标签:collect red 1.2 阶段 本地 映射 oop 分区 分配
1.1 MapReduce 是什么
MapReduce 是一种分布式的离线计算框架,是一种编程模型,用于大规模数据集(大于 1TB)的并行运算。将自己的程序运行在分布式系统上。概念是:"Map(映射)"和"Reduce(归约)"。 指定一个 Map( 映射) ) 函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce( 归约) ) 函数,用来保证所有映射的键值对中的每一个共享相同的键组。常用于大规模的图形算法 、文字处理 。
1.2 设计理念
(1) 分布式计算 :分布式计算将该应用分解成许多小的部分,分配给多台计算机节点进行处理。这样可以节约整体计算时间,大大提高计算效率。
(2)移动计算,而不是移动数据: 移动计算是随着移动通信、互联网、数据库、分布式计算等技术的发展而兴起的新技术。移动计算它的作用是将有用、准确、及时
的信息提供给任何时间、任何地点的任何客户。
1.3 计算框架组成
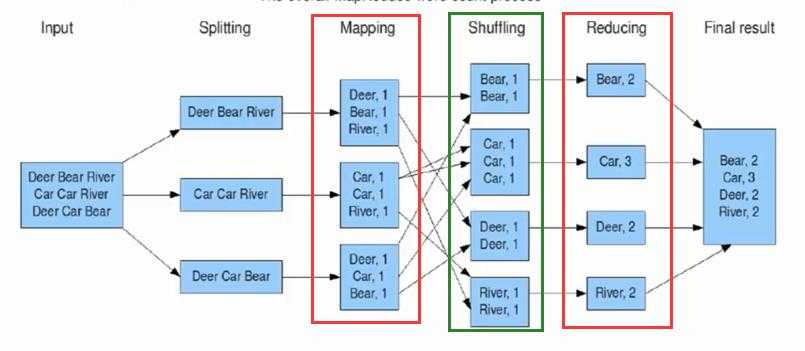
1.3.1 Mapper 详解
Map-reduce 的思想就好比太极又好比天下大势Mapper 负责“ 分”,即把得到的复杂的任务分解为若干个“简单的任务”执行。
“简单的任务”有几个含义:
1、数据或计算规模相对于原任务要大大缩小;
2、就近计算,即会被分配到存放了所需数据的节点进行计算;
3、这些小任务可以并行计算,彼此间几乎没有依赖关系
Split 规则: max(min.split,min(max.split,block)) 假设: – max.split(100M) – min.split(10M) – block(64M) 实际=block 大小 Map 的数目通常是由输入数据的大小决定的,一般就是所有输入文件 的总块(block)数
具体理解:
mapper将输入的键值对映射到一组中间的键值对。
映射将独立的任务的输入记录转换成中间的记录。装好的中间记录不需要和输入记录保持同一种类型。一个给定的输入对可以映射成0个或者多个输出对。
Hadoop Map-Reduce框架为每个job产生的输入格式(InputFormat)的InputSplit产生一个映射task。Mapper实现类通过JobConfigurable#configure(JobConf)
获取job的JobConf,并初始化自己。类似的,它们使用Closeable#close()方法消耗初始化。
框架为该任务的InputSplit中的每个键值对调用map(Object, Object, OutputCollector, Reporter)方法。所有关联到给定输出的中间值随后由框架分组,
并传到Reducer来确定最终的输出。用户可通过指定一个比较器Compator来控制分组,Compator的指定通过JobConf#setOutputKeyComparatorClass(Class)完成。
分组的Mapper输出每个Reducer一个分区。用户可以通过实现自定义的分区来控制哪些键(和记录)到哪个Reducer。
用户可以选择指定一个Combiner,通过JobConf#setCombinerClass(Class),来执行本地中间输出的聚合,它可以帮助减少数据从Mapper到Reducer数据转换的数量。
中间、分组的输出保存在SequeceFile文件中,应用可以指定中间输出是否和怎么样压缩,压缩算法可以通过JobConf来设置CompressionCodec。
若job没有reducer,Mapper的输出直接写到FileSystem,而不会根据键分组。
1.3.2 shuffle 详解(分)
hadoop的核心思想是MapReduce,但shuffle又是MapReduce的核心。shuffle的主要工作是从Map结束到Reduce开始之间的过程。
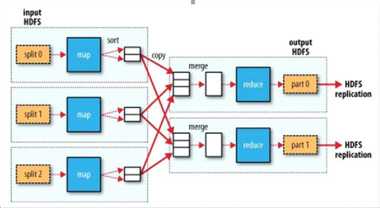
首先看下这张图,就能了解shuffle所处的位置。图中的partitions、copy phase、sort phase所代表的就是shuffle的不同阶段。
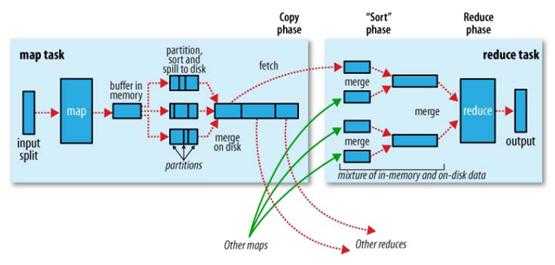
shuffle阶段又可以分为Map端的shuffle和Reduce端的shuffle。
① Map端的shuffle
Map端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。每个Map的输出会先写到内存缓冲区中,当
写入的数据达到设定的阈值时,系统将会启动一个线程将缓冲区的数据写到磁盘,这个过程叫做spill。
在spill写入之前,会先进行二次排序,首先根据数据所属的partition进行排序,然后每个partition中的数据再按key来排序。partition的
目是将记录划分到不同的Reducer上去,以期望能够达到负载均衡,以后的Reducer就会根据partition来读取自己对应的数据。接着运行combiner
(如果设置了的话),combiner的本质也是一个Reducer,其目的是对将要写入到磁盘上的文件先进行一次处理,这样,写入到磁盘的数据量就会减少
。最后将数据写到本地磁盘产生spill文件(spill文件保存在{mapred.local.dir}指定的目录中,Map任务结束后就会被删除)。
最后,每个Map任务可能产生多个spill文件,在每个Map任务完成前,会通过多路归并算法将这些spill文件归并成一个文件。至此,Map的shuffle
过程就结束了。
② Reduce端的shuffle
Reduce端的shuffle主要包括三个阶段,copy、sort(merge)和reduce。
首先要将Map端产生的输出文件拷贝到Reduce端,但每个Reducer如何知道自己应该处理哪些数据呢?因为Map端进行partition的时候,实际上就
相当于指定了每个Reducer要处理的数据(partition就对应了Reducer),所以Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据即可。每
个Reducer会处理一个或者多个partition,但需要先将自己对应的partition中的数据从每个Map的输出结果中拷贝过来。
接下来就是sort阶段,也成为merge阶段,因为这个阶段的主要工作是执行了归并排序。从Map端拷贝到Reduce端的数据都是有序的,所以很适合归
并排序。最终在Reduce端生成一个较大的文件作为Reduce的输入。
最后就是Reduce过程了,在这个过程中产生了最终的输出结果,并将其写到HDFS上。
1.4 reducer详解(合)
reduce阶段操作的实质就是对经过shuffle处理后的文件调用reduce函数处理。由于经过了shuffle的处理,文件都是按键分区且有序,对相同分区的文件调用一次
reduce函数处理。与map的中间结果不同的是,reduce的输出一般为HDFS。
Reducer 的 数 目 由 mapred-site.xml 配 置 文 件 里 的 项 目mapred.reduce.tasks 决定。缺省值为 1,用户可以覆盖之。
标签:collect red 1.2 阶段 本地 映射 oop 分区 分配
原文地址:https://www.cnblogs.com/luren-hometown/p/9399361.html