标签:secondary 重要特性 问题 工作 检测 数据存储 distrib 读数 多个
HDFS 是 Hadoop Distribute File System 的简称,意为:Hadoop 分布式文件系统,分布式文件系统解决的问题就是数据存储。
首先,它是一个文件系统,用于存储文件,通过统一的命名空间目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
NameNode 负责管理整个文件系统元数据;DataNode 负责管理具体文件数据块存储;Secondary NameNode 协助 NameNode 进行元数据的备份。
HDFS 的内部工作机制对客户端保持透明,客户端请求访问 HDFS 都是通过向NameNode 申请来进行。
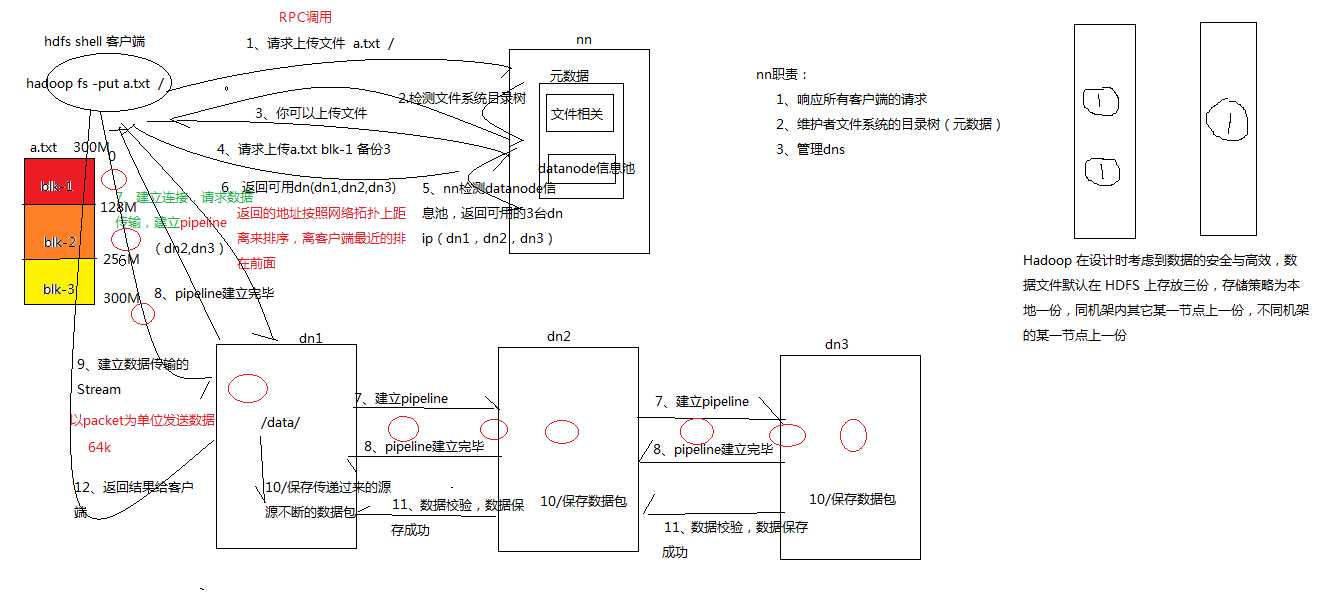
HDFS写数据流程
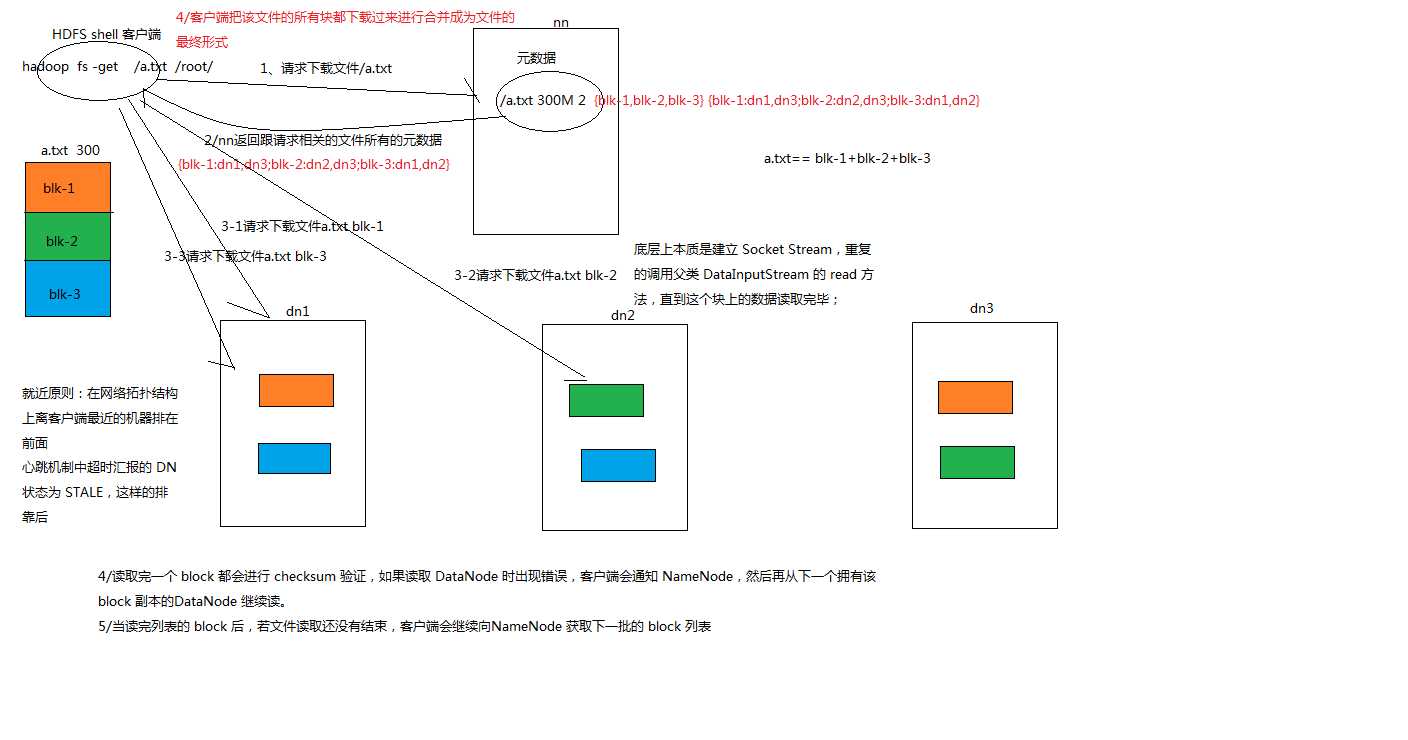
HDFS读数据流程
标签:secondary 重要特性 问题 工作 检测 数据存储 distrib 读数 多个
原文地址:https://www.cnblogs.com/lifuwei/p/9394122.html