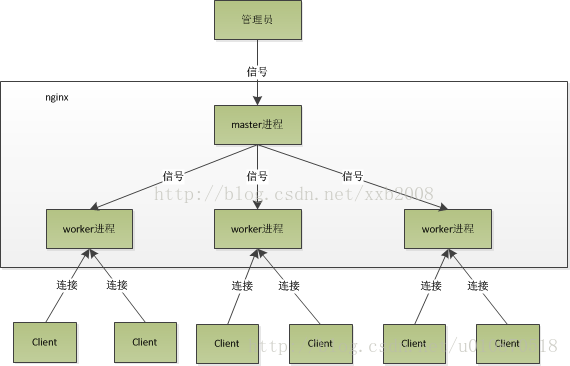
3、Nginx有两类进程,一类称为Master进程(相当于管理进程),另一类称为Worker进程(实际工作进程)。启动方式有两种:
(1)单进程启动:此时系统中仅有一个进程,该进程既充当Master进程的角色,也充当Worker进程的角色。
(2)多进程启动:此时系统有且仅有一个Master进程,至少有一个Worker进程工作。
(3)Master进程主要进行一些全局性的初始化工作和管理Worker的工作;事件处理是在Worker中进行的。
标签:win 部分 redis持久化 子进程 统一 总结 规模 技术分享 多线程模型
原文地址:https://www.cnblogs.com/XiaoXiaMi123/p/9396308.html