标签:工作效率 结束 %x bytes dns sea net 序列 形式
三次握手四次挥手半连接池: 限制的是同一时刻的请求数,而非连接数
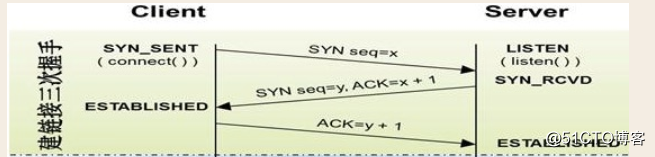
syn_sent是客户端发送请求时的状态
listen是服务端一开始的接听状态
syn_rcvd是服务端收到请求后的状态
established是客户端建立连接后的状态(客户端到服务端这端的管道建立)
eatablished是服务端建立连接后的状态(服务端到客户端这端的管道建立)
seq = x 请求的时候附带的序列号(暗号)
ack = x+1 是回复请求, 并把刚刚拿到的序列号+1

client<---基于网络通信--->server
browser<---基于网络通信--->server
server端(服务端)必须满足的条件:
1、稳定运行(网络、硬件、操作系统、服务端应用软件),对外一直提供服务
2、服务端必须绑定一个固定的地址两大要素:
1、底层的物理连接介质,是为通信铺好道路的
2、一套统一的通信标准---》互联网通信协议
互联网协议就是计算机界的英语任何一种通信协议都必须包含两部分:
1 报头:必须是固定长度(如果不固定长度,会有粘包现象)
2 数据: 数据可以用字典的形式来传.比如 数据的名字,大小,内容,描述ip+mac就能标识全世界范围内独一无二的一台计算机
ip+mac+port就能标识全世界范围内独一无二的一个基于网络通信的应用软件
url地址:标识全世界范围内独一无二的一个资源
DHCP 默认端口是 67
DNS 默认端口 53三次握手是为了建立连接,建立连接时并没有数据产生
四次挥手断开连接是因为客户端与服务端已经产生了数据交互,
这时客户端发送请求只断开了客户端与服务端的连接,
而服务端说不定还有别的数据没有传送完毕,所有一定要四次tcp调用的操作系统,操作系统发出数据,接受到对方传来的确认信息时才会清空数据
优点: 数据安全 缺点: 工作效率低
udp是直接发送, 发完就删
优点: 效率高 缺点: 数据不安全为何tcp协议会有粘包问题?
因为tcp想优化效率,里面有个叫nagle算法.这个算法规定了tcp协议在传输数据的时候会将数据较小,传输间隔较短的多条数据合并成一条发送
而tcp是通过操作系统来发送数据的,操作系统想什么时候发就什么时候发,应用层管不到操作系统, tcp把数据交给操作系统是告诉了操作系统一件事,让操作系统把数据较小,传输间隔较短的多条数据合并成一条发送.就造成了粘包现象
import struct
import json
header_dic={
‘filename‘:‘a.txt‘,
‘total_size‘:11112313123212222222222222222222222222222222222222222222222222222221111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111131222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222223,
‘hash‘:‘asdf123123x123213x‘
}
header_json=json.dumps(header_dic) #将字典序列化成字符串
header_bytes=header_json.encode(‘utf-8‘) #转换成bytes
obj=struct.pack(‘i‘,len(header_bytes)) #用i模式固定长度(固定的长度为4
print(obj,len(obj))
res=struct.unpack(‘i‘,obj) # 用i模式解开obj
print(res)
输出结果如下:
507
b‘\xfb\x01\x00\x00‘ 4
(507,)
from socket import *
import struct
import json
phone = socket(AF_INET, SOCK_STREAM)
phone.connect((‘127.0.0.1‘, 8080))
while True:
cmd = input(">>>>").strip()
if not cmd:
continue
phone.send(cmd.encode(‘utf-8‘))
dahler_len = struct.unpack(‘i‘, phone.recv(4))[0] # 先接收报头长度
dahler_bytes = phone.recv(dahler_len) # 在接收bytes类型的字典
dahler_str = dahler_bytes.decode(‘utf-8‘)
dahler_dic = json.loads(dahler_str) # 把bytes类型的字典转换成字典,通过字典拿到自己想要的
total_size = dahler_dic[‘total_size‘] # 接受的文件总大小
recv_size = 0 # 接收默认值 为0
res = b‘‘ # 拼接
while recv_size < total_size: # 结束条件
data = phone.recv(1024)
res += data
recv_size += len(data)
print(res.decode(‘gbk‘))
import socket
import subprocess
import struct
import json
phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 建立服务器
phone.getsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
phone.bind((‘127.0.0.1‘, 8080)) # 绑定IP,port
phone.listen(5) # 监听状态
while True:
conn, client_addr = phone.accept() # 接发数据
while True:
try:
data = conn.recv(1024) # 读收到的文件 最大限制为1024字节
if len(data) == 0:
break
print(data)
boj = subprocess.Popen(
data.decode(‘utf-8‘),
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
stdout_res = boj.stdout.read()
stderr_res = boj.stderr.read()
total_size = len(stderr_res)+len(stdout_res)
haderl_dic = {
‘file‘: ‘a.txt‘,
‘total_size‘: total_size,
‘hashlib‘: ‘adasd1dfad311r‘
}
haderl_str = json.dumps(haderl_dic) # 用json把字典转换成一个字典形式的字符串
haderl_bytes = haderl_str.encode(‘utf-8‘) # 把字符串转换成二进制
conn.send(struct.pack(‘i‘, len(haderl_str))) # 先发报头长度
conn.send(haderl_bytes) # 再发报头字典
conn.send(stderr_res) # 在发内容
conn.send(stdout_res)
except ConnectionResetError as e:
print(e)
break
conn.close()操作系统(现代操作系统):
操作系统是位于计算机硬件于软件之间的控制程序
作用:
1、将硬件的复杂操作封装成简单的接口,给用户或者应用程序使用
2、将多个应用程序对硬件的竞争变的有序
进程
一个正在运行的程序,或者说是一个程序的运行过程
串行、并发、并行
串行:一个任务完完整运行完毕,才执行下一个
并发:多个任务看起来是同时运行的,单核就可以实现并发
并行:多个任务是真正意义上的同时运行,只有多核才能实现并行
多道技术
背景:想要再单核下实现并发(单核同一时刻只能执行一个任务(每起一个进程就会产生一把GIL全局解释器锁))
并发实现的本质就:切换+保存状态
多道技术:
1、空间上的复用=》多个任务共用一个内存条,但占用内存是彼此隔离的,而且是物理层面隔离的
2、时间上的复用=》多个任务共用同一个cpu
切换:
1、遇到io切换
2、一个任务占用cpu时间过长,或者有另外一个优先级更高的任务抢走的cpu
from multiprocessing import Process
def task(x):
print(‘%s is running‘ %x)
time.sleep(3)
print(‘%s is done‘ %x)
if __name__ == ‘__main__‘:
# Process(target=task,kwargs={‘x‘:‘子进程‘})
p=Process(target=task,args=(‘子进程‘,)) # 如果args=(),括号内只有一个参数,一定记住加逗号
p.start() # 只是在操作系统发送一个开启子进程的信号
print(‘主‘)
# 导入from multiprocessing import Process
# 相当于在windows系统中调用了CreateProcess接口
# CreateProcess既处理进程的创建,也负责把正确的程序装入新进程。
# p.start() # 只是在操作系统发送一个开启子进程的信号from multiprocessing import Process
import time
class Myprocess(Process):
def __init__(self,x):
super().__init__()
self.name=x
def run(self):
print(‘%s is running‘ %self.name)
time.sleep(3)
print(‘%s is done‘ %self.name)
if __name__ == ‘__main__‘:
p=Myprocess(‘子进程1‘)
p.start() #p.run()
print(‘主‘)from multiprocessing import Process
import time
x = 100
def task():
global x
x = 0
print(‘done‘)
if __name__ == ‘__main__‘:
p = Process(target=task)
p.start()
time.sleep(500) # 让父进程在原地等待,等了500s后,才执行下一行代码
print(x)join:
让父进程在原地等待,等到子进程运行完毕后(会触发wait功能,将子进程回收掉),才执行下一行代码
current_process().name:
导入from multiprocessing import Process,current_process
查看子进程的名字
from multiprocessing import Process,current_process
import time
def task():
print(‘子进程[%s]运行。。。。‘ %current_process().name)
time.sleep(2)
if __name__ == ‘__main__‘:
p1=Process(target=task,name=‘子进程1‘)
p1.start()
# print(p1.is_alive())
# p1.join()
# print(p1.is_alive())
p1.terminate() # 终止进程,应用程序给操作系统发送信号,让操作系统把这个子程序干掉
# 至于多久能干死,在于操作系统什么时候执行这个指令
time.sleep(1)
print(p1.is_alive()) # 查看子进程是否存在,有返回值. True则存在,False则不存在
print(‘主‘)标签:工作效率 结束 %x bytes dns sea net 序列 形式
原文地址:http://blog.51cto.com/13764714/2153330