标签:deletion 简单 name apr tools 伪分布式 group ima 编辑
什么是hadoop?
Hadoop是Apache开源的,可靠的,可扩展的一个项目;
1、海量数据的存储(hdfs)
2、海量数据的分析(MapReduce)
3、资源管理调度(YARN)
1、Hadoop子项目家族成员:
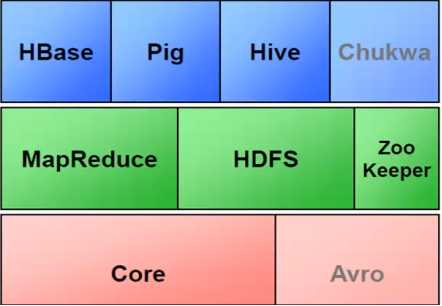
2、修改主机名:
[root@localhost ~]# hostname hadoop
3、配置ssh,生成密钥对:
[root@hadoop conf]# cd
[root@hadoop ~]# ssh-keygen -t rsa
[root@hadoop ~]# cd .ssh
[root@hadoop .ssh]# ls
id_rsa id_rsa.pub ##id_rsa是私钥,id_rsa.pub是公钥;
[root@hadoop .ssh]# ssh-copy-id -i ./id_rsa.pub root@10.10.10.30 ##拷贝公钥到需要认证的服务器上去;
测试连接:
[root@hadoop ~]# ssh root@10.10.10.30
Last login: Wed Nov 9 21:43:43 2016 from 10.10.10.20
[root@hadoop ~]# cd .ssh/
[root@hadoop .ssh]# ls
authorized_keys ##拷贝过来的公钥变了名字;
注意:配置免密码连接的配置每台服务器上的root用户和hadoop用户都要操作;
4、下载及安装伪分布式:
1)登录网址:http://mirrors.aliyun.com/apache/hadoop/common/ 下载hadoop安装包,hadoop-2.7.3.tar.gz
2)http://pan.baidu.com/share/link?shareid=2793927523&uk=1678158691&fid=117337971851932 下载jdk插件;
3)安装Hadoop前要先安装jdk插件:
[root@hadoop tools]# tar xf jdk-7u79-linux-x64.tar.gz -C /data ##解压下载包; [root@hadoop tools]# vim /etc/profile ##编辑/etc/profile文件,在最下面添加如下四条: export JAVA_HOME=/data/jdk1.7.0_79 export JRE_HOME=/data/jdk1.7.0_79/jre export PATH=/data/jdk1.7.0_79/bin:$PATH exportCLASSPATH=./:/data/jdk1.7.0_79/lib:/data/jdk1.7.0_79/lib [root@hadoop tools]# . /etc/profile ##使/etc/profile文件生效; [root@hadoop tools]# java -version ##查看安装情况及版本; java version "1.7.0_79" Java(TM) SE Runtime Environment (build 1.7.0_79-b15) Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode) 安装jdk完成;
4)解压hadoop软件并配置:

[root@hadoop tools]# tar xf hadoop-2.7.3.tar.gz -C /data ##解压hadoop; [root@hadoop tools]# cd /data/hadoop-2.7.3/etc/hadoop ##cd到配置目录下面去; [root@hadoop hadoop]# vim hadoop-env.sh ##编辑其中一个配置文件; export JAVA_HOME=/data/jdk1.7.0_79 ##最下面添加;
[root@hadoop hadoop]# vim core-site.xml ##编辑第二个重要的文件,添加红色的部分; <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop1/tools/data/</value> ##data目录要单独创建; </property> </configuration>
[root@hadoop hadoop]# vim hdfs-site.xml 编辑第三个重要的配置文件 <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
[root@hadoop hadoop]# vim mapred-site.xml ##编辑第四个重要的文件,添加红色的内容; <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
[root@hadoop hadoop]# vim yarn-site.xml 编辑第五个配置文件,添加红色的内容; <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
5)配置hadoop的环境变量:
[root@hadoop hadoop]# vim /etc/profile ## ##hadoop export HADOOP_HOME=/data/hadoop-2.7.3 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
6)启动程序:
[root@hadoop hadoop]# start-dfs.sh ##启动hdfs [root@hadoop hadoop]# start-yarn.sh ##启动yarn [root@hadoop hadoop]# Jps ##查看java进程; 41188 NameNode 41274 DataNode 41539 SecondaryNameNode 42015 Jps 41799 NodeManager 41710 ResourceManager
7)测试:
(1)通过网页登录:输入:http://ip:50070
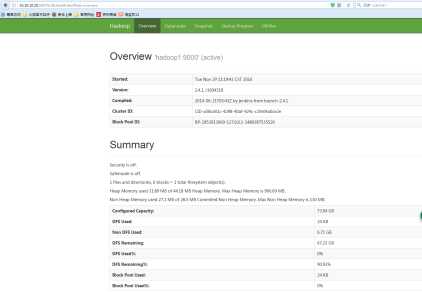
(2)上传文件测试:
hadoop fs -put jdk-7u79-linux-x64.tar.gz hdfs://ip:9000/
在浏览器上查看:

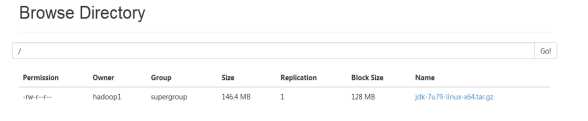
(3)测试mapreduce:
hadoop fs -mkdir /wordcount hadoop fs -mkdir /wordcount/input ##创建两个目录;
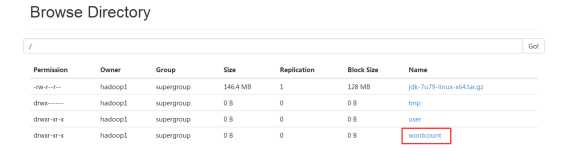
hadoop fs -put test.txt /wordcount/input ##上传文件;
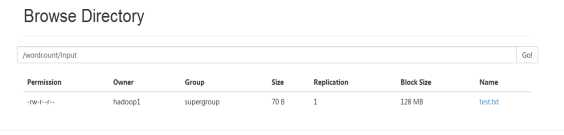
hadoop jar hadoop-mapreduce-examples-2.4.1.jar wordcount /wordcount/input /wordcount/output ##执行这条命令会输出一下信息;
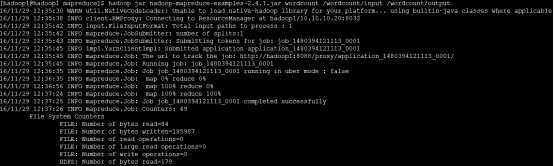
hadoop fs -ls /wordcount/output ##查看是否执行成功,成功的会多多出下面两个文件; Found 2 items -rw-r--r-- 1 hadoop supergroup 0 2016-11-29 12:37 /wordcount/output/_SUCCESS -rw-r--r-- 1 hadoop supergroup 54 2016-11-29 12:37 /wordcount/output/part-r-00000
hadoop fs -cat /wordcount/output/part-r-00000 ##显示刚才创建的文件的内容信息; dasdasxccdf 1 fdfsfsfs 1 hallow 5 sss 1 world 1 www 1
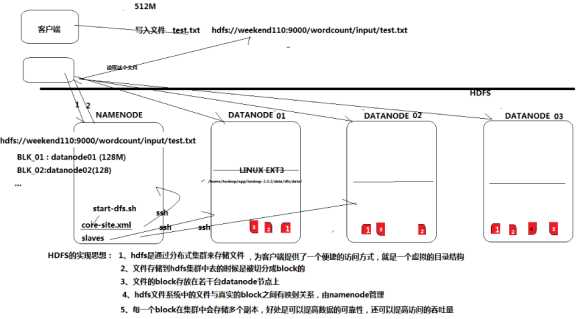
1、hdfs是通过分布式集群来存取文件的,为客户端提供了一个便捷的访问方式,就是一个虚拟的目录结构;
2、文件存储到hdfs集群中去的时候是被切分成block的;
3、文件的block存放在若干台datanode节点上;
4、Hdfs文件系统中的文件与真实的block之间有映射关系,由namenode管理;
5、每一个block在集群会存储多个副本,好处是可以提高数据的可靠性,还可以提高访问的吞吐量;
Hadoop简单命令操作:
(1)设置权限:
hadoop fs -chown hadoop:hadoop /jdk-7u79-linux-x64.tar.gz ##设置属组权限; hadoop fs -ls / ##查看结果 -rw-r--r-- 1 hadoop hadoop 153512879 2016-11-29 11:36 /jdk-7u79-linux-x64.tar.gz hadoop fs -chmod 777 /jdk-7u79-linux-x64.tar.gz ##设置权限 hadoop fs -ls / ##查看结果; -rwxrwxrwx 1 hadoop hadoop 153512879 2016-11-29 11:36 /jdk-7u79-linux-x64.tar.gz
(2)拷贝文件:
hadoop fs -copyFromLocal hadoop-mapreduce-client-app-2.4.1.jar / ##拷贝文件到根下去; hadoop fs -ls / ##查看结果; Found 5 items -rw-r--r-- 1 hadoop supergroup 487973 2016-11-30 07:06 /hadoop-mapreduce-client-app-2.4.1.jar hadoop fs -cp /hadoop-mapreduce-client-app-2.4.1.jar /wordcount ##拷贝这个文件到这个目录下去; hadoop fs -ls /wordcount ##查看结果; Found 3 items -rw-r--r-- 1 hadoop supergroup 487973 2016-11-30 07:23 /wordcount/hadoop-mapreduce-client-app-2.4.1.jar
(3)查看空间的大小和文件大小:
hadoop fs -df -h / ##查看根目录的大小和使用情况; Filesystem Size Used Available Use% hdfs://hadoop1:9000 73.9 G 149.9 M 66.5 G 0% hadoop fs -du -h / ##统计根下面的每个目录或文件的大小; 476.5 K /hadoop-mapreduce-client-app-2.4.1.jar 146.4 M /jdk-7u79-linux-x64.tar.gz 1.1 M /tmp 2.1 K /user 476.7 K /wordcount
(4)创建目录:
hadoop fs -mkdir /xyp ##创建目录; hadoop fs -ls / ##查看结果; Found 6 items drwxr-xr-x - hadoop supergroup 0 2016-11-30 07:39 /xyp
(5)删除目录或文件:
hadoop fs -rm -r /xyp ##删除目录; 16/11/30 07:41:58 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted /xyp hadoop fs -ls / ##查看结果 Found 5 items -rw-r--r-- 1 hadoop supergroup 487973 2016-11-30 07:06 /hadoop-mapreduce-client-app-2.4.1.jar -rwxrwxrwx 1 hadoop hadoop 153512879 2016-11-29 11:36 /jdk-7u79-linux-x64.tar.gz drwx------ - hadoop supergroup 0 2016-11-29 12:05 /tmp drwxr-xr-x - hadoop supergroup 0 2016-11-29 12:05 /user drwxr-xr-x - hadoop supergroup 0 2016-11-30 07:23 /wordcount
标签:deletion 简单 name apr tools 伪分布式 group ima 编辑
原文地址:https://www.cnblogs.com/xyp-blog123/p/9403411.html
